K-means聚类算法注释
我也不会写,就注释一下下,希望各位大佬宽容一下我这个“水货”,谢谢
from numpy import *
# 数据的预处理
def loadDataSet(fileName):
dataMat = [] # 创建一个列表
fr = open(fileName) # 打开数据文本文件
for line in fr.readlines(): # 逐行读取
# split('\t')指定分给符对数据进行切割; strip(rm) 默认删除空白符:\t \n \r and 空格
curLine = line.strip().split('\t')
fltLine = list(map(float, curLine)) # map作用:将函数float作用于curLine,并返回一个数组
dataMat.append(fltLine) # 将处理的数据依次加入到列表中
return dataMat
# 计算两个点之间的欧式距离
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, 2))) # (vecA-vecB)的乘方
# 初始化随机中心
# 函数参数:dataset:数据集;k:质心的个数
def randCent(dataSet, k):
n = shape(dataSet)[1] # 获取数据长度:列
centroids = mat(zeros((k, n))) # 初始化一个zeros参数是(k*n)元组的零矩阵
for j in range(n): #j从0到n取值
minJ = min(dataSet[:, j]) # 取J列中的所有行元素,并得到J列所有行的最小值
rangeJ = float( max(dataSet[:, j]) - minJ) # float从j列所有行元素中选取最大值-最小值并将类型转换为
centroids[:, j] = mat(minJ + rangeJ * random.rand(k, 1)) # 构建簇的质心
return centroids # 返回这个簇矩阵
#K均值聚类算法
# 参数:
# dataSet:数据集
# k:质心数量==簇数量
# distMeas:两个点之间的欧氏距离
# createCent:初始化质点的中心
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = shape(dataSet)[0] # 获取数据长度:行数
clusterAssment = mat(zeros((m,2))) # 初始化一个m行2列的矩阵
centroids = createCent(dataSet, k) # 初始化质心
clusterChanged = True # 设置点的状态
while clusterChanged: # 在点状态改变条件为真的情况下运行
clusterChanged = False # 弱点的状态发生一次改变后,程序在执行完后面语句时退出循环
for i in range(m): # 在数据长度 m 下遍历
minDist = inf # 初始化点间最小距离为正无穷大
minIndex = -1 # 初始化点间关系为无
for j in range(k): # 循环遍历质心数
distJI = distMeas(centroids[j,:],dataSet[i,:]) # 计算计算数据点和随机质心之间的欧式距离
if distJI < minDist: # 如果欧式距离小于设置的初始值
minDist = distJI # 那么更改最小距离为欧式距离
minIndex = j # 更改该点所在簇位置为j,即将该点放入以j为质心的簇中
if clusterAssment[i,0] != minIndex: # 如果说这个点不是这个类
clusterChanged = True # 那么该点的状态不变
clusterAssment[i,:] = minIndex,minDist**2 # 对处于i位置的点的信息进行更新:所属簇类,最小距离的平方值
print(centroids) #
# 更新质心的位置
for cent in range(k):
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]
centroids[cent,:] = mean(ptsInClust, axis=0)
return centroids, clusterAssment
#二分k均值聚类算法
def biKmeans(dataSet, k, distMeas=distEclud):
m = shape(dataSet)[0] # 获取数据行数
clusterAssment = mat(zeros((m,2))) # 初始化一个 (m*2)的矩阵
centroid0 = mean(dataSet, axis=0).tolist()[0] # #创建一个初始聚类--所有的数据点作为一个大类
centList =[centroid0] # 初始化一个质心列表
for j in range(m): # 循环更新每一个点的信息:质心和每个点的距离平方
clusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2
while (len(centList) < k): # 在二分簇个数小于划分的簇个数时循环:
lowestSSE = inf # 初始化误差值为无穷大
for i in range(len(centList)):
ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:] # 在当前类 i 中得到一个数据点
centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas) # 递归划分数据簇类
sseSplit = sum(splitClustAss[:,1]) # 得到两个划分的SSE的和
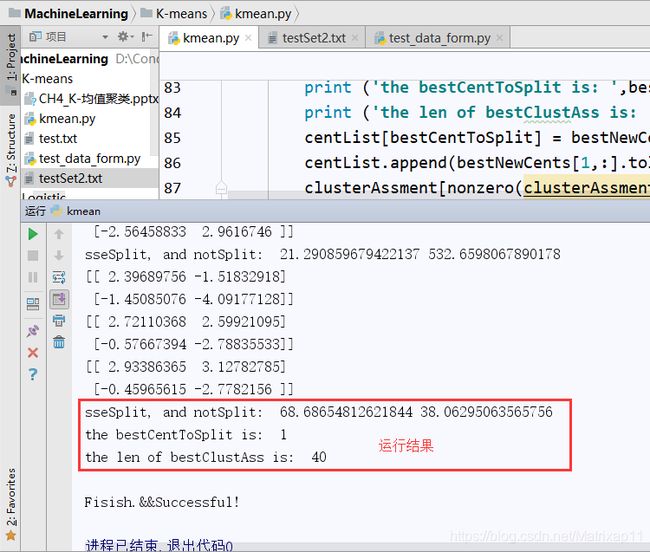
sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1]) # 未划分的数据的误差和
print ("sseSplit, and notSplit: ",sseSplit,sseNotSplit) # 打印误差值
# 这些误差与剩余误差的误差值之和作为本次划分的误差
if (sseSplit + sseNotSplit) < lowestSSE: # 如果经过一个划分后的误差小于最小误差
bestCentToSplit = i # 更新簇的类别
bestNewCents = centroidMat # 簇中心的更新
bestClustAss = splitClustAss.copy() # 数据集的拷贝
lowestSSE = sseSplit + sseNotSplit # 更新最小误差
bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList) #change 1 to 3,4, or whatever
bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit # 最好的簇个数
print ('the bestCentToSplit is: ',bestCentToSplit) #
print ('the len of bestClustAss is: ', len(bestClustAss)) # 最好簇的点数
centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0]#replace a centroid with two best centroids
centList.append(bestNewCents[1,:].tolist()[0])
clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:]= bestClustAss#reassign new clusters, and SSE
return mat(centList), clusterAssment # 返回二分聚类后的质心矩阵和数据点的所属簇
# 普通聚类算法
print('k-means聚类:')
dataMat=mat(loadDataSet('testSet2.txt'))
mycentroids,clustAssing = kMeans(dataMat,4)
# 二分聚类算法
print('k-means二分聚类:')
dataMat2=mat(loadDataSet('testSet2.txt'))
centList,myNewAssments=biKmeans(dataMat2,3)
print('\n'+'Fisish.&&Successful!')
数据运行结果:
数据集:
3.275154 2.957587
-3.344465 2.603513
0.355083 -3.376585
1.852435 3.547351
-2.078973 2.552013
-0.993756 -0.884433
2.682252 4.007573
-3.087776 2.878713
-1.565978 -1.256985
2.441611 0.444826
-0.659487 3.111284
-0.459601 -2.618005
2.177680 2.387793
-2.920969 2.917485
-0.028814 -4.168078
3.625746 2.119041
-3.912363 1.325108
-0.551694 -2.814223
2.855808 3.483301
-3.594448 2.856651
0.421993 -2.372646
1.650821 3.407572
-2.082902 3.384412
-0.718809 -2.492514
4.513623 3.841029
-4.822011 4.607049
-0.656297 -1.449872
1.919901 4.439368
-3.287749 3.918836
-1.576936 -2.977622
3.598143 1.975970
-3.977329 4.900932
-1.791080 -2.184517
3.914654 3.559303
-1.910108 4.166946
-1.226597 -3.317889
1.148946 3.345138
-2.113864 3.548172
0.845762 -3.589788
2.629062 3.535831
-1.640717 2.990517
-1.881012 -2.485405
4.606999 3.510312
-4.366462 4.023316
0.765015 -3.001270
3.121904 2.173988
-4.025139 4.652310
-0.559558 -3.840539
4.376754 4.863579
-1.874308 4.032237
-0.089337 -3.026809
3.997787 2.518662
-3.082978 2.884822
0.845235 -3.454465
1.327224 3.358778
-2.889949 3.596178
-0.966018 -2.839827
2.960769 3.079555
-3.275518 1.577068
0.639276 -3.412840