Generative Image Inpainting with Contextual Attention
1. Motivation
- 传统方法要求图像之中的patch之间存在相似性;
- 卷积神经网络不能有效的从图像较远的区域提取信息。
2. Approach
2.1 Network architecture
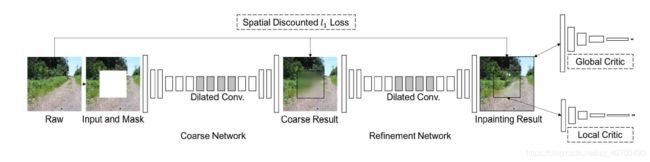 Overview of our improved generative inpainting framework.
Overview of our improved generative inpainting framework.
- 生成器:包括两个网络,一个粗糙网络,一个改良网络,粗糙网络用重构损失训练,改良网络重构损失和 GAN的损失训练;
- 判别器:两个,一个局部,一个整体,都是基于 WGAN-GP【1】。
- 上下文注意力机制:
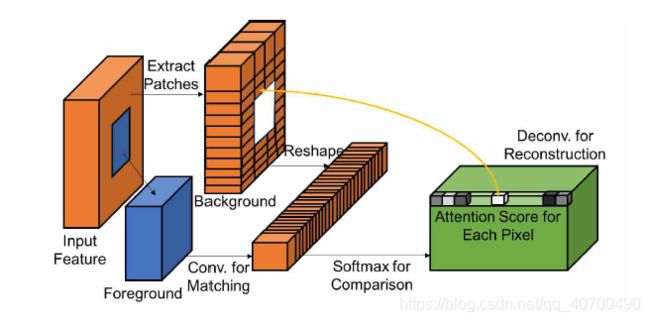
首先在背景区域提取3x3的patch,并作为卷积核。为了匹配前景(待修复区域)patch,使用标准化内积(即余弦相似度)来测量,然后用softmax来为每个背景中的patch计算权值,最后选取出一个最好的patch,并反卷积出前景区域。对于反卷积过程中的重叠区域取平均值。
2.2 Loss function
- WGAN损失:
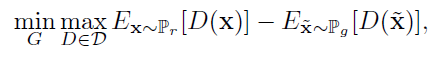
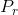 是真实的分布,
是真实的分布, 是生成数据的分布,这个损失和GAN的初始损失是不相同的;
是生成数据的分布,这个损失和GAN的初始损失是不相同的;
- 梯度惩罚项:
![]()
![]()
![]()
只要位于空洞区域的像素点,
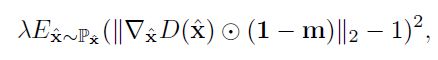
- 重构损失:
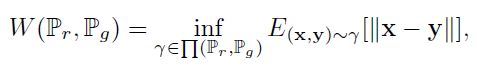
- 空间衰减重构损失:
改变重构损失的 mask权重,每一点的权值为![]() ,
,![]() ,
, 表示该点到已知的像素点最近的距离。
表示该点到已知的像素点最近的距离。
- 源代码:
判别器损失:
losses['d'] = losses['wgan_d'] + losses['wgan_gp'] * config['wgan_gp_lambda']
losses['wgan_d'] = torch.mean(local_patch_fake_pred - local_patch_real_pred) + \
torch.mean(global_fake_pred - global_real_pred) * self.config['global_wgan_loss_alpha']
local_penalty = self.calc_gradient_penalty(
self.localD, local_patch_gt, local_patch_x2_inpaint.detach())
global_penalty = self.calc_gradient_penalty(self.globalD, ground_truth, x2_inpaint.detach())
losses['wgan_gp'] = local_penalty + global_penalty判别器损失包括两项:WGAN的损失 losses['wgan_d'] ,梯度惩罚项 losses['wgan_gp'],全局判别器的惩罚项 global_penalty 和局部判别器的惩罚项 local_penalty。
生成器损失:
losses['g'] = losses['l1'] * config['l1_loss_alpha'] \
+ losses['ae'] * config['ae_loss_alpha'] \
+ losses['wgan_g'] * config['gan_loss_alpha']
sd_mask = spatial_discounting_mask(self.config)
losses['l1'] = l1_loss(local_patch_x1_inpaint * sd_mask, local_patch_gt * sd_mask) * \
self.config['coarse_l1_alpha'] + \
l1_loss(local_patch_x2_inpaint * sd_mask, local_patch_gt * sd_mask)
losses['ae'] = l1_loss(x1 * (1. - masks), ground_truth * (1. - masks)) * \
self.config['coarse_l1_alpha'] + \
l1_loss(x2 * (1. - masks), ground_truth * (1. - masks))
local_patch_real_pred, local_patch_fake_pred = self.dis_forward(
self.localD, local_patch_gt, local_patch_x2_inpaint)
global_real_pred, global_fake_pred = self.dis_forward(
self.globalD, ground_truth, x2_inpaint)
losses['wgan_g'] = - torch.mean(local_patch_fake_pred) - \
torch.mean(global_fake_pred) * self.config['global_wgan_loss_alpha']losses['l1'] 是空间衰减重构损失,sd_mask 就是空间衰减后的 mask,local_patch_x1_inpaint 粗糙网络的输出,local_patch_x2_inpaint 改进网络的输出;
losses['ae'] 重构损失,粗糙网络的重构损失与改进网络的重构损失加权结果;
losses['wgan_g'] WGAN的损失;
losses['g'] 是生成器的损失,是各种损失的加权和。
3. Disscussion
我认为本文的主要创新点就是上下文注意力机制,通过将已知区域作为卷积核进行卷积操作,充分利用了远距离区域的信息,以达到更好的修复效果。
源代码:https://github.com/daa233/generative-inpainting-pytorch
4. References
【1】Gulrajani, Ishaan, et al. "Improved training of wasserstein gans." Advances in neural information processing systems. 2017.
【2】Yu, Jiahui, et al. "Generative image inpainting with contextual attention." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.