shell浅谈之七文本处理工具grep、sed、awk
一、简介
Bash Shell提供了功能强大的文件处理工具:sed(流编辑器stream editor)和awk,都可使用正则表达式进行模式匹配。而grep又有助于理解sed和awk。
二、grep命令
grep(Globel search Regular Expression and Print out the line)全面搜索正则表达式并把行打印出来,它是一种强大的文本搜索工具,与正则表达式结合使用。
1、格式选项
grep格式:grep [选项] [模式] [文件...],它在一个或多个文件中搜索满足模式的文本行,grep的选项如下:
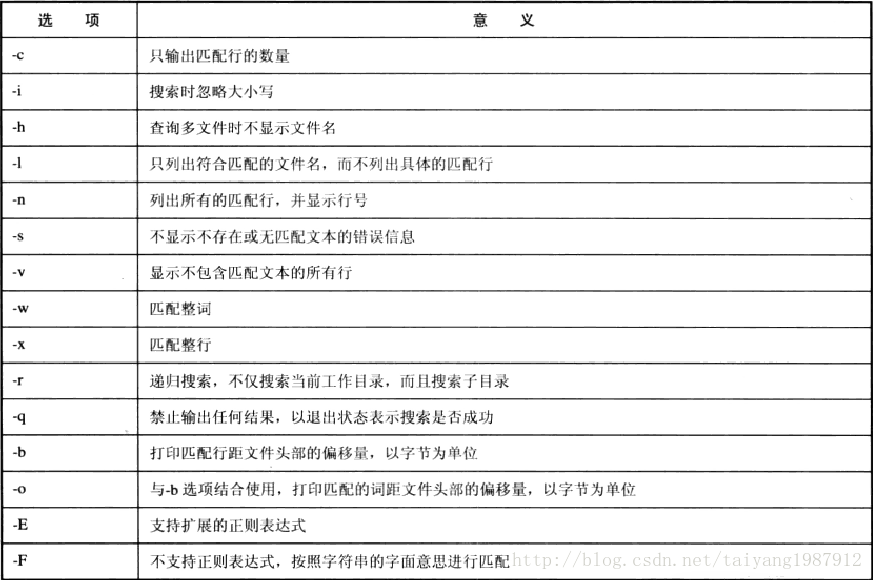
grep命令模式可以是字符串、变量或正则表达式,grep支持多文件查询如grep pattern a.txt b.txt,grep指定多个文件时可以使用通配如grep pattern ?.txt,查找a.txt、b.txt等单个字符开头的txt文件。
(1)-c选项
输出匹配字符串行的数量,默认grep打印包含模式的所有行,加上-c就只显示包含模式行的数量。如grep -c pattern *.txt。
(2)-n选项
列出所有的匹配行,并显示行号,默认grep搜索单个文件只显示每行内容,搜索多个文件显示文件名及每行内容,加上-n将在内容前附加显示行号(查询中比较有用)。
(3)-v选项
显示不包含模式的所有行,常与-c选项配合显示不包含模式的行数。
(4)-h选项
默认下grep命令查询多个文件时,在匹配行之前显示文件名,加上-h选项,grep将不再显示文件名。
(5)-r选项
默认情况,grep只对当前目录下的文件进行搜索,而不对子目录中的文件进行搜索。-r表示递归搜索,不仅搜索当前目录而且搜索子目录。比较有用。
(6)-w和-x选项
grep命令支持正则表达式,正则表达式的元字符被解释成特殊的含义,-w选项使元字符不再被解释为特殊含义。例如:grep patt* a.txt,未加-w模式中的*被解析成任意字符,加上-w只搜索包含patt*字符串的文本行。
-x选项是匹配整行,文件中整行内容与模式匹配时才输出,只有部分内容匹配也不输出。
2、grep与正则表达式结合
(1)匹配行首元字符"^"表示行首,^$表空白行,[^$]表示空白行的范围,前面加上"^"符号取反^[^$]表示非空白行。
(2)匹配重复字符
匹配重复字符通常可以利用"."符号表示一个任意字符和"*"符号表示任意个任意字符来实现,不是正则表达式的规则。
(3)转义符
匹配的目标字符串中包含元字符,需要利用转移符"\"屏蔽其意义,如grep "com\.con" *,句号"."字符是元字符,需要在之前加上转移符进行转义。
横杠(-)字符比较特殊,它虽不属于元字符,但grep命名是由"-"字符引出的特殊字符,因此需要用转移符将其转义。
(4)POSIX字符类
为了保持不同国家的字符编码一致性,POSIX增加了特殊的字符类,grep支持POSIX字符类。


[:upper:]表示大写字母集合,[[:upper:]]表示匹配字符集合,grep ^[[:upper:]] a.txt,搜索以大写字母开头的文本行;grep ^[[:space:]] a.txt,搜索以空格开头的文本行。
(5)精确匹配
\<\>符号用于精确匹配,grep "\
(6)或字符
或字符"|"是扩展正则表达式中定义的,grep需要加上-E选项才能支持它,不带-E选项,会将"|"字符解析为字面意义。
3、egrep和fgrep
(1)grep命令族:grep(支持基本正则表达式)、egrep(等价grep -E)(扩展grep命令,支持基本和扩展正则表达式)、fgrep (等价grep -F)(快速grep命令,不支持正则表达式,按字符串的字面意思进行匹配)。(2)egrep "^-+B" a.txt,查找以"-"开头且至少重复一次然后加B字符的字符串,"+"至少重复一次,"*"重复0次或无数次。
(3)grep命令功能十分强大,以代替egrep和fgrep命令。
三、sed命令
sed是一个非交互式的文本编辑器,可对文本文件和标准输入进行编辑,sed只是对缓冲区中原始文件的副本进行编辑,并不编辑原始的文件,若需要保存改动内容则需要重定向到另一个文件。sed使用于:编辑相对交互式文本编辑器而言太大的文件、编辑命令复杂在交互式下难输入、对文件扫描一次但需执行多个编辑函数的情况。
1、sed命令基本用法
(1)调用sed方式一:在shell命令行调用sed,格式为:sed [选项] 'sed命令' 输入文件。
方式二:将sed命令插入脚本后,然后通过sed命令调用它,格式为:sed [选项] -f sed脚本文件 输入文件。
方式三:将sed命令插入脚本后,执行改脚本,格式为:./sed脚本文件 输入文件。

sed的-n选项,sed编辑命令p实现打印匹配行功能,-n表示不打印sed编辑对象的全部内容,例如:sed '1p' string.txt,不仅打印第一行数据,而且然后将string.txt的全部内容打印到标准输出;sed -n '1p' string.txt仅打印第一行内容;sed -n '3,6p' string.txt打印3~6行数据;sed -n '/pattern/p' string.txt打印匹配模式行。
sed的-e选项,将下一个字符串解析为sed编辑命令,若只传递一个编辑命令给sed,-e可省略。例如:需要将匹配pattern关键字的内容和行号都打印出来,就要想sed传递"p"和"="两个编辑命令,sed -n -e '/pattern/p' -e '/pattern/=' string.txt,带多个编辑命令的sed格式只能是:sed [选项] -e 编辑命令1 -e编辑命令2 ... -e 编辑命令n 输入文件。
sed的-f选项,只有在调用sed脚本文件时才起作用。其中先介绍sed编辑命令a\符号用于追加文本,sed '指定地址a\text' 输入文件,例如sed '/file:/a\append data.' string.txt,匹配模式file:字符串然后在其行后追加文本内容append data.追加文本只是输出到标准输出上,原始文件未改变。接着编写sed脚本文件,新建append.sed的文件
#!/bin/sed -f
/file:/a\
append data.\
another line.
执行脚本,需加上输入文件的名称,./append.sed string.txt。
(2)sed命令通常由定位文件行和sed编辑命令两部分组成,sed编辑命令对定位文本行进行各种处理。
sed定位文本方法:

(3)sed编辑命令标识对文本进行各种处理,如打印、删除、追加、插入、替换等。sed的基本编辑命令可以放在单引号内也可以放在单引号外。


2、sed文本定位
(1)匹配元字符若sed命令所要匹配的目标字符串中包含元字符,需要使用转义符"\"屏蔽其特殊意义。例如sed -n '/\$/p' string.txt匹配$符号。
(2)使用元字符进行匹配
$在正则表达式中表示行尾,在sed命令中却表示最后一行,例如sed -n '$p' string.txt匹配最后一行。
(3)!符号
!符号表示取反,x,y!表示匹配不在x和y行号范围内的行,sed -n '2,10!p' string.txt表示不打印2~10之间的行。
(4)使用行号与关键字匹配限定行范围
/pattern/,x和x,/pattern/两种形式限定行号与关键字匹配行之间的范围,与x,y是一样的,只是将x或y用/pattern/代替而已。例如sed -n '/pattern/,$p' string.txt表示文件string.txt从匹配pattern行到最后一行。
3、sed基本编辑命令
(1)插入文本
插入文本和追加文本类似,区别在于追加在匹配行后面插入,而插入文本是在匹配行的前面插入,插入文本的格式:sed '指定地址i\text' 输入文件,新建insert.sed脚本:
#!/bin/sed -f
/file:/i\
we insert a new line.
(2)修改文本
指将所匹配的文本行利用新文本代替,修改文本的格式为:sed '指定地址c\text' 输入文件,新建modify.sed的脚本:
#!/bin/sed -f
/file:/c\
we modify this line.
(3)删除文本
sed删除文本命令可以将指定行或指定行范围进行删除,删除格式:sed '指定地址d' string,d后面不带\符号,例如sed '2,$d' string.txt,删除第2行到最后一行。
(4)替换文本
sed替换文本操作将所匹配的文本行利用新文本替换,与修改文本功能类似,区别在于:替换文本可以替换一个字符串而修改文本是对整行进行修改。sed编辑命令的替换文本符号为s,格式为:s/被替换的字符串/新字符串/[替换选项]
sed -n 's/被替换的字符串/新字符串/p' 输入文件,只打印替换行。
g选项使得sed替换命令对某行的所有关键字都进行替换,只有被替换字符串所在行出现2次及其以上g选项才有用。sed替换命令还可指定替换第几次匹配的关键字,替换选项上加相应数字,数字在1~512之间。
w选项后加文件名表示将输出定向到这个文件,若输出文件未建立sed命令自动建立输出文件,默认目录是当前工作目录。例如sed -n 's/old/new/w output' input。
&符号可用来保存被替换的字符串以供调用,例如sed -n 's/seu/&.new/pg' string.txt等价于sed -n 's/seu/seu.new/pg' string.txt,都是使用seu.new替换seu,&符号保存了被替换字符串seu的值。
(5)写入一个新文件
要保存编辑结果,需将编辑后的文本重定向到另一个文件,sed写入文件的符号为w,格式为:指定地址 w 文件名,例如sed -n '1,5 w output' input,input文件中的1~5行写入output文件。sed -n '/pattern/w output' input,将匹配pattern模式的行写入文件。
(6)从文件中读入文本
sed命令还可将其他文件中的文本读入,并附加在指定地址,格式为:指定地址 r 文件名,例如sed '/pattern/r otherfile' input,在匹配pattern模式行的后面加上otherfile的所有内容。
(7)退出命令
sed命令的q选项表示完成指定地址的匹配后立即退出,格式为:指定地址 q,sed -n '/r*/p' input,匹配全部的字符串,sed -n ''/r*/q' input,匹配第1个字符串后立即退出。
(8)变换命令
sed命令的y选项表示字符变换,对字符的逐个处理,格式为:sed 'y/被变换的字符序列/变换的字符序列/' 输入文件,要求被变换的字符序列和变换的字符序列等长,例如sed 'y/12345/ABCDE/' input,将input文件中1变换A、2变换为B、3变换成C、4变换成D、5变换成E。
(9)显示控制字符
控制字符就是非打印字符,如退格键、F1键、Shift键等,sed 1显示文件中的控制字符,例如sed -n '1,$1' file,表示打印从第1行到最后一行的控制字符。
(10)在定位行执行命令组
sed编辑命令中的"{}"符号可以指定在定位行上所执行的命令组,它的作用与sed的-e选项类似,都是为了在定位行执行多个编辑命令。例如sed -n -e '/pattern/p' -e '/pattern/=' input与sed -n '/pattern/{p;=}' input等价。
4、sed高级编辑命令
(1)处理匹配行的下一行sed编辑命令n的意义是读取下一个输入行,用n后面的一个命令处理该行,例如sed '/pattern/{n;s/old/new/;}' input,即找出pattern关键字的匹配行,然后在匹配行的下一行执行s/old/new将下一行的old替换成new命令。
(2)sed缓冲区的处理
sed有两种缓冲区:模式缓冲区(Pattern Buffer)和保持缓冲区(Hold Buffer),sed的一些编辑命令可以对保持缓冲区进行处理,比与模式缓冲区的内容互换。例如sed -e '/Subject/h' -e '/seugrid/x' -e '$G' input,匹配Subject将此行保持缓冲区,接着匹配seugrid将此行写入保持缓冲区并将原来保持缓冲区的内容输出,最后到最后一行时输出保持缓冲区的内容。
(3)利用分号分隔多个编辑命令
除了使用上述-e和{}可以实现sed的多编辑命令,还可以利用分号(;)实现类似功能,格式为:sed '编辑命令1;编辑命令2;...' 输入文件,例如sed 's/globel/GLOBEL/; s/pattern/PATTERN/' input,完成两个替换操作,等价于-e命令引出的多个编辑命令。 也可在shell二级命令提示符下连续输入多条编辑命令。
四、awk命令
awk用来进行文本处理,可以从文件或字符串中基于指定规则浏览和抽取信息。awk是最难掌握的一种Shell文本处理工具,其中包含了太多的编程细节。首先要掌握awk语言的基本语法,在shell中熟练使用awk。最新的是gawk,awk实际上是/bin/gawk的链接。
1、awk编程模型
awk程序由一个主输入循环维持(awk已搭好主输入循环框架,代码一般被嵌到其中执行),主输入循环反复执行直到终止条件被触发。
awk定义了两个特殊的字符:BEGIN和END,BEGIN用于在主输入循环之前执行(即在未读取输入文件行之前执行),END刚好相反用在主输入循环之后执行(即在读取输入文件行完毕后执行)。简单地将awk编程模型分为三个阶段:

2、awk调用方法
调用awk的方法与sed类似,也有三种。方式一:shell命令行输入命令调用awk,格式为:awk [-F 域分隔符] 'awk程序段' 输入文件。方式二:将awk程序段插入脚本文件,然后通过awk命令调用它,格式为:awk -f awk脚本文件 输入文件。方式三:将sed命令插入脚本文件后,执行该脚本./awk脚本文件 输入文件(awk脚本仍以#!/bin/gawk符号开头)。
3、awk编程
(1)awk模式匹配
awk语句都由模式(pattern)和动作(action)组成。模式是一组用于测试输入行是否需要执行动作的规则,动作是包含语句、函数和表达式的执行过程。awk模式匹配需使用正则表达式,支持"?"和"+"两种扩展字符(grep和sed不支持)。
例如:awk '/^$/{print "This is blank."}' input,表示一旦读入文件行是空行就打印This is blank。awk由两部分组成,以/符号分隔,^$(是正则表达式是空白行)部分是模式;花括号部分是动作,是打印操作;input是文件名称。
awk第二种调用方式,新建source.awk输入/^$/{print "This is blank."},然后调用awk -f source.awk input。
awk第三种调用方式,vim source.awk
#!/bin/awk -f
/^$/{print "This is blank."}
然后执行./source.awk input。
(2)记录和域
awk认为输入文件是结构化的,awk定义域操作符$来指定执行动作的域,域操作符$后面跟数字或变量来标识域的位置,每条记录的域从1开始编号,$1表示第1个域,$2表示第2个域,$0表示所有的域。
例如awk '{print $1,$2}' file,打印指定域;awk -F“\t” '{print $0}' file,打印全部域,默认的分隔符是空格键,使用-F选项来改变分隔符(小写-f表示调用awk脚本),也可以在BEGIN字段中设置FS的值来改变分隔符,如awk 'BEGIN{FS=","} {print $0}' file。特殊的是对FS赋值FS="\t+"表示一个或多个Tab键作为分隔符。
域操作符$后面还可以跟变量,或者变量运算表达式,如awk 'BEGIN{one=1;two=2} {print $(one+two)}' file,BEGIN字段在遍历输入文件之前执行。
(3)关系和布尔表达式
awk定义了一组关系运算符用于awk模式匹配。

例:awk 'BEGIN {FS=":"} $1~/root/' /etc/passwd,打印/etc/passwd文件中第1个域匹配root关键字的记录;awk 'BEGIN {FS=":"} $0!~/root/' /etc/passwd,打印文件所有域不匹配root关键字的记录。
awk在进行模式匹配时,会用到条件语句if、if/else、if/else else三种语句,如awk 'BEGIN {FS=":"} {if($3<$4) print $0}' /etc/passwd,利用if语句匹配第3个域小于第4个域的记录。
为进行多条件模式匹配,awk定义了三个布尔运算符表示多条件之间的关系。

例awk 'BEGIN {FS=":"} {if($3==10 || $4==10) print $0}' /etc/passwd,查找满足条件$3==10或$4==10的记录。其中==进行的匹配称为精确匹配,若{if($3~10 || $4~10) print $0表示模糊匹配,查找包含10字符的记录。
(4)表达式
一个awk表达式可由数值、字符常量、变量、操作符、函数和正则表达式自由组合而成。表达式可进行变量和数字之间的算术操作。

例如awk '/^$/{print x+=1}' file,匹配空白行就输出空白行个数,等价于awk '/^$/{print x++}' file。
写名为source.awk的脚本用于计算student中每个学生的平均成绩,脚本内容为:
#!/bin/awk -f
BEGIN {FS=","}
{total=$4+$5+$6+$7+$8
avg=total/5
print $1,avg
}
执行脚本./source.awk student。
(5)系统变量
awk定义了很多内建变量用于设置环境信息,分为两种:一种用于改变awk的默认值,如域分隔符;一种用于定义系统值,在处理文本时可以读取这些系统值,如记录中的域数量、当前记录数、当前文件名等。awk环境变量意义如下:
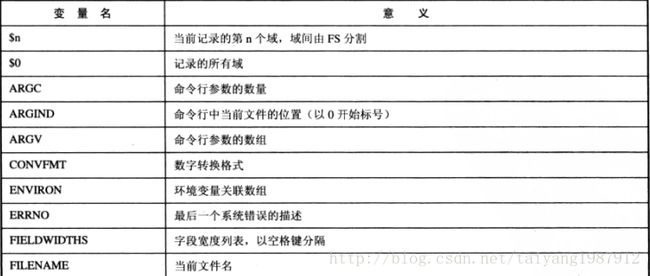

例awk 'BEGIN{FS=","} {print NF,FR,$0} END {print FILENAME}' file,NF为记录的域数量,NR显示当前的记录数,$0表示打印记录的所有域,END字段打印保存当前输入文件名的FILENAME。
(6)格式化输出
awk的一大主要功能是产生报表,报表就要按预定格式输出,awk定义了printf输出语句,规定了输出的格式。printf (格式控制符,参数),格式控制符以%符号开始,分为awk修饰符和格式符两种。


例如awk 'BEGIN {FS=","} {print("%s\t%d\n", $2, $8)}' file,从域号2和8获取相应的值。
例如awk 'BEGIN {FS=","} {printf("%-15s\t%s\n", $1, $3)}' file,-15表示该字符串长度控制为15位并且左对齐,如字符串不足15位则用空格补全,也可以在BEGIN字段中添加相应的输出注释,如awk 'BEGIN {FS=",";print "Name\t\tPhoneNumber"} {printf("%-10.3f\t%s\n", $1, $3)}' file。%-10.3表示浮点数长度控制在10位、小数点后保留3位,左对齐。
(7)内置字符串函数
awk提供了强大的内置字符串函数,用于实现文本的字符串替换、查找以及分隔等功能。

gsub有两种形式,第一种形式作用于全部域即$0,第二种形式作用于域t。例awk 'BEGIN {FS=":";OFS=":"} gsub(/root/, "gridsphere", $1) {print $0}' /etc/passwd,将第1个域上的字符串替换。
index返回第二个字符串在第一个字符串出现的首位置,length返回字符串的长度。如

match(s, t)测试s是否包含匹配t的字符串,t可以是一个正则表达式,匹配成功返回匹配t的首位置,不成功返回0。例awk 'BEGIN{IGNORECASE=1; print match("helloworld", /w/)}'忽略大小写匹配字符串w。
sub(r,s,t)将t中第1次出现的r替换为s(r可为正则表达式),substr返回字符串的指定后缀awk 'BEGIN{str="code programming";print substr(str,6)},返回从第6个字符开始的后缀部分;substr(str, 6, 9),返回从第6个字符开始长度为9的后缀部分。
(8)awk脚本传递参数
awk脚本内的变量可以在命令行中进行赋值,实现向awk脚本传递参数,变量赋值放在脚本之后、输入文件之前。格式为:awk 脚本 parameter=value 输入文件。
例如:awk 'BEGIN {FS=","} {print NR, $0}' OFS="." file,每条记录前加上了行号(NR值),然后重新定义OFS改变输出域的分隔符。
命令行参数不能被BEGIN字段语句访问,即直到输入文件的第1行被读取时,命令行参数方才生效。原因是awk读到命令行参数的赋值语句时,并不清楚是一个命令行参数的赋值语句只是认为是一个无效的文件名,awk继续读取直到正确的输入文件名被解析才判定前面的语句是命令行参数的赋值语句。

上述命令在读到n=1这条赋值语句时,它将n=1作为输入文件名,该命令在读取n=1文件前执行BEGIN字段,此时n为空,因此打印一行空白行。接着该命令发现n=1并非有效的文件名继续读取到source.txt参数并发现source.txt是一个有效的文件名,进而将n=1解析为命令行参数赋值语句,打印满足n==1的语句。
(9)条件语句和循环语句
awk的条件语句if的语法:
if (条件表达式)
动作1
[else
动作2]
条件表达式可以包括算术、关系和布尔操作符。也可以使用"~"匹配符和正则表达式作为if语句的条件,例if (x ~ /[Hh]el?o/) print x。
awk的循环语句有三种:while、do while和for。
while(条件表达式)
动作
、
do
动作
while(条件表达式)
、
for(设置计数器初值;测试计数器;计数器变化)
动作
(10)数组
数组是用于存储一系列值的变量,可通过索引来访问数组的值,索引需要用中括号括起,格式为:array[index]=value。数组无须定义数组类型和大小而可以直接赋值后使用。
关联数组,指数组的索引可以是字符串也可以是数字,对每一个数组元素awk自动维护一对值:索引和数组元素值。关联数组的值无须以连续的地址进行存储。字符串和数字之间的差别是明显的,如array[9]不能指定到与array[09]相同的值。例awk 'BEGIN{data[10.15]="1200";CONVFMT="%d";printf("<%s>\n", data[10.15])}',利用CONVFMT系统变量将10.15转换成整数,data[10]就不能够取得1200了。
awk定义了一种for循环用来访问关联数组,语法如下:
for (variable in array)
do something with array[variable]
其中关键字in也可用在条件表达式中判断元素是否在数组中,index in array,如果array[index]存在返回1否则返回0。例awk 'BEGIN{data[10.15]="1200"; if ("10.15" in data) print "found element."} '。
split(r,s,t)函数将字符串以t为分隔符,将r字符串拆分为字符串数组,并存放在s中,返回值是split数组的大小。例awk 'BEGIN {print split("abc/def/xyz", str, "/")}',输出值为3。
新建array.awk脚本文件:
#!/bin/awk -f
BEGIN {FS=","}
{split($1, name, " ");
for(i in name) print name[i]}
执行脚本./array.awk filename,将输出name数组的所有内容。
awk系统变量中有两个变量是以数组形式提供的:ARGV和ENVIRON,ARGC是ARGV数组中元素的个数,从ARGV[0]开始到ARGV[ARGC-1]结束。新建名为argv.awk脚本,内容如下:
BEGIN { for(x=0;x
print ARGV[x]
print ARGC
}
shell中执行awk -f argv.awk xyz n=100 2014,有三个参数分别在ARGV[1]~ARGV[3]中,argc为4。
ENVIRON变量存储了Linux操作系统的环境变量,awk 'BEGIN {for (i in ENVIRON) print i "=" ENVIRON[i]}',显示当前系统所定义的环境变量,ENVIRON的索引是环境变量名,所以可以通过环境变量名直接得到其值,也可以通过ENVIRON数组改变环境变量的值如EVNIRON["PATH"]=/bin/gawk,其中环境变量名需要用双引号引起。
五、总结
(1)sed用于流编辑将一系列的编辑命令作用于缓冲区中输入文件的副本,awk最显著特点是处理结构化文件
(2)sed和awk与管道紧密结合,后续将加深理解。