Linux内核设计与实现-第三章 进程管理
他人关于Linux线程和进程的讨论
本章讨论Linux内核如何管理进程:
1. how they are enumerated(列举) within the kernel
2. how they are created
3. how they ultimately(最终,最后) die.
进程管理是所有操作系统最重要的部分
Process
1- 什么是进程?
进程是处于运行中的程序(A process is a program (object code stored on some media) in the midst of execution.)
但是,进程不仅仅是正在执行的程序代码。
进程,实际上,是运行程序代码形成的生命体。
2- 进程还包含了一系列资源:
- open files
- pending signals
- internal kernel data
- processor state
- a memory address space with one or more memory mappings
- one or more threads of execution
- a data section containing global variables.
3- threads是什么?包含了哪些内容?
threads是进程内部活动的实体。
每个线程包含:
1. a unique program counter
2. process stack
3. set of processor registers.
4- 内核调度的是单独的线程
Linux又唯一的threads的实现:这使得threads和process并没有什么不同。对于Linux, thread就是一种特殊的进程
5- 现代操作系统,进程提供了两种虚拟技术?各有什么用?
1. a virtualized processor
使进程以为是自己独占系统,尽管系统已经给上百个进程共享了处理器(chapter 4)
2. virtual memory
使进程认为自己可以分配和管理系统的所有memory(chapter12)
6- process和program的联系
- 程序本身不是进程
- process is an active program and related resources.
- two or more processes can exist that are executing the same program.
- two or more processes can exist that share various resources, such as open files or an address space.
7- fork、exec、clone作用
fork : 通过复制已经存在的进程来创建新进程
exec :创建新的地址空间,并加载program到该地址空间
clone : fork实际上使用clone实现的,clone能由调用者决定那些部分是parent和child共享的
8- exit、wait4作用
exit :中止进程并且释放资源
wait4 :父进程用于获取 已经结束的子进程 的状态,允许进程等待特定进程的结束。
9- 进程的僵尸状态
在进程exit后,进程将进入特殊的zombie state,该状态用于表示已经结束的进程,直到parent进程调用wait或者waitpid
Process Descriptor and the Task Structure
10- task list是什么?
kernel使用双向循环链表(task list)来存储process列表。
task list的每一项是process descriptor(进程描述符),类型是struct task_struct。定义在 linux/sched.h

保存了执行的程序需要的所有信息。
11- process descriptor:task_struct和thread_info是什么?
Thetask_struct structure is allocated via the slab allocator to provide object reuse and cache coloring (see Chapter 12).
task_struct 存在每个进程的内核栈的末端。
随着进程描述符由slab allocator动态创建,新的结构体struct thread_info被创建在栈底(定义在asm/thread_info.h)
结构体如下:
struct thread_info {
struct pcb_struct pcb; /* palcode state */
struct task_struct *task; /* main task structure */
//..........................
//省略暂时不需要的部分,具体请查看源代码
};
thread_info在栈的末尾,其中元素task是指针,指向实际的task_struct
12- kernel如何引用和操作task or process
task直接通过指向它们结构体task_struct的指针来引用。
大部分内核代码通过操作struct task_struct来处理进程工作
13- PID是什么?
每个进程有唯一进程标识值PID,内核使用pid_t在process descriptor里存储PID
如要打破兼容性,可以增加/proc/sys/kernel/pid_max里面的最大值
14- 如何获取当前执行中进程的进程描述符
通过current宏可以获得
x86中使用current_thread_info获取thread_info
current引用thread_info的task成员返回task_current
current_thread_info()->task;15- 进程状态有哪些?
| 进程状态 | 解释 |
|---|---|
| TASK_RUNNING | 进程处于运行中或者在运行等待队列里等待运行 |
| TASK_INTERRUPTIBLE | 进程睡眠中,等待条件中。条件满足或者获取信号,会进入TASK_RUNNING状态 |
| TASK_UNINTERRUPTIBLE | 与上者不同之处就是不会因为接受信号而唤醒 |
| __TASK_TRACED | 进程被其他进程追踪,例如debugger通过ptrace |
| __TASK_STOPPED | Process execution has stopped; the task is not running nor is it eligible to run.This occurs if the task receives the SIGSTOP , SIGTSTP , SIGTTIN , or SIGTTOU signal or if it receives any signal while it is being debugged. |
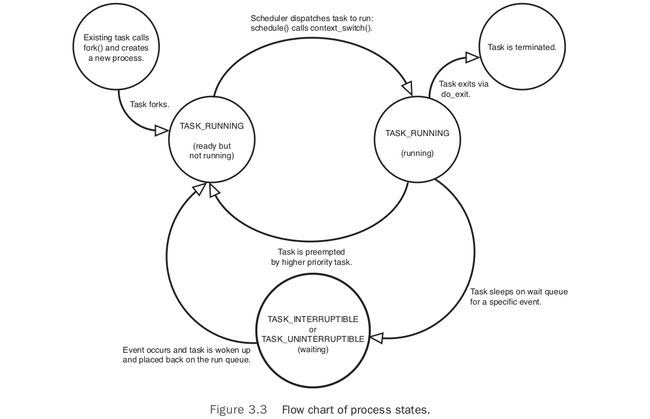
16- 复制当前进程状态
kernel代码经常需要改变进程状态,代码:
set_task_state(task, state); /*set task'task' to state 'state'*/
/*等效于*/
task->state = state;set_current_state(state);
/*等效于*/
set_task_state(current, state);linux/sched.h 中有具体的实现
17- 获取当前进程的父进程文件描述符
struct task_struct *my_parent = current->parent;//拥有parent指针18- 获取下个任务或者上个任务
//下个任务
#define next_task(p) list_entry((p)->tasks.next, struct task_struct, tasks)
//上个任务
#define prev_task(p) list_entry((p)->tasks.prev, struct task_struct, tasks)19- 进程创建
fork创建和父进程只有PID不同的子进程exec将可执行程序加载进地址空间,然后执行
20- Copy-on-write
Linux的fork实现使用了COW pages。
只有在需要write的时候才进行数据的复制,如果在fork之后立即调用exec,那么不会复制任何数据。
21- fork,vfork,__clone库调用均引用了clone系统调用,而clone调用了do_fork
22- clone相对于fork的区别?
有一系列flags指定了父子进程之间共享哪些资源
23- clone的函数调用树和相应作用
clone调用了do_fork用于处理forking中的成批的任务。
clone调用copy_process,然后启动进程。
copy_process()完成的工作如下:
- It calls
dup_task_struct(), which creates a newkernel stack,thread_infostructure, andtask_structfor the new process. - It then checks that the new child will not exceed the resource limits on the number of processes for the current user.
- The child needs to differentiate itself from its parent.Various members of the process descriptor are cleared or set to initial values. Members of the process descriptor not inherited are primarily statistically information.The bulk of the values in
task_structremain unchanged. - The child’s state is set to TASK_UNINTERRUPTIBLE to ensure that it does not yet run.
- copy_process() calls copy_flags() to update the
flagsmember of the task_struct .The PF_SUPERPRIV flag, which denotes whether a task usedsuperuser privileges, is cleared(=0).The PF_FORKNOEXEC flag, which denotes a process that has not calledexec(), is set(=1). - It calls alloc_pid() to assign an available
PIDto the new task. - Depending on the flags passed to clone() , copy_process() either duplicates or shares open files, filesystem information, signal handlers, process address space, and namespace.These resources are typically shared between threads in a given process; otherwise they are unique and thus copied here.
- Finally, copy_process() cleans up and returns to the caller a pointer to the new child.
24- vfork作用
与fork作用一样,除了的父进程的page table entries不进行复制。随着COW的使用,不复制父进程的PTE是vfork仅有的好处。
vfork的实现通过clone系统调用的特殊标志来实现
If Linux one day gains copy-on-write page table entries, there will no longer be any benefit.
The Linux Implementation of Threads
25- Linux内核中没有thread的概念,Linux用标准process实现所有thread
Linux内核没有提供任何特殊的scheduling semantics(调度语义) or data structures(数据结构)来显示threads.
26- Linux中的thread是什么?
thread就是能和其他process共享明确数据的process
Each thread has a unique(唯一) task_struct and appears to the kernel as a normal process—threads just happen to share resources, such as an address space, with other processes.
27-lightweight process(轻型进程)是什么?
The name “lightweight process” sums up the difference in philosophies 理论between Linux and other systems.
windows等系统中明确支持threads
其他系统中,lightweight process是比heavy process更小更快的执行单位。
Linux中,threads仅仅是process之间共享数据的简单方式
为创建一个拥有4个threads的process,in Linux, there are simply four processes and thus four normal task_struct structures.The four processes are set up to share certain resources. The result is quite elegant(简练的).
Creating Threads
28- 用clone实现thread,fork,vfork的方法
Threads are created the same as normal tasks, with the exception that the clone() system call is passed flags corresponding to the specific resources to be shared:
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0);很类似于fork,其parent process和创建的process被称为threads
- A normal fork() can be implemented as
clone(SIGCHLD, 0);- vfork() is implemented as
clone(CLONE_VFORK | CLONE_VM | SIGCHLD, 0);29- clone参数flags决定process的行为,具体有哪些,作用又是什么?如下
定义在头文件 linux/sched.h

Kernel thread
30- kernel thread是什么?作用?
kernel需要在后台完成一些操作,这就需要kernel thread完成。
kernel thread是在kernel space唯一存在的standard process(标准进程)
31- kernel thread和normal process的区别?
kernel thread没有address space(地址空间)
它们的用于address space的mm指针,指向NULL
32- kernel thread的注意点
- 可以使用
ps -ef查看kernel threads - kernel thread仅能在system boot时由其他kernel thread创建
- The kernel handles this(进程创建) automatically by forking all new kernel threads off of the
kthreaddkernel process.
33- 创建kernel thread的方法
接口在 linux/kthread.h
create:创建且不立即run的kernel thread
struct task_struct *kthread_create(int (*threadfn)(void *data),
void *data,
const char namefmt[],
...)创建的kernel thread处于unrunnable状态,除非显式地执行wake_up_process()才会开始执行
run:创建process并且进入runnable stae
struct task_struct *kthread_run(int (*threadfn)(void *data),
void *data,
const char namefmt[],
...)通常用macro(宏)实现,简单调用kthread_create和wake_up_process
34-如何停止kernel thread?
kernel thread会持续存在,直到调用do_exit()或者kernel的其他部分调用kthread_stop—将kthread_create()返回的task_struct的地址传入。
int kthread_stop(struct task_struct * k);Process Termination
35-process有哪几种中止方法?
- process调用exit() system call
- 显式地中止
- 隐式地从任何程序的main creturn(C编译器会在main return后面加上exit())
- 也可能由于signal或者exception而异常终止
36- do_exit()的作用
无论process如何中止,定义于 kernel/exit.c 的do_exit()会进行很多工作的处理。
do_exit完成如下琐事(chores):
- It sets the PF_EXITING flag in the flags member of the task_struct .
- It calls del_timer_sync() to remove any kernel timers. Upon return, it is guaranteed that no timer is queued and that no timer handler is running.
- If BSD process accounting is enabled, do_exit() calls acct_update_integrals() to write out accounting information.
- It calls exit_mm() to release the mm_struct held by this process. If no other process is using this address space—that it, if the address space is not shared—the kernel then destroys it.
- It calls exit_sem() . If the process is queued waiting for an IPC semaphore, it is dequeued here.
- It then calls exit_files() and exit_fs() to decrement the usage count of objects related to
file descriptorsandfilesystemdata, respectively. If either usage counts reach zero, the object is no longer in use by any process, and it is destroyed. - It sets the
task’s exitcode, stored in the exit_code member of the task_struct , to the code provided by exit() or whatever kernel mechanism forced the termination.The exit code is stored here for optionalretrieval(恢复)by the parent. - It calls exit_notify() to send signals to the task’s parent,
reparentsany of the task’s children to another thread in their thread group or the init process, and sets the task’s exit state, stored in exit_state in thetask_structstructure, to EXIT_ZOMBIE . do_exit()calls schedule() to switch to a new process (see Chapter 4). Because the process is nownot schedulable, this is the last code the task will ever execute.do_exit()never returns.
37- 中止的任务仅仅占据内存的部分是kernel stack, thread_info structure, and the task_struct structure
这些内容用于向parent提供信息。在parent接收信息后,这些留存的memory将会被释放,并且返回给system
Removing the Process Descriptor
38- 执行do_exit后,已中止进程的process descriptor仍然存在,但是process已经是僵尸进程
这是用于system在process中止后获取child process的信息。
porcess的清理工作和删除进程描述符的操作是分离开的。
39- 最后释放进程描述符是使用release_task
| no | release_taskl做了如下内容 |
|---|---|
| 1. | It calls __exit_signal() , which calls __unhash_process() , which in turns calls detach_pid() to remove the process from the pidhash and remove the process from the task list. |
| 2. | __exit_signal() releases any remaining resources used by the now dead process and finalizes statistics and bookkeeping. |
| 3. | If the task was the last member of a thread group, and the leader is a zombie, then release_task() notifies the zombie leader’s parent. |
| 4. | release_task() calls put_task_struct() to free the pages containing the process’s kernel stack and thread_info structure and deallocate the slab cache containing the task_struct . |
40. 无父进程任务的困境
do_exit()会调用exit_notify(),其会调用forget_original_parent能调用find_new_reaper()来改变父母(reparenting)
41 如果task是ptraced,他会被暂时reparent到debuging process(调试进程)
随着进程成功重分配父进程,就没有必要冒杀死(stray)僵尸进程的风险。initprocess会给所有子进程调用wait,这样能清除任何僵尸进程。
Conclusion
In this chapter, we looked at the core operating system a**bstraction of the process**.We discussed the generalities of the process, why it is important, and the relationship between processes and threads.We then discussed how Linux stores and represents processes (with task_struct and thread_info ), how processes are created (via fork() and ultimately(最后) clone() ), how new executable images are loaded into address spaces (via the exec() family of system calls), the hierarchy of processes, how parents glean(收集) information about their deceased(已死亡的) children (via the wait() family of system calls), and how processes ultimately(最后) die (forcefully or intentionally via exit() ).The process is a fundamental and crucial(重要的) abstraction, at the heart of every modern operating system, and ultimately the reason we have operating systems altogether (to run programs).
The next chapter discusses process scheduling, which is the delicate(精美的) and interesting manner in which the kernel decides which processes to run, at what time, and in what order.