卢本伟牛逼,写得很好
https://wudaijun.com/2019/04/cpu-cache-and-memory-model/
本文主要谈谈CPU Cache的设计,内存屏障的原理和用法,最后简单聊聊内存一致性。
我们都知道存储器是分层级的,从CPU寄存器到硬盘,越靠近CPU的存储器越小越快,离CPU越远的存储器越大但越慢,即所谓存储器层级(Memory Hierarchy)。以下是计算机内各种存储器的容量和访问速度的典型值。
| 存储器类型 | 容量 | 特性 | 速度 |
|---|---|---|---|
| CPU寄存器 | 几十到几百Bytes | 数据电路触发器,断电丢失数据 | 一纳秒甚至更低 |
| Cache | 分不同层级,几十KB到几MB | SRAM,断电丢失数据 | 几纳秒到几十纳秒 |
| 内存 | 几百M到几十G | DRAM,断电丢失数据 | 几百纳秒 |
| 固态硬盘(SDD) | 几十到几百G | SSD,断电不丢失数据 | 几十微秒 |
| 机械硬盘(HDD) | 上百G | 磁性介质和磁头,断电不丢失数据 | 几毫秒 |
从广义的概念上来说,所有的存储器都是其下一级存储器的Cache,CPU Cache缓存的是内存数据,内存缓存的是硬盘数据,而硬盘缓存的则是网络中的数据。本文只谈CPU Cache,一个简单的CPU Cache示意图如下:
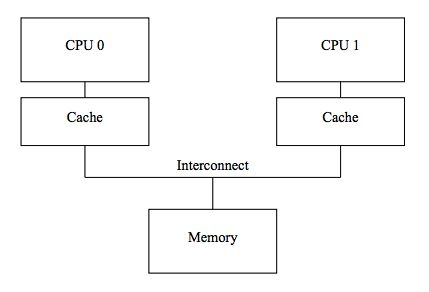
图中忽略了一些细节,现代的CPU Cache通常分为三层,分别叫L1,L2,L3 Cache, 其中L1,L2 Cache为每个CPU核特有,L3为所有CPU核共有,L1还分为缓存指令的i-cache(只读)和缓存程序数据的d-cache,L2 L3 Cache则不区分指令和程序数据,称为统一缓存(unified cache)。本文主要讨论缓存命中和缓存一致性的问题,因此我们只关注L1 Cache,不区分指令缓存和程序数据缓存。
Cache Geometry
当CPU加载某个地址上的数据时,会从Cache中查找,Cache由多个Cache Line构成(通常L1 Cache的Cache Line大小为64字节),因此目标地址必须通过某种转换来映射对应的Cache Line,我们可以很容易想到两种方案:
- 指定地址映射到指定Cache Line,读Cache时对地址哈希(通常是按照Cache Line数量取模,即在二进制地址中取中间位)来定位Cache Line,写Cache时如果有冲突则丢掉老的数据。这种策略叫直接映射
- 任何地址都可以映射到任何Cache Line,读Cache时遍历所有Cache Line查找地址,写Cache时,可以按照LFU(最不常使用)或LRU(最近最少使用)等策略来替换。这种策略叫全相联
直接映射的缺点在于在特定的代码容易发生冲突不命中,假设某CPU Cache的Cache Line大小为16字节,一共2个Cache Line,有以下求向量点乘的代码:
1 |
// 代码片段1 |
由于x和y在函数栈中是连续存放的,x[0..3]和y[0..3]将映射到同一个Cache Line, x[4..7]和y[4..7]被映射到同一个Cache Line,那么在for循环一次读取x[i],y[i]的过程中,Cache Line将不断被冲突替换,导致Cache “抖动”(thrashing)。也就是说,在直接映射中,即使程序看起来局部性良好,也不一定能充分利用Cache。
那么同样的例子,换成全相联,则不会有这个问题,因为LRU算法会使得y[0..3]不会替换x[0..3]所在的Cache Line,也就不会造成Cache抖动。全相连的缺点是由于每一次读Cache都需要遍历所有的Cache Line进行地址匹配,出于效率考虑,它不适用于太大的Cache。
So,现代OS的操作系统是取两者折中,即组相连结构: 将若干Cache Line分为S个组,组间直接映射,组内全相连,如下图:
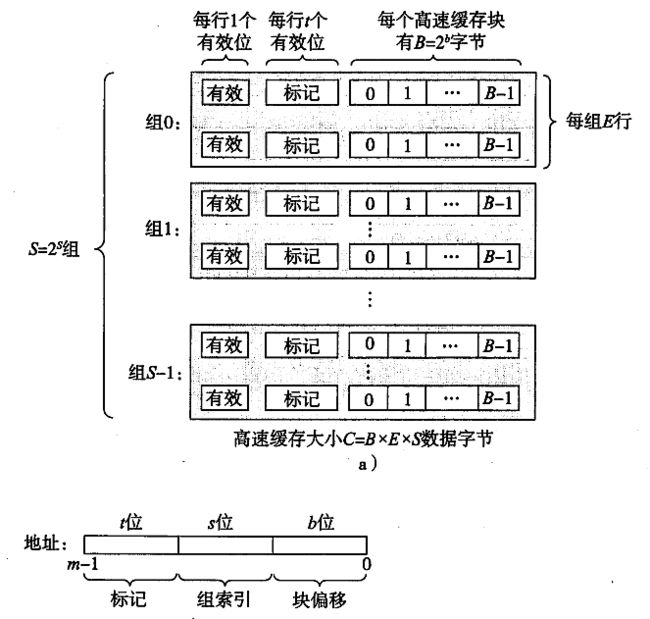
通用的Cache映射策略,将目标地址分为t(标记位),s(组索引),b(块偏移)三个部分。我在Linux Perf 简单试用中也有例子说明程序局部性对效率的影响。
Cache Coherency
前面我们谈的主要是Cache的映射策略,Cache设计的最大难点其实在于Cache一致性: 即所有CPU看到的指定地址的值是一致的。比如在CPU尝试修改某个地址值时,其它CPU可能已有该地址的缓存,甚至可能也在执行修改操作。因此该CPU需要先征求其它CPU的”同意”,才能执行操作。这需要给各个CPU的Cache Line加一些标记(状态),辅以CPU之间的通信机制(事件)来完成, 这可以通过MESI协议来完成。MESI是以下四个状态的简称:
M(modified): 该行刚被 CPU 改过,并且保证不会出现在其它CPU的Cache Line中。即CPU是该行的所有者。CPU持有该行的唯一正确参照。
E(exclusive): 和M类似,但是未被修改,即和内存是一致的,CPU可直接对该行执行修改(修改之后为modified状态)。
S(shared): 该行内容至少被一个其它CPU共享,因此该CPU不能直接修改该行。而需要先与其它CPU协商。
I(invalid): 该行为无效行,即为空行,前面提到Cache策略会优先填充Invalid行。
除了状态之外,CPU还需要一些消息机制:
Read: CPU发起读取数据请求,请求中包含需要读取的数据地址。
Read Response: 作为Read消息的响应,该消息可能是内存响应的,也可能是某CPU响应的(比如该地址在某CPU Cache Line中为Modified状态,该CPU必须返回该地址的最新数据)。
Invalidate: 该消息包含需要失效的地址,所有的其它CPU需要将对应Cache置为Invalid状态
Invalidate Ack: 收到Invalidate消息的CPU在将对应Cache置为Invalid后,返回Invalid Ack
Read Invalidate: 相当于Read消息+Invalidate消息,即取得数据并且独占它,将收到一个Read Response和所有其它CPU的Invalid Ack
Writeback: 写回消息,即将状态为Modified的行写回到内存,通常在该行将被替换时使用。现代CPU Cache基本都采用”写回(Write Back)”而非”直写(Write Through)”的方式。
1 |
思考: 为什么要有专门的Read Invalidate消息,而不直接用Read + Invalidate消息的方式呢? |
具体MESI状态机的转换不再赘述,本质上来说,CPU体系结构依赖消息传递的方式来共享内存。
下面举个例子,假设我们有个四核CPU系统,每个CPU只有一个Cache Line,每个Cache Line包含一个字节,内存地址空间为0x0-0xF,一共两个字节的数据,有如下操作序列:
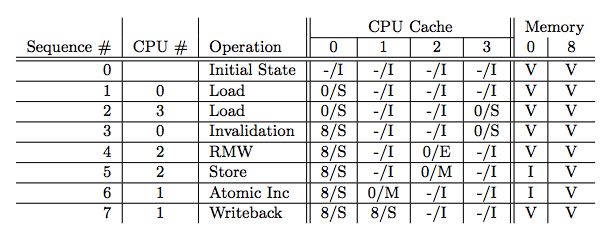
上图第一行代表操作发生的时序,第二行是执行操作的CPU,第三行是CPU执行的操作,后面四行是各个CPU的Cache Line状态,最后两行是地址0和地址8在内存中的数据是是最新的(V)还是过期的(I)。初始状态下,每个CPU Cache Line都是未填充(Invalid)的。
- CPU0 加载地址0x0的数据,发送Read消息,对应Cache Line被标记为Shared
- CPU3 加载地址0x0的数据,同样,Cache Line标记为Shared
- CPU0 加载地址0x8的数据,导致Cache Line被替换,由于Cache Line之前为Shared状态,即与内存中数据一致,可直接覆盖Cache Line,而无需写回
- CPU2 加载地址0x0的数据,并且之后将要修改它,因此CPU2发出Read Invalidate消息以获取该地址的独占权,导致CPU3的Cache Line被置为Invalid,CPU2 Cache Line为Exclusive
- CPU2 修改地址0x0的数据,由于此时Cache Line为Exclusive,因此它可以直接修改Cache Line,此时Cache Line状态为Modified。此时内存中的0x0内存为过期数据(I)
- CPU1 对地址0x0的数据执行原子(atomic)递增操作,将发出Read Invalidate消息,CPU2将返回Read Response(而不是内存),然后CPU1将持有地址0x0的Cache Line,状态为Modified,数据为递增后的数据,CPU2的Cache Line为Invalid,内存中的数据仍然是过期(I)状态
- CPU1 加载地址0x0的数据,此时CPU1 Cache Line将被替换,由于其状态为Modified,因此需要先执行写回操作将Cache Line写回内存,此时内存中的数据才是最新(V)的
Store Buffers
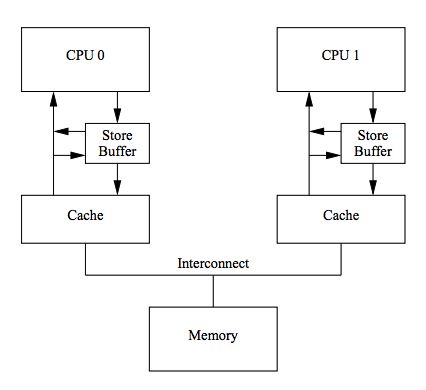
MESI协议足够简单,并且能够满足我们对Cache一致性的需求,它在单个CPU对指定地址的反复读写方面有很好的性能表现,但在某个CPU尝试修改在其它CPU Cache Line中存在的数据时,性能表现非常糟糕,因为它需要发出Invalidate消息并等待Ack,这个延迟(Stall)对CPU来说对难以忍受的并且有时是无必要的,比如执行写入的CPU可能只是简单的给这个地址赋值(而不关心它的当前值是什么)。解决这类不必要的延迟的一个方案就是在CPU和Cache之间加一个Store Buffer: CPU可以先将要写入的数据写到Store Buffer,然后继续做其它事情。等到收到其它CPU发过来的Cache Line(Read Response),再将数据从Store Buffer移到Cache Line。结构如下所示:

然后加了Store Buffer之后,会引入另一个问题,比如有如下代码:
1 |
// 代码片段2 |
初始状态下,假设a,b值都为0,并且a存在CPU1的Cache Line中(Shared状态),可能出现如下操作序列:
- CPU0 要写入A,发出Read Invalidate消息,并将a=1写入Store Buffer
- CPU1 收到Read Invalidate,返回Read Response(包含a=0的Cache Line)和Invalidate Ack
- CPU0 收到Read Response,更新Cache Line(a=0)
- CPU0 开始执行
b = a + 1,从Cache Line中加载a,得到a=0 - CPU0 将Store Buffer中的a=1应用到Cache Line
- CPU0 得到 b=0+1,断言失败
造成这个问题的根源在于对同一个CPU存在对a的两份拷贝,一份在Cache,一份在Store Buffer,前者用于读,后者用于写,因而出现CPU执行顺序与程序顺序(Program Order)不一致(先执行了b=a+1,再执行a=1)。
Store Forwarding
Store Buffer可能导致破坏程序顺序(Program Order)的问题,硬件工程师在Store Buffer的基础上,又实现了”Store Forwarding”技术: CPU可以直接从Store Buffer中加载数据,即支持将CPU存入Store Buffer的数据传递(forwarding)给后续的加载操作,而不经由Cache。结构如图:
现在解决了同一个CPU读写数据的问题,再来看看并发程序:
1 |
// 代码片段3 |
假设初始状态下,a=0; b=0;,a存在于CPU1的Cache中,b存在于CPU0的Cache中,均为Exclusive状态,CPU0执行foo函数,CPU1执行bar函数,上面代码的预期显然为断言为真。那么来看下执行序列:
- CPU1执行
while(b == 0),由于CPU1的Cache中没有b,发出Read b消息 - CPU0执行
a = 1,由于CPU0的Cache中没有a,因此它将a(当前值1)写入到Store Buffer并发出Read Invalidate a消息 - CPU0执行
b = 1,由于b已经存在在Cache中(Exclusive),因此可直接执行写入 - CPU0收到
Read b消息,将Cache中的b(当前值1)返回给CPU1,将b写回到内存,并将Cache Line状态改为Shared - CPU1收到包含b的Cache Line,结束
while (b == 0)循环 - CPU1执行
assert(a == 1),由于此时CPU1 Cache Line中的a仍然为0并且有效(Exclusive),断言失败 - CPU1收到
Read Invalidate a消息,返回包含a的Cache Line,并将本地包含a的Cache Line置为Invalid(已经晚了) - CPU0收到CPU1传过来的Cache Line,然后将Store Buffer中的a(当前值1)刷新到Cache Line
1 |
思考: 为什么CPU0执行`a=1`时要发送Read Invalidate而不直接发送Invalidate? |
出现这个问题的原因在于CPU不知道a, b之间的数据依赖,CPU0对a的写入走的是Store Buffer(有延迟),而对b的写入走的是Cache,因此b比a先在Cache中生效,导致CPU1读到b=1时,a还存在于Store Buffer中。
Memory Barrier
对于上面的内存不一致,很难从硬件层面优化,因为CPU不可能知道哪些值是相关联的,因此硬件工程师提供了一个叫内存屏障的东西,开发者可以用它来告诉CPU该如何处理值关联性。我们可以在a=1和b=1之间插入一个内存屏障:
1 |
// 代码片段4 |
当CPU看到内存屏障smp_mb()时,会先刷新当前(屏障前)的Store Buffer,然后再执行后续(屏障后)的Cache写入。这里的”刷新Store Buffer”有两种实现方式: 一是简单地刷新Store Buffer(需要挂起等待相关的Cache Line到达),二是将后续的写入也写到Store Buffer中,直到屏障前的条目全部应用到Cache Line(可以通过给屏障前的Store Buffer中的条目打个标记来实现)。这样保证了屏障前的写入一定先于屏障后的写入生效,第二种方案明显更优,以第二种方案为例:
- CPU1执行
while(b == 0),由于CPU1的Cache中没有b,发出Read b消息 - CPU0执行
a = 1,由于CPU0的Cache中没有a,因此它将a(当前值1)写入到Store Buffer并发出Read Invalidate a消息 - CPU0看到
smp_mb()内存屏障,它会标记当前Store Buffer中的所有条目(即a = 1被标记) - CPU0执行
b = 1,尽管b已经存在在Cache中(Exclusive),但是由于Store Buffer中还存在被标记的条目,因此b不能直接写入,只能先写入Store Buffer中 - CPU0收到
Read b消息,将Cache中的b(当前值0)返回给CPU1,将b写回到内存,并将Cache Line状态改为Shared - CPU1收到包含b的Cache Line,继续
while (b == 0)循环 - CPU1收到
Read Invalidate a消息,返回包含a的Cache Line,并将本地的Cache Line置为Invalid - CPU0收到CPU1传过来的包含a的Cache Line,然后将Store Buffer中的a(当前值1)刷新到Cache Line,并且将Cache Line状态置为Modified
- 由于CPU0的Store Buffer中被标记的条目已经全部刷新到Cache,此时CPU0可以尝试将Store Buffer中的
b=1刷新到Cache,但是由于包含B的Cache Line已经不是Exclusive而是Shared,因此需要先发Invalid b消息 - CPU1收到
Invalid b消息,将包含b的Cache Line置为Invalid,返回Invalid Ack - CPU1继续执行
while(b == 0),此时b已经不在Cache中,因此发出Read消息 - CPU0收到
Invalid Ack,将Store Buffer中的b=1写入Cache - CPU0收到Read消息,返回包含b新值的Cache Line
- CPU1收到包含b的Cache Line,可以继续执行
while(b == 0),终止循环 - CPU1执行
assert(a == 1),此时a不在其Cache中,因此发出Read消息 - CPU0收到Read消息,返回包含a新值的Cache Line
- CPU1收到包含a的Cache Line,断言为真
上面的步骤看起来很多,其实比较简单,由于内存屏障的存在,导致b=1只能随a=1一起进入到Store Buffer,即b的新值不会先于a的新值出现在CPU0的Cache中,对于应用程序而言,内存屏障前的写入会先于内存屏障后的写入生效。
Invalid Queue
引入了Store Buffer,再辅以Store Forwarding,Memory Barrier,看起来好像可以自洽了,然而还有一个问题没有考虑: Store Buffer的大小是有限的,所有写入操作的Cache Missing都会使用Store Buffer,特别是出现内存屏障时,后续的所有写入操作(不管是否Cache Miss)都会挤压在Store Buffer中(直到Store Buffer中屏障前的条目处理完),因此Store Buffer很容易会满,当Store Buffer满了之后,CPU还是会卡在等对应的Invalid Ack以处理Store Buffer中的条目。因此还是要回到Invalid Ack中来,Invalid Ack耗时的主要原因是CPU要先将对应的Cache Line置为Invalid后再返回Invalid Ack,一个很忙的CPU可能会导致其它CPU都在等它回Invalid Ack。解决思路还是化同步为异步: CPU不必要处理了Cache Line之后才回Invalid Ack,而是可以先将Invalid消息放到某个请求队列Invalid Queue,然后就返回Invalid Ack。CPU可以后续再处理Invalid Queue中的消息,大幅度降低Invalid Ack响应时间。此时的CPU Cache结构图如下:
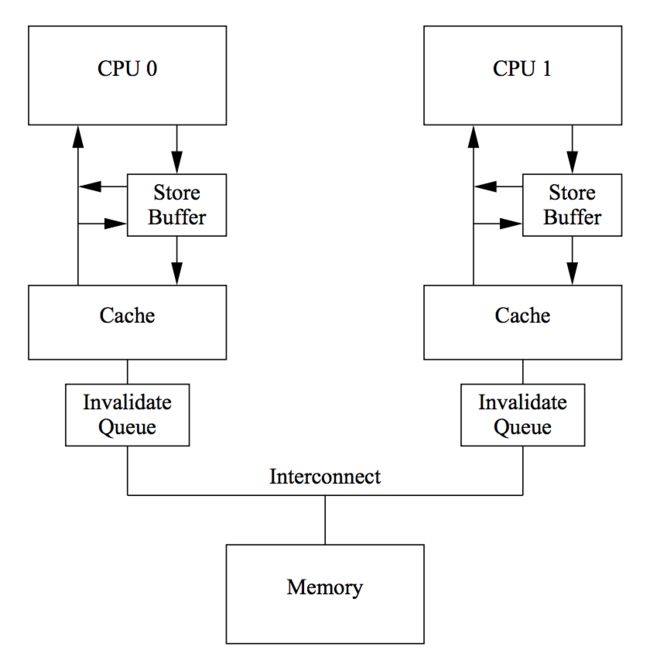
和Store Buffer类似,Invalid Queue有两个问题要考虑,一是CPU在处理任何Cache Line的MSEI状态前,都必须先看Invalid Queue中是否有该Cache Line的Invalid消息没有处理。这一点在CPU数据竞争不是很激烈时是可以接受的。这方面的一个极端是false sharing。
Invalid Queue的另一个要考虑的问题是它也增加了破坏内存一致性的可能,即可能破坏我们之前提到的内存屏障:
1 |
// 代码片段5 |
仍然假设a, b的初始值为0,a在CPU0,CPU1中均为Shared状态,b为CPU0独占(Exclusive状态),CPU0执行foo,CPU1执行bar:
- CPU0执行
a = 1,由于其有包含a的Cache Line,将a写入Store Buffer,并发出Invalidate a消息 - CPU1执行
while(b == 0),它没有b的Cache,发出Read b消息 - CPU1收到CPU0的
Invalidate a消息,将其放入Invalidate Queue,返回Invalidate Ack - CPU0收到
Invalidate Ack,将Store Buffer中的a=1刷新到Cache Line,标记为Modified - CPU0看到
smp_mb()内存屏障,但是由于其Store Buffer为空,因此它可以直接跳过该语句 - CPU0执行
b = 1,由于其Cache独占b,因此直接执行写入,Cache Line标记为Modified, - CPU0收到CPU1发的
Read b消息,将包含b的Cache Line写回内存并返回该Cache Line,本地的Cache Line标记为Shared - CPU1收到包含b(当前值1)的Cache Line,结束while循环
- CPU1执行
assert(a == 1),由于其本地有包含a旧值的Cache Line,读到a初始值0,断言失败 - CPU1这时才处理Invalid Queue中的消息,将包含a旧值的Cache Line置为Invalid
问题在于CPU1在读取a的Cache Line时,没有先处理Invalid Queue中该Cache Line的Invalid操作,解决思路仍然是内存屏障,我们可以通过内存屏障让CPU标记当前Invalid Queue中所有的条目,所有的后续加载操作必须先等Invalid Queue中标记的条目处理完成再执行。因此我们可以在while和assert之间插入smp_mb()。这样CPU1在看到smp_mb()后,会先处理Invalidate Queue,然后发现本地没有包含a的Cache Line,重新从CPU0获取,得到a的值为1,断言成立。具体操作序列不再赘述。
前面我们说的内存屏障可以同时作用于Store Buffer和Invalidate Queue,而实际上,CPU0(foo函数)只有写操作,因此只关心Store Buffer,同样的CPU1(bar函数)都是读操作,只关心Invalidate Queue,因此,大多数CPU架构将内存屏障分为了读屏障(Read Memory Barrier)和写屏障(Write Memory Barrier):
- 读屏障: 任何读屏障前的读操作都会先于读屏障后的读操作完成
- 写屏障: 任何写屏障前的写操作都会先于写屏障后的写操作完成
- 全屏障: 同时包含读屏障和写屏障的作用
因此前面的例子中,foo函数只需要写屏障,bar函数需要读屏障。实际的CPU架构中,可能提供多种内存屏障,比如可能分为四种:
- LoadLoad: 相当于前面说的读屏障
- LoadStore: 任何该屏障前的读操作都会先于该屏障后的写操作完成
- StoreLoad: 任何该屏障前的写操作都会先于该屏障后的读操作完成
- StoreStore: 相当于前面说的写屏障
实现原理类似,都是基于Store Buffer和Invalidate Queue,不再赘述。
Instruction Reordering
到目前为止我们只考虑了CPU按照程序顺序执行指令,而实际上为了更好地利用CPU,CPU和编译器都可能会对指令进行重排(reordering):
- 编译期间重排: 编译器在编译期间,可能对指令进行重排,以使其对CPU更友好
- 运行期间重排: CPU在执行指令的过程中,可能乱序执行以更好地利用流水线
不管是CPU架构,VM,还是编译器,在对指令进行重排时都要遵守一个约束: 不管指令如何重排,对单线程来说,结果必然是一致的。即不会改变单线程程序的行为。比如:
1 |
// 代码片段6 |
编译器/CPU/VM 可以对a = 1;和b = 2;进行对换,而不能将c = a + b与前面两句对换,在实现上来说,对指定地址的操作(读写)序列,CPU是会保证和程序顺序一致的(比如a是先写后读),并且CPU的读写对自己总是可见的(Store Forwarding),对于不同的地址,CPU不能解析其依赖关系,可能会乱序执行,比如如果有其它线程依赖于a先于b赋值这个事实,那么就必须要应用程序告诉CPU/编译器,a和b有依赖关系,不要重排。前面提到的内存屏障,一直谈的是它的可见性(visibility)功能,它能够让屏障前的操作(读/写)即时刷新,被其它CPU看到。而内存屏障还有个功能就是限制指令重排(读/写指令),否则即使在a = 1和b = 2之间加了内存屏障,b也有可能先于a赋值,前面的foo()和bar()的例子也会断言失败。
Programing
对应用层而言,各种语言提供的并发相关关键字和工具,底层都会使用内存屏障。
volatile
java中可以通过volatile关键字来保证变量的可见性,并限制局部的指令重排。它的实现原理是在每个volatile变量写操作前插入StoreStore屏障,在写操作后插入StoreLoad屏障,在每个volatile变量读操作前插入LoadLoad屏障,在读操作后插入LoadStore屏障来完成。
atomic
以C++的atomic为例,atomic本身的职责是保证原子性,与volatile定位不太一样,后者本身是不保证原子性的,C++ atomic允许在保证原子的基础上,指定内存顺序,即使用哪种内存屏障。
1 |
// 代码片段7 |
在这种情况下,可能出现全局执行序列为: D A B C,出现r1=r2=42的情况。memory_order_relaxed相当于没有加内存屏障。除了memory_order_relaxed外,还有:
memory_order_acquire: 在该原子变量的读操作前插入LoadLoad屏障,在读操作后插入LoadStore。即Load之后的所有读写操作不能重排到Load之前memory_order_consume: acquire限制了Load之后的所有读写操作向前重排,而consume则只限制相关联的读写操作(单线程语义内)memory_order_release: 在该原子变量的写操作前插入LoadStore屏障,在写操作后插入StoreStore屏障。即Store之前的所有读写操作不能重排到Store之后memory_order_acq_rel: 相当于memory_order_acquire+memory_order_releasememory_order_seq_cst: 最强的顺序一致性,在memory_order_acq_rel的基础上,支持单独全序,即所有线程以同一顺序观测到该原子变量的所有修改
这里也引申出关于内存屏障的两个常用语义:
- acquire语义:Load 之后的读写操作无法被重排至 Load 之前。即 相当于LoadLoad和LoadStore屏障。
- release语义:Store 之前的读写操作无法被重排至 Store 之后。即 相当于LoadStore和StoreStore屏障。
注意acquire和release语义没有提到StoreLoad屏障,StoreLoad屏障是四种屏障中开销最大的,这个在后面会提到。
mutex
mutex的实现通常是在mutex lock时加上acquire屏障(LoadLoad+LoadStore),在mutex unlock时加上release屏障(StoreStore+StoreLoad),例如:
1 |
// 代码片段8 |
由于mutex任意时刻只能被一个线程占有,因此A线程拿到mutex必然在B线程释放mutex之后,由于内存屏障的存在,mutex_lock和mutex_unlock之间的指令只能在mutex里面(无法越过mutex),并且A线程能即时看到B线程mutex中作出的更改。
注意,这里列举的volatile, atomic, mutex的具体实现和语义可能在不同的语言甚至同种语言不同的编译平台中有所区别(如C++不同的VS版本对volatile关键字的内存屏障使用有所区别)。对开发者而言,编写并发程序需要关注三个东西: 原子性,可见性和顺序性。
- 原子性: 尽管在如今大部分平台下,对一个字的数据进行存取(int,指针)的操作本身就是原子性的,但为了更好地跨平台性,通过atomic操作来实现原子性是更好的方法,并且不会造成额外的开销。C++的atomic还提供可见性和顺序性选项
- 可见性: 数据同步相关,前面讨论的CPU Cache设计主要关注的就是可见性,即同一时刻所有CPU看到的某个地址上的值是一致的。Cache一致性主要解决的就是数据可见性的问题
- 顺序性: 内存屏障的另一个功能就是可以限制局部的指令重排(一些文章将内存屏障定义为限制指令重排工具,我认为是不准确的,如前面所讨论的,即使没有指令重排,有时也需要内存屏障来保证可见性)。内存屏障保证屏障前的某些操作必定限于屏障后的操作发生且可见。但屏障前或屏障后的指令,CPU/编译器仍然可以在不改变单线程结果的情况下进行局部重排。每个硬件平台有自己的基础顺序性(强/弱内存模型)
Weak/Strong Memory Models
不同的处理器平台,本身的内存模型有强(Strong)弱(Weak)之分。
Weak Memory Model: 如DEC Alpha是弱内存模型,它可能经历所有的四种内存乱序(LoadLoad, LoadStore, StoreLoad, StoreStore),任何Load和Store操作都能与任何其它的Load或Store操作乱序,只要其不改变单线程的行为。Weak With Date Dependency Ordering: 如ARM, PowerPC, Itanium,在Aplpha的基础上,支持数据依赖排序,如C/C++中的A->B,它能保证加载B时,必定已经加载最新的AStrong Memory Model: 如X86/64,强内存模型能够保证每条指令acquire and release语义,换句话说,它使用了LoadLoad/LoadStore/StoreStore三种内存屏障,即避免了四种乱序中的三种,仍然保留StoreLoad的重排,对于代码片段7来说,它仍然可能出现r1=r2=42的情况Sequential Consistency: 最强的一致性,理想中的模型,在这种内存模型中,没有乱序的存在。如今很难找到一个硬件体系结构支持顺序一致性,因为它会严重限制硬件对CPU执行效率的优化(对寄存器/Cache/流水线的使用)。
前面说到C++ atomic内存模型属于语言级的约束定义,它建立在处理器平台内存模型之上,如果处理器平台是SC(Sequential Consistency)的,那么语言级无论如何定义也无法将硬件改为更松散的内存模型。语言级的内存模型还有一个重要作用就是限制编译器reorder,即生成编译器屏障(fence)。因此即使处理器平台是SC的,语言层面定义为relaxed也可能因为编译器reorder导致结果不如预期。
Summary
本文比较杂乱,前面主要介绍CPU Cache结构和Cache一致性问题,引出内存屏障的概念。后面顺便简单谈了谈指令乱序和内存一致性。
实际的CPU Cache结构比上面阐述的要复杂得多,其核心的优化理念都是化同步为异步,然后再去处理异步下的一致性问题(处理不了就交给开发者…)。尽管异步会带来更多的问题,但它仍然是达成高吞吐量的必经之路。硬件方面的结构优化到一定程度了,CPU/编译器就开始打应用层代码的主意: 指令重排。
对开发者来说,应用程序可以通过封装好的mutex完成大部分的并发控制,而无需关注底层用了哪些内存屏障,各平台的内存一致性等细节。但是在使用比mutex更底层的同步机制(如atomic, volatile, memory-barrier, lock-free等)时,就要务必小心。从原子性,可见性,顺序性等方面确保代码执行结果如预期。
References
- 一致性杂谈
- Memory Barriers: a Hardware View for Software Hackers
- Weak vs. Strong Memory Models
- Acquire and Release Semantics
- 如何理解 C++11 的六种 memory order?