CVPR 2020 论文大盘点-动作识别篇

本文盘点所有CVPR 2020 动作识别(Action Recognition )相关论文,该方向也常被称为视频分类(Video Classification )。从后面的名字可以看出该任务就是对含人体动作的视频进行分类。
(关于动作检测、分割、活动识别等方向将在后续文章整理)
该部分既包含基于普通视频的动作识别,也包含基于深度图和基于骨架的动作识别。
因为视频既包含空域信息,又包含时域信息,所以时空信息的融合、特征提取是该领域的重要方向。
因为视频往往数据量大,信息冗余,是典型的计算密集型任务,以往的方法往往(如3D CNN)计算代价很高,提高(训练/推断)速度也是不少论文研究的方向。
特别值得一提的是斯坦福大学、MIT、谷歌发表的两篇基于视频的无监督表示学习,不仅可用于动作识别,其可以看作为通用的视觉特征提取方法,相信会对未来的计算机视觉研究产生重要影响。
大家可以在:
http://openaccess.thecvf.com/CVPR2020.py
按照题目下载这些论文。
如果想要下载所有CVPR 2020论文,请点击这里:
CVPR 2020 论文全面开放下载,含主会和workshop
动作识别(Action Recognition)
细粒度动作识别的多模态域适应技术,使用RGB与光流数据,解决动作识别在不同数据集上训练和测试性能下降的问题。
Multi-Modal Domain Adaptation for Fine-Grained Action Recognition
作者 | Jonathan Munro, Dima Damen
单位 | 布里斯托大学
时间金字塔网络(TPN)用于动作识别,可方便“即插即用”到2D和3D网络中,显著改进动作识别的精度。
Temporal Pyramid Network for Action Recognition
作者 | Ceyuan Yang, Yinghao Xu, Jianping Shi, Bo Dai, Bolei Zhou
单位 | 香港中文大学;商汤
代码 | Temporal Pyramid Network for Action Recognition
主页 | https://decisionforce.github.io/TPN/

提出motion excitation (ME) 模块 和 multiple temporal aggregation (MTA) 模块用于捕获短程和长程时域信息,提高动作识别的速度和精度。
TEA: Temporal Excitation and Aggregation for Action Recognition
作者 | Yan Li, Bin Ji, Xintian Shi, Jianguo Zhang, Bin Kang, Limin Wang
单位 | 腾讯;南京大学;南方科技大学

提取视频特征往往需要计算密集的3D CNN操作,该文发明一种 Gate-Shift Module (GSM) 模块利用分组空间选通方法控制时空分解交互,大大降低了视频动作识别算法复杂度。
Gate-Shift Networks for Video Action Recognition
作者 | Swathikiran Sudhakaran, Sergio Escalera, Oswald Lanz
单位 | FBK,Trento, Italy;巴塞罗那大学
代码 | https://github.com/swathikirans/GSM

高效视频识别的扩展架构,降低参数量减少计算量
X3D: Expanding Architectures for Efficient Video Recognition
作者 | Christoph Feichtenhofer
单位 | FAIR
代码 | https://github.com/facebookresearch/SlowFast
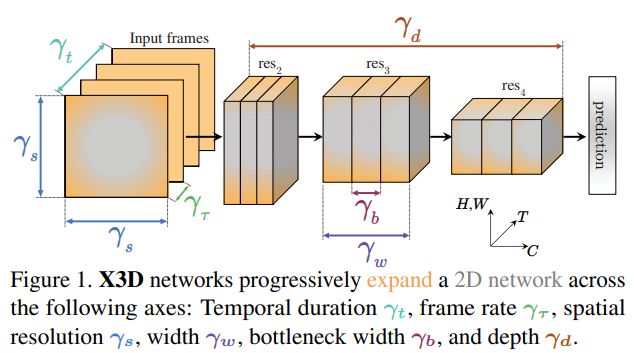
3D CNN的正则化
该文提出一种简单有效的针对3D CNN 的正则化方法:Random Mean Scaling (RMS),防止过拟合。
Regularization on Spatio-Temporally Smoothed Feature for Action Recognition
作者 | Jinhyung Kim, Seunghwan Cha, Dongyoon Wee, Soonmin Bae, Junmo Kim
单位 | KAIST;卡内基梅隆大学;Clova AI, NAVER Corp

结合视觉、语音、文本的动作识别
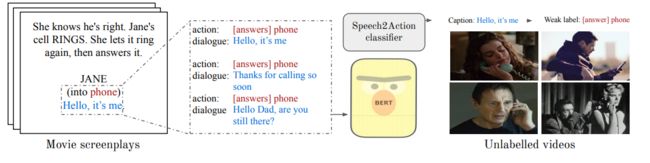
动作识别的跨模态监督信息提取(文本-语音-视觉识别的结合)
该文研究了一个非常有意思的问题,通过电影视频中语音与对应台词构建一个动作识别的分类器,然后用此模型对大规模的视频数据集进行了弱监督标注,使用此标注数据训练的模型在动作识别问题中取得了superior的精度。
Speech2Action: Cross-Modal Supervision for Action Recognition
作者 | Arsha Nagrani, Chen Sun, David Ross, Rahul Sukthankar, Cordelia Schmid, Andrew Zisserman
单位 | VGG, Oxford;谷歌;DeepMind
面对视频分类中巨大的数据冗余,该文提出图像-音频对的概念,图像表示了视频中绝大部分表观信息,音频表示了视频中的动态信息,找到这些图像-音频对后再选择一部分用于视频分类,精度达到SOTA,还大大提高了动作识别的速度。
Listen to Look: Action Recognition by Previewing Audio
作者 | Ruohan Gao, Tae-Hyun Oh, Kristen Grauman, Lorenzo Torresani
单位 | 得克萨斯大学奥斯汀分校;FAIR
代码 | https://github.com/facebookresearch/Listen-to-Look

动作识别中的时空信息融合
如何在动作识别中进行更好的时空信息融合是涉及更好的动作识别算法的关键,该文提出在概率空间理解、分析时空融合策略,大大提高分析效率,并提出新的融合策略,实验证明该策略大大提高了识别精度。
Spatiotemporal Fusion in 3D CNNs: A Probabilistic View
作者 | Yizhou Zhou, Xiaoyan Sun, Chong Luo, Zheng-Jun Zha, Wenjun Zeng
单位 | 中国科学技术大学;微软亚洲研究院

视频模型训练策略
何恺明团队作品。该文提出一种多网格训练策略训练视频分类模型,大大降低训练时间,精度得以保持,甚至还有提高。
A Multigrid Method for Efficiently Training Video Models
作者 | Chao-Yuan Wu, Ross Girshick, Kaiming He, Christoph Feichtenhofer, Philipp Krahenbuhl
单位 | 得克萨斯大学奥斯汀分校;FAIR
代码| https://github.com/facebookresearch/SlowFast
解读 | https://zhuanlan.zhihu.com/p/105287699

少样本视频分类
李飞飞团队作品。该文提出动作基因组(Action Genome)的概念,将动作看作时空场景图的组合,在少样本的动作识别问题中提高了精度。
Action Genome: Actions As Compositions of Spatio-Temporal Scene Graphs
作者 | Jingwei Ji, Ranjay Krishna, Li Fei-Fei, Juan Carlos Niebles
单位 | 斯坦福大学

通过视频信号的时序校正模块提高少样本的视频分类精度
Few-Shot Video Classification via Temporal Alignment
作者 | Kaidi Cao, Jingwei Ji, Zhangjie Cao, Chien-Yi Chang, Juan Carlos Niebles
单位 | 斯坦福大学

基于视频的无监督表示学习
无监督嵌入的视频表示学习。因为视频中含有丰富的动态结构信息,而且无处不在,所以是无监督视觉表示学习的最佳素材。本文在视频中学习视觉嵌入,使得在嵌入空间相似视频距离近,而无关视频距离远。在大量视频中所学习的视觉表示可大幅提高动作识别、图像分类的精度。
(感觉这个工作很有价值,代码开源,值得follow)
Unsupervised Learning From Video With Deep Neural Embeddings
作者 | Chengxu Zhuang, Tianwei She, Alex Andonian, Max Sobol Mark, Daniel Yamins
单位 | 斯坦福大学;MIT
代码 | https://github.com/neuroailab/VIE
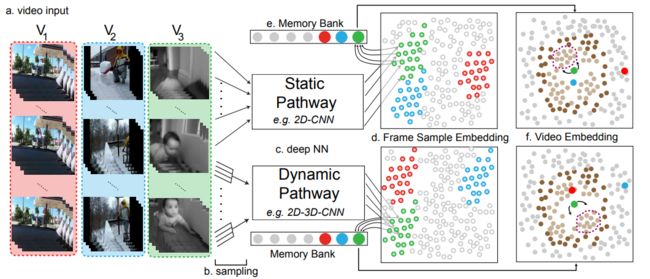
同上一篇,同样是希望在大规模视频数据中学习视觉表示。
多模多任务的无监督表示学习,跨模态通过蒸馏进行表示共享。
该自监督方法打败了ImageNet数据集上训练的有标注数据训练的模型。
Evolving Losses for Unsupervised Video Representation Learning
作者 | AJ Piergiovanni, Anelia Angelova, Michael S. Ryoo
单位 | 谷歌

合成动作识别
用于识别训练集没有的,对操作物体进行替换的动作
Something-Else: Compositional Action Recognition With Spatial-Temporal Interaction Networks
作者 | Joanna Materzynska, Tete Xiao, Roei Herzig, Huijuan Xu, Xiaolong Wang, Trevor Darrell
单位 | 牛津大学;伯克利;以色列特拉维夫大学
代码 | https://github.com/joaanna/something_else
主页 | https://joaanna.github.io/something_else/

深度视频的动作识别
3DV: 3D Dynamic Voxel for Action Recognition in Depth Video
作者 | Yancheng Wang, Yang Xiao, Fu Xiong, Wenxiang Jiang, Zhiguo Cao, Joey Tianyi Zhou, Junsong Yuan
单位 | 华中科技大学;旷视;A*STAR等
代码 | https://github.com/3huo/3DV-Action

基于骨架的动作识别
Skeleton-Based的动作识别,基于图卷积方法
Disentangling and Unifying Graph Convolutions for Skeleton-Based Action Recognition
作者 | Ziyu Liu, Hongwen Zhang, Zhenghao Chen, Zhiyong Wang, Wanli Ouyang
单位 | 悉尼大学;国科大&CASIA;悉尼大学计算机视觉研究小组
代码 | https://github.com/kenziyuliu/ms-g3d

Skeleton-Based动作识别,Shift Graph卷积网络方法
Skeleton-Based Action Recognition With Shift Graph Convolutional Network
作者 | Ke Cheng, Yifan Zhang, Xiangyu He, Weihan Chen, Jian Cheng, Hanqing Lu
单位 | 中科院;国科大等
代码 | https://github.com/kchengiva/Shift-GCN
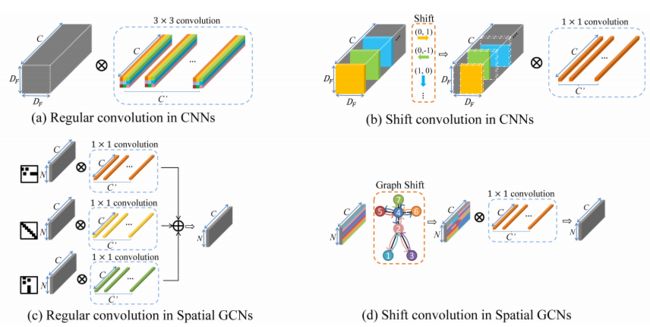
无监督Skeleton-Based的动作识别。该文提出一种编码器-解码器的RNN模型,可进行无监督的聚类,而此聚类结果可关联动作的类别,即也可以可以堪为预测。
此无监督方法在基于骨架的动作识别中取得了与监督学习方法相相近的精度!
(也许表明:人体动作本身类间差异就足够大?)
PREDICT & CLUSTER: Unsupervised Skeleton Based Action Recognition
作者 | Kun Su, Xiulong Liu, Eli Shlizerman
单位 | 华盛顿大学
代码 | https://github.com/shlizee/Predict-Cluster

语义引导的神经网络,用于Skeleton-Based人类动作识别,SGN 方案仅需非常小的参数量(仅0.69M)就实现了很高的识别精度。
Semantics-Guided Neural Networks for Efficient Skeleton-Based Human Action Recognition
作者 | Pengfei Zhang, Cuiling Lan, Wenjun Zeng, Junliang Xing, Jianru Xue, Nanning Zheng
单位 | 西安交通大学;微软亚洲研究院;中科院自动化所
代码 | https://github.com/microsoft/SGN
解读 | CVPR 2020丨微软亚洲研究院精选论文一览
上下文感知的图卷积,用于Skeleton-Based动作识别
Context Aware Graph Convolution for Skeleton-Based Action Recognition
作者 | Xikun Zhang, Chang Xu, Dacheng Tao
单位 | UBTECH Sydney AI Centre;悉尼大学

数据集
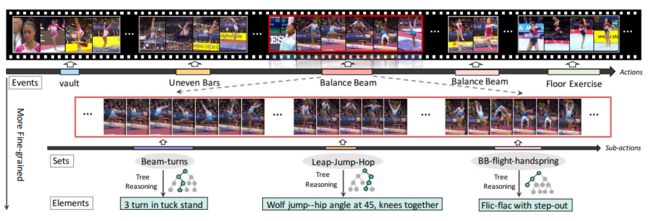
面向细粒度动作分析的层级化高质量数据集
FineGym: A Hierarchical Video Dataset for Fine-Grained Action Understanding
作者 | Dian Shao, Yue Zhao, Bo Dai, Dahua Lin
单位 | 香港中文大学与商汤联合实验室
代码/数据 | https://sdolivia.github.io/FineGym/
备注 | CVPR2020 Oral ,评审满分论文
解读 | https://zhuanlan.zhihu.com/p/130720627
往期"精彩阅读"
CVPR 2020 论文大盘点-超分辨篇
CVPR 2020 论文大盘点-图像与视频检索篇
CVPR 2020 论文大盘点-目标检测篇
CVPR 2020 论文大盘点-人脸技术篇
CVPR 2020 论文大盘点-目标跟踪篇
CVPR 2020 论文大盘点-文本图像篇
CVPR 2020 论文大盘点-语义分割篇
CVPR 2020 论文大盘点-实例分割篇
CVPR 2020 论文大盘点-图像分割完整篇
CVPR 2020 论文大盘点-抠图Matting篇
CVPR 2020 论文大盘点-图像质量评价篇
CVPR 2020 论文大盘点-去雨去雾去模糊篇
CVPR 2020 论文大盘点-图像增强与图像恢复篇
CVPR 2020 论文大盘点-图像修复Inpainting篇
CVPR 2020 论文大盘点-行人检测与重识别篇
CVPR 2020 论文大盘点-全景分割与视频目标分割篇
CVPR 2020 论文大盘点-医学影像处理识别篇
CVPR 2020 论文大盘点-遥感与航拍影像处理识别篇
CVPR 2020 论文大盘点-人体姿态估计与动作捕捉篇

备注:动作

人体动作检测与识别交流群
动作识别、动作检测等技术,
若已为CV君其他账号好友请直接私信。
我爱计算机视觉
微信号:aicvml
QQ群:805388940
微博知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到 