定义:bool是一种数据类型取值为false或者true定义:boolisFind=true;内存大小占一个字节使用bool的一些使用举例#includeusingnamespacestd;boolfun(inta,intb){returna+b>=10;}intmain(){boola=true;cout<
Ehcache、Caffeine、Spring Cache、Redis、J2Cache、Memcached 和 Guava Cache 的主要区别
MonkeyKing.sun
springredismemcached
主流缓存技术Ehcache、Caffeine、SpringCache、Redis、J2Cache、Memcached和GuavaCache的主要区别,涵盖其架构、功能、适用场景和优缺点等方面:Ehcache类型:本地缓存(JVM内存缓存)特点:轻量级,运行在JVM内部,易于集成到Java应用中。支持堆内、堆外和磁盘缓存,适合处理中小型数据集。提供丰富的缓存配置,如TTL(生存时间)、TTI(空闲时
《高并发系统性能优化三板斧:缓存 + 异步 + 限流》
猕员桃
10篇关于分布式和高并发性能优化缓存
高并发系统性能优化三板斧:缓存+异步+限流引言在互联网应用的高并发场景下,系统性能面临巨大挑战。以某电商平台会员活动为例,活动期间瞬时QPS可达10万+,若未进行有效优化,服务器将迅速崩溃。本文从缓存、异步、限流三个核心维度,结合实际案例详细解析高并发系统的性能优化策略,并分享全链路压测与问题定位的实战经验。一、缓存策略分层:从本地到分布式的立体防护1.1本地缓存选型与实战(Caffeine)本地
2.6 Spring Boot缓存实战:Redis与Caffeine性能对比
SpringBoot缓存实战:Redis与Caffeine深度性能对比一、缓存技术选型核心指标维度Redis(分布式)Caffeine(本地)数据存储位置独立内存服务器应用进程堆内存数据一致性强一致(集群版)最终一致(需额外同步)网络开销存在TCP/IP通信无网络延迟数据容量支持TB级存储受限于JVM堆大小数据结构支持5种核心数据结构仅Key-Value结构持久化能力RDB/AOF需结合其他存储二
NLP入门笔记
ShaneHolmes
自然语言处理深度学习机器学习
1、入门CNN能够有效地在上下文中挖掘语义信息,但是无法对远距离上下文信息进行建模,也无法处理词汇的顺序信息。与CNN不同,RNN(循环)可以处理词汇的顺序信息,并且具有灵活的计算步骤,可以提供更好的建模能力。由于RNN容易出现梯度消失的问题,对其进行改进的LSTM网络开始流行。此外,由于计算能力有限导致信息超载问题严重,注意力机制作为一种资源分配方案,通过将计算资源分配给更重要的任务,有效缓解了
深入实践Caffeine+Redis两级缓存架构:从原理到高可用设计
搬砖的小熊猫
缓存redis架构
一、为何需要两级缓存架构?在分布式系统中,Redis作为分布式缓存已广泛应用。但当系统面临超高并发读取(如热点商品详情页访问)或超低延迟要求(如金融行情数据推送)时,纯远程缓存面临两大瓶颈:网络IO开销:每次Redis访问需10-50ms的网络延迟带宽瓶颈:单节点Redis吞吐量上限约10万QPS通过引入Caffeine本地缓存作为一级缓存,Redis作为二级缓存,可实现:命中未命中命中未命中客户
python opencv rgb_opencv-python的RGB与BGR互转方式
weixin_39798497
pythonopencvrgb
一、格式转换opencv读取图片的默认像素排列是BGR,需要转换。PIL库是RGB格式。caffe底层的图像处理是基于opencv,其使用的颜色通道顺序与也是BGR(Blue-Green-Red),而日常图片存储时颜色通道顺序是RGB。在Python中,将RGB顺序的图像转成BGR顺序,需要调整channeldimension的各颜色通道顺序。方法1:img=cv2.imread("001.jpg
caffe之利用mnist数据集训练好的lenet_iter_10000.caffemodel模型测试一张自己的手写体数字
xunan003
深度学习caffe
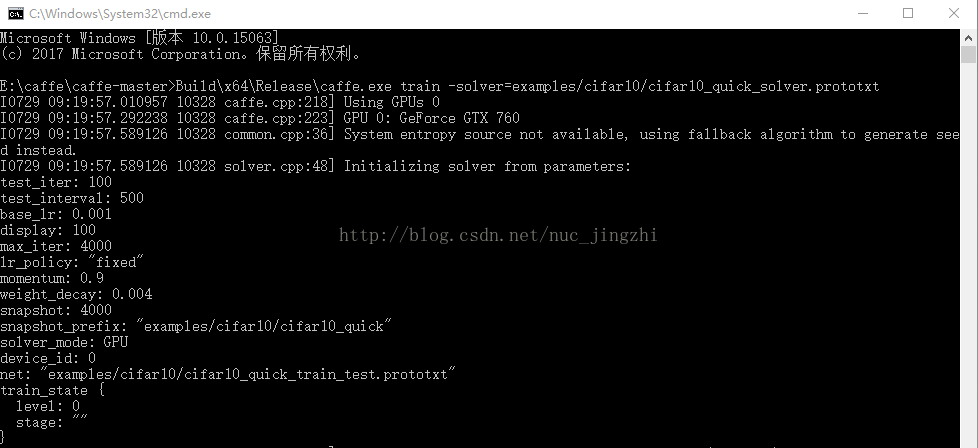
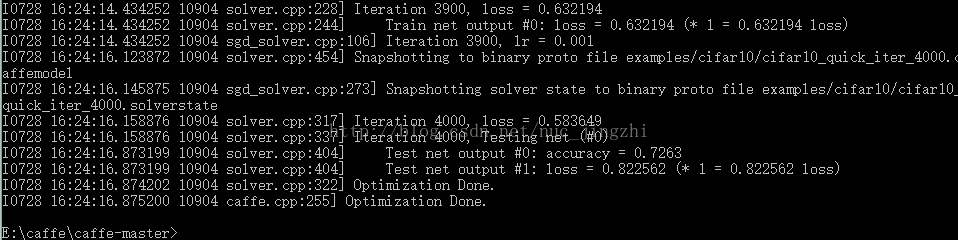
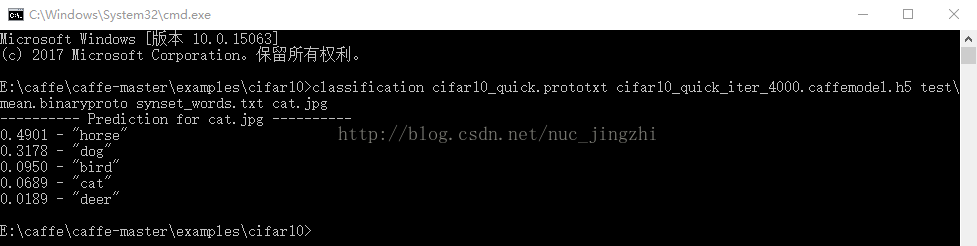
一、前沿写这篇博文,是因为一开始在做《21天学习caffe》第6天6.4练习题1的时候看着自己搜索的博文,在不理解其根本的情况下做的,结果显然是错的。在接下来阅读完源代码之后,在第10天学习完caffemodelzoo之后,明白了其中原理,反过来再去做那个习题,一开始在网上搜索并没有完完整整解释整个过程的一篇博文,而是写的不知所云,本着我们初学者互相共享的精神,也方便自己查阅,特详细写一下,将自己
caffe安装:基于anaconda3---python3.6, linux, 仅CPU
喵酱ooo
目标检测caffeanaconda3python3.6linuxCPU
caffe安装:基于anaconda3---python3.6,linux,仅CPUcaffe安装安装Anaconda3下载caffe配置caffe的Makefile.config安装libboost(基于python3.6)的库编译caffecaffe安装安装Anaconda3下载:Anaconda3-5.0.1-Linux-x86_64.sh默认路径安装(最终安装位置为/home/usenam
ubuntu 编译caffe makefile.config
AI算法网奇
win/ubuntu
这个是我以前总结的:sudoapt-getinstall-ylibopencv-devpython-opencvsudoapt-getinstall-ybuild-essentialcmakegitpkg-configsudoapt-getinstall-ylibatlas-base-devsudoapt-getinstall-ylibgflags-devlibgoogle-glog-devlib
caffe中Makefile.config详解
《一夜飘零》
##Refertohttp://caffe.berkeleyvision.org/installation.html#Contributionssimplifyingandimprovingourbuildsystemarewelcome!#cuDNNaccelerationswitch(uncommenttobuildwithcuDNN).#USE_CUDNN:=1"CuDNN是NVIDIA专门
【性能飙升】Caffeine缓存框架:SpringBoot的高性能秘籍!
码农Q!
程序员JavaIT缓存springbootspringwindows开发语言javalist
高性能Java本地缓存Caffeine框架介绍及在SpringBoot中的使用代码加详解1.引包importcom.github.benmanes.caffeine.cache.Cache;importcom.github.benmanes.caffeine.cache.Caffeine;importorg.springframework.beans.factory.annotation.Auto
一站式讲解本地缓存Caffeine
想用offer打牌
后台缓存缓存
文章目录theme:condensed-night-purple引言本地缓存的必要性多级缓存访问流程使用Caffeine作为本地缓存️添加**SpringCache和Guava依赖**配置Caffeine缓存启用缓存使用缓存注解总结❤️theme:condensed-night-purple引言上次我们讲了本地缓存guava,那么有没有比它更加优秀的本地缓存呢?有的,兄弟,有的。这次我们来讲本地
开放词汇检测分割YOLOE从pytorch到caffe
wangxiaobei2017
深度学习训练与移植pytorchcaffe人工智能
开放词汇检测分割YOLOE从pytorch到caffe0.前沿开放词汇检测的概念CLIP模型1.YOLOE环境配置1.1虚拟环境1.2YOLOE模型推理测试1.2.1文本提示检测和分割测试1.2.2无提示检测和分割2.YOLOE网络结构分析2.1网络结构概述2.2可重参数化区域-文本对齐(Re-parameterizableregion-textalignment:RepRTA)2.3语义激活视觉
吴恩达机器学习入门笔记(Week 1)
冒冒喵
吴恩达机器学习入门机器学习笔记人工智能
吴恩达机器学习Week1学习资源及工具机器学习分类专业术语(Terminology)线性回归模型(Linearregression)代价函数(costfunction)学习资源及工具1、课程资源:B站大学2、相关工具:Jupter&Github3、书籍资源:神经网络与深度学习(MichaelNielsen)、机器学习(周志华)、统计学习方法(李航)…机器学习分类1、监督学习(supervisedl
本地缓存Caffeine的基本使用
海光之蓝
工具类spring
1.本地缓存有ehcache,guavacache,caffein这几种常用的实现,下面介绍caffeine在springboot中的使用caffeine官网:github-caffeinjsr-107缓存规范与spring的对照:jsr-107缓存规范与spring的对照caffeine-plus:caffeine-plus单独使用:2.添加依赖com.github.ben-manes.caff
Linux 里 su 和 sudo 命令这两个有什么不一样?
小菜狗编程笔记
linux服务器ubuntu嵌入式centos单片机运维
《小菜狗Linux操作系统快速入门笔记》目录:《小菜狗Linux操作系统快速入门笔记》(01.0)文章导航目录【实时更新】Linux是一个多用户的操作系统。在Linux中,理论上来说,我们可以创建无数个用户,但是这些用户是被划分到不同的群组里面的,有一个用户,名叫root,是一个很特殊的用户,它是超级用户,拥有最高权限。但是在大多数版本的Unix/Linux中,都不推荐直接使用root账号登录系统
Web 架构之缓存策略实战:从本地缓存到分布式缓存
互联网搬砖工老肖
web架构原力计划前端架构缓存
文章目录一、思维导图二、正文内容(一)本地缓存1.简介2.常见实现3.使用场景4.优缺点(二)分布式缓存1.简介2.常见实现3.使用场景4.优缺点5.缓存问题及解决方案三、总结一、思维导图缓存策略实战本地缓存分布式缓存简介常见实现使用场景优缺点GuavaCacheCaffeine简介常见实现使用场景优缺点RedisMemcached缓存穿透缓存击穿缓存雪崩解决方案解决方案解决方案二、正文内容(一)
《小菜狗 Linux 操作系统快速入门笔记》(05.5)文件与目录管理命令【最新最全总结 - ls cd mkdir rmdir cp rm mv等命令】
小菜狗编程笔记
《小菜狗Linux操作系统快速入门笔记》linux服务器ubuntucentos操作系统ls命令cp命令
目录1、总结【重要】2、列出路径下的文件与目录命令【ls】3、以树状图列出路径下的文件与目录命令【tree】4、切换目录命令【cd】5、创建新目录命令【mkdir】6、删除空目录命令【rmdir】7、创建新文件命令【touch】8、复制文件或目录命令【cp】9、删除文件或目录命令【rm】10、移动文件与目录命令【mv】11、显示当前目录路径命令【pwd】12、查看命令可执行文件的所在路径命令【wh
解锁Java多级缓存:性能飞升的秘密武器
bxlj_jcj
缓存面试架构缓存架构java面试
一、引言文末有彩蛋在当今高并发、低延迟的应用场景中,传统的单级缓存策略往往难以满足性能需求。随着系统规模扩大,数据访问的瓶颈逐渐显现,如何高效管理缓存成为开发者面临的重大挑战。多级缓存架构应运而生,通过分层缓存设计(如本地缓存+分布式缓存+后端存储),显著减少网络开销、降低数据库压力,成为提升Java应用性能的“秘密武器”。本文将深入剖析多级缓存的核心理念,结合Caffeine、Redis等主流技
Spring Boot缓存组件Ehcache、Caffeine、Redis、Hazelcast
一只帆記
SpringBoot缓存springbootredis
一、SpringBoot缓存架构核心SpringBoot通过spring-boot-starter-cache提供统一的缓存抽象层:业务代码CacheAbstractionCacheManagerCacheImplementationEhcacheCaffeineRedisHazelcast二、主流缓存工具深度对比特性EhcacheCaffeineRedisHazelcast类型本地缓存本地缓存分
【Redis】热点key问题,的原因和处理,一致性哈希,删除大key的方法
{⌐■_■}
redisredis哈希算法数据库
热点Key指单个Key被高并发访问(如爆款商品),导致Redis压力骤增。解决方案应针对“单个Key高并发”:分片缓存:将热点Key分散到不同Redis节点(如按一致性哈希算法分片)。本地缓存:在应用层缓存热点数据(如Caffeine),减少Redis压力。增加缓存副本:为热点数据增加缓存副本,将热点数据复制到多个缓存节点上,分散访问压力。(例如,使用Redis的主从复制,将热点数据存储在多个从节
解读Servlet原理篇二---GenericServlet与HttpServlet
周凡杨
javaHttpServlet源理GenericService源码
在上一篇《解读Servlet原理篇一》中提到,要实现javax.servlet.Servlet接口(即写自己的Servlet应用),你可以写一个继承自javax.servlet.GenericServletr的generic Servlet ,也可以写一个继承自java.servlet.http.HttpServlet的HTTP Servlet(这就是为什么我们自定义的Servlet通常是exte
MySQL性能优化
bijian1013
数据库mysql
性能优化是通过某些有效的方法来提高MySQL的运行速度,减少占用的磁盘空间。性能优化包含很多方面,例如优化查询速度,优化更新速度和优化MySQL服务器等。本文介绍方法的主要有:
a.优化查询
b.优化数据库结构
ThreadPool定时重试
dai_lm
javaThreadPoolthreadtimertimertask
项目需要当某事件触发时,执行http请求任务,失败时需要有重试机制,并根据失败次数的增加,重试间隔也相应增加,任务可能并发。
由于是耗时任务,首先考虑的就是用线程来实现,并且为了节约资源,因而选择线程池。
为了解决不定间隔的重试,选择Timer和TimerTask来完成
package threadpool;
public class ThreadPoolTest {
Oracle 查看数据库的连接情况
周凡杨
sqloracle 连接
首先要说的是,不同版本数据库提供的系统表会有不同,你可以根据数据字典查看该版本数据库所提供的表。
select * from dict where table_name like '%SESSION%';
就可以查出一些表,然后根据这些表就可以获得会话信息
select sid,serial#,status,username,schemaname,osuser,terminal,ma
类的继承
朱辉辉33
java
类的继承可以提高代码的重用行,减少冗余代码;还能提高代码的扩展性。Java继承的关键字是extends
格式:public class 类名(子类)extends 类名(父类){ }
子类可以继承到父类所有的属性和普通方法,但不能继承构造方法。且子类可以直接使用父类的public和
protected属性,但要使用private属性仍需通过调用。
子类的方法可以重写,但必须和父类的返回值类
android 悬浮窗特效
肆无忌惮_
android
最近在开发项目的时候需要做一个悬浮层的动画,类似于支付宝掉钱动画。但是区别在于,需求是浮出一个窗口,之后边缩放边位移至屏幕右下角标签处。效果图如下:
一开始考虑用自定义View来做。后来发现开线程让其移动很卡,ListView+动画也没法精确定位到目标点。
后来想利用Dialog的dismiss动画来完成。
自定义一个Dialog后,在styl
hadoop伪分布式搭建
林鹤霄
hadoop
要修改4个文件 1: vim hadoop-env.sh 第九行 2: vim core-site.xml <configuration> &n
gdb调试命令
aigo
gdb
原文:http://blog.csdn.net/hanchaoman/article/details/5517362
一、GDB常用命令简介
r run 运行.程序还没有运行前使用 c cuntinue
Socket编程的HelloWorld实例
alleni123
socket
public class Client
{
public static void main(String[] args)
{
Client c=new Client();
c.receiveMessage();
}
public void receiveMessage(){
Socket s=null;
BufferedRea
线程同步和异步
百合不是茶
线程同步异步
多线程和同步 : 如进程、线程同步,可理解为进程或线程A和B一块配合,A执行到一定程度时要依靠B的某个结果,于是停下来,示意B运行;B依言执行,再将结果给A;A再继续操作。 所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回,同时其它线程也不能调用这个方法
多线程和异步:多线程可以做不同的事情,涉及到线程通知
&
JSP中文乱码分析
bijian1013
javajsp中文乱码
在JSP的开发过程中,经常出现中文乱码的问题。
首先了解一下Java中文问题的由来:
Java的内核和class文件是基于unicode的,这使Java程序具有良好的跨平台性,但也带来了一些中文乱码问题的麻烦。原因主要有两方面,
js实现页面跳转重定向的几种方式
bijian1013
JavaScript重定向
js实现页面跳转重定向有如下几种方式:
一.window.location.href
<script language="javascript"type="text/javascript">
window.location.href="http://www.baidu.c
【Struts2三】Struts2 Action转发类型
bit1129
struts2
在【Struts2一】 Struts Hello World http://bit1129.iteye.com/blog/2109365中配置了一个简单的Action,配置如下
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configurat
【HBase十一】Java API操作HBase
bit1129
hbase
Admin类的主要方法注释:
1. 创建表
/**
* Creates a new table. Synchronous operation.
*
* @param desc table descriptor for table
* @throws IllegalArgumentException if the table name is res
nginx gzip
ronin47
nginx gzip
Nginx GZip 压缩
Nginx GZip 模块文档详见:http://wiki.nginx.org/HttpGzipModule
常用配置片段如下:
gzip on; gzip_comp_level 2; # 压缩比例,比例越大,压缩时间越长。默认是1 gzip_types text/css text/javascript; # 哪些文件可以被压缩 gzip_disable &q
java-7.微软亚院之编程判断俩个链表是否相交 给出俩个单向链表的头指针,比如 h1 , h2 ,判断这俩个链表是否相交
bylijinnan
java
public class LinkListTest {
/**
* we deal with two main missions:
*
* A.
* 1.we create two joined-List(both have no loop)
* 2.whether list1 and list2 join
* 3.print the join
Spring源码学习-JdbcTemplate batchUpdate批量操作
bylijinnan
javaspring
Spring JdbcTemplate的batch操作最后还是利用了JDBC提供的方法,Spring只是做了一下改造和封装
JDBC的batch操作:
String sql = "INSERT INTO CUSTOMER " +
"(CUST_ID, NAME, AGE) VALUES (?, ?, ?)";
[JWFD开源工作流]大规模拓扑矩阵存储结构最新进展
comsci
工作流
生成和创建类已经完成,构造一个100万个元素的矩阵模型,存储空间只有11M大,请大家参考我在博客园上面的文档"构造下一代工作流存储结构的尝试",更加相信的设计和代码将陆续推出.........
竞争对手的能力也很强.......,我相信..你们一定能够先于我们推出大规模拓扑扫描和分析系统的....
base64编码和url编码
cuityang
base64url
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.io.StringWriter;
import java.io.UnsupportedEncodingException;
web应用集群Session保持
dalan_123
session
关于使用 memcached 或redis 存储 session ,以及使用 terracotta 服务器共享。建议使用 redis,不仅仅因为它可以将缓存的内容持久化,还因为它支持的单个对象比较大,而且数据类型丰富,不只是缓存 session,还可以做其他用途,一举几得啊。1、使用 filter 方法存储这种方法比较推荐,因为它的服务器使用范围比较多,不仅限于tomcat ,而且实现的原理比较简
Yii 框架里数据库操作详解-[增加、查询、更新、删除的方法 'AR模式']
dcj3sjt126com
数据库
public function getMinLimit () { $sql = "..."; $result = yii::app()->db->createCo
solr StatsComponent(聚合统计)
eksliang
solr聚合查询solr stats
StatsComponent
转载请出自出处:http://eksliang.iteye.com/blog/2169134
http://eksliang.iteye.com/ 一、概述
Solr可以利用StatsComponent 实现数据库的聚合统计查询,也就是min、max、avg、count、sum的功能
二、参数
百度一道面试题
greemranqq
位运算百度面试寻找奇数算法bitmap 算法
那天看朋友提了一个百度面试的题目:怎么找出{1,1,2,3,3,4,4,4,5,5,5,5} 找出出现次数为奇数的数字.
我这里复制的是原话,当然顺序是不一定的,很多拿到题目第一反应就是用map,当然可以解决,但是效率不高。
还有人觉得应该用算法xxx,我是没想到用啥算法好...!
还有觉得应该先排序...
还有觉
Spring之在开发中使用SpringJDBC
ihuning
spring
在实际开发中使用SpringJDBC有两种方式:
1. 在Dao中添加属性JdbcTemplate并用Spring注入;
JdbcTemplate类被设计成为线程安全的,所以可以在IOC 容器中声明它的单个实例,并将这个实例注入到所有的 DAO 实例中。JdbcTemplate也利用了Java 1.5 的特定(自动装箱,泛型,可变长度
JSON API 1.0 核心开发者自述 | 你所不知道的那些技术细节
justjavac
json
2013年5月,Yehuda Katz 完成了JSON API(英文,中文) 技术规范的初稿。事情就发生在 RailsConf 之后,在那次会议上他和 Steve Klabnik 就 JSON 雏形的技术细节相聊甚欢。在沟通单一 Rails 服务器库—— ActiveModel::Serializers 和单一 JavaScript 客户端库——&
网站项目建设流程概述
macroli
工作
一.概念
网站项目管理就是根据特定的规范、在预算范围内、按时完成的网站开发任务。
二.需求分析
项目立项
我们接到客户的业务咨询,经过双方不断的接洽和了解,并通过基本的可行性讨论够,初步达成制作协议,这时就需要将项目立项。较好的做法是成立一个专门的项目小组,小组成员包括:项目经理,网页设计,程序员,测试员,编辑/文档等必须人员。项目实行项目经理制。
客户的需求说明书
第一步是需
AngularJs 三目运算 表达式判断
qiaolevip
每天进步一点点学习永无止境众观千象AngularJS
事件回顾:由于需要修改同一个模板,里面包含2个不同的内容,第一个里面使用的时间差和第二个里面名称不一样,其他过滤器,内容都大同小异。希望杜绝If这样比较傻的来判断if-show or not,继续追究其源码。
var b = "{{",
a = "}}";
this.startSymbol = function(a) {
Spark算子:统计RDD分区中的元素及数量
superlxw1234
sparkspark算子Spark RDD分区元素
关键字:Spark算子、Spark RDD分区、Spark RDD分区元素数量
Spark RDD是被分区的,在生成RDD时候,一般可以指定分区的数量,如果不指定分区数量,当RDD从集合创建时候,则默认为该程序所分配到的资源的CPU核数,如果是从HDFS文件创建,默认为文件的Block数。
可以利用RDD的mapPartitionsWithInd
Spring 3.2.x将于2016年12月31日停止支持
wiselyman
Spring 3
Spring 团队公布在2016年12月31日停止对Spring Framework 3.2.x(包含tomcat 6.x)的支持。在此之前spring团队将持续发布3.2.x的维护版本。
请大家及时准备及时升级到Spring
fis纯前端解决方案fis-pure
zccst
JavaScript
作者:zccst
FIS通过插件扩展可以完美的支持模块化的前端开发方案,我们通过FIS的二次封装能力,封装了一个功能完备的纯前端模块化方案pure。
1,fis-pure的安装
$ fis install -g fis-pure
$ pure -v
0.1.4
2,下载demo到本地
git clone https://github.com/hefangshi/f