聚类算法4——DBSCAN密度聚类(算法步骤及matlab代码)
看了西关书的聚类算法,算法原理很容易明白,接下来就是整理成自己的理解思路,然后一步一步来实现算法,那么就来做吧。
DensityClustering算法
- 概念
从样本密度的角度考察样本之间的可连接性,样本分布的紧密程度刻画聚类结构
- 术语
核心对象:样本x_j的Δd邻域内至少包含MinPts个样本,称x_j为核心对象
密度直达:x_j邻域内的样本x_i,称x_j由x_i密度直达
密度可达:对于x_j和x_i,存在样本序列p1,p2,…pn,若p1=x_j,pn=x_i,p_i+1由p_i密度直达,x_j和x_i密度可达
密度相连:对于x_j和x_i,若存在x_k,使得x_i与x_j均由x_k密度可达,则x_j和x_i密度相连。
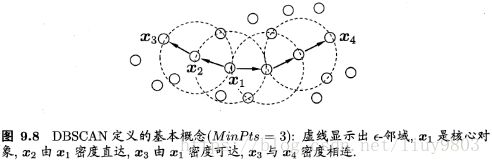
DBSCAN将簇定义为:由密度可达关系导出最大密度相连样本集合。
三、算法步骤
输入:样本集,邻域参数(邻域距离Δd,最小包含邻域样本个数MinPst)
输出:聚类簇划分
Step1、搜索核心对象集 search_objects()
输入:样本集D,邻域参数;输出:核心对象集
Step1.1载入数据集,初始化核心对象集、邻域参数
Step1.2 遍历样本,根据邻域参数,搜索核心对象,并添加到核心对象集合中
Setp2、密度聚类 density_clustering()
输入:核心对象集O,样本集T = D,邻域参数
输出:聚类簇个数k,聚类簇划分集C
Step2.1初始化聚类样本簇k=0;初始化未访问样本集合T =D;
Step2.2 repeat_Objects_clustering();源源不断的对核心对象集中的元素抽取以聚类原则工作
K=0;T=D;
While O != NULL
记录当前未访问的样本集合T_old = T
随机选取一个核心对象o∈O, 初始化队列Q = < o>
T=T\{o};
While Q!=NULL
取出队列Q中的首个样本q
If q的邻域样本个数>= MinPst
Δ = q的邻域样本
Q= {Q;Δ}
T = T\Δ
End if
End while Q
K = k+1; 生成聚类簇C_k = T_old\T
O = O\C_k
End whileO
DBSCAN代码下载链接
ok啦,我选择的是最小距离聚类方法,接下来不废话上代码(Matlab发布形式)
function Main()
clc
clear
close all
%step1
melon_data = load('melon4.0.txt');
melon_data(:,1)=[];
global delta_dist;
global min_pst;
delta_dist = 0.11; min_pst = 5;
object_set = search_objects(melon_data); %ok
%step2
[k_class,cluster_set]= repeat_Objects_clustering(melon_data,object_set);%ok
show(melon_data,cluster_set);
plot(object_set(:,1),object_set(:,2),'ro',...
'MarkerEdgeColor','k',...
'MarkerFaceColor','g',...
'MarkerSize',4)
fprintf('样本密度聚类个数为:%d\n',k_class);
end
subfunction
%step1
function object_set = search_objects(melon_data)
object_set = [];
for i= 1:length(melon_data)
[is_object, ~] = core_engin(melon_data,melon_data(i,:));
if is_object % including xi itself
object_set = [object_set;melon_data(i,:)];
end
end
end
%core engin
function [is_object, xi_object_samples] = core_engin(melon_data,xi_data)
% judge objects and get object samples
global delta_dist;
global min_pst;
is_object = 0;
xi_dist = pdist2(melon_data,xi_data);
min_pst_ind= find(xi_dist<=delta_dist);
if length(min_pst_ind) >= min_pst % including xi itself
is_object =1;
xi_object_samples = melon_data(min_pst_ind,:);
else
xi_object_samples =[];
end
end
%step2
function [k_class,cluster_set]= repeat_Objects_clustering(melon_data,object_set)
cluster_set.k_rows =[];
cluster_set.cluster =[];
k=0;
t_data = melon_data;
while ~isempty(object_set)
t_old_data = t_data; % not visit smample data
[OS_rows,~] = size(object_set);
Q = object_set(randi(OS_rows),:);
del_ind = search_same_data(t_data,Q);
t_data(del_ind,:)=[];
while ~isempty(Q)
[is_object, xi_object_samples] = core_engin(melon_data,Q(1,:));
if is_object %>=min_pst
delta_sample= set_across(t_data,xi_object_samples);
if ~isempty(delta_sample)
Q =[Q;delta_sample];
t_data = set_diff(t_data,delta_sample);
end
end
Q(1,:)=[];
end
k=k+1;
cur_cluster = set_diff(t_old_data,t_data);
object_set = set_diff(object_set,cur_cluster);
%store
[cur_cluster_rows,~] = size(cur_cluster);
cluster_set.k_rows =[cluster_set.k_rows;cur_cluster_rows];
cluster_set.cluster =[cluster_set.cluster;cur_cluster];
end
k_class = k;
end
function output_data = set_across(act_data,pas_data)
% this function is doing output_data = act_data ∩pas_data
output_data = [];
[PD_rows,~] = size(pas_data);
for i =1:PD_rows
delta_ind = search_same_data(act_data,pas_data(i,:));
if ~isempty(delta_ind)
output_data = [output_data;pas_data(i,:)];
else
continue;
end
end
end
function output_data = set_diff(act_data,pas_data)
%this function is set operation : output_data = act_data\pas_data去除操作
[m,~] = size(pas_data);
for i= 1:m
delta_ind = search_same_data(act_data,pas_data(i,:));
if ~isempty(delta_ind)
act_data(delta_ind,:) =[];
else
continue;
end
end
output_data = act_data;
end
function zero_ind = search_same_data(data,xi_data)
dist = pdist2(data,xi_data);
zero_ind = find(dist==0);
end
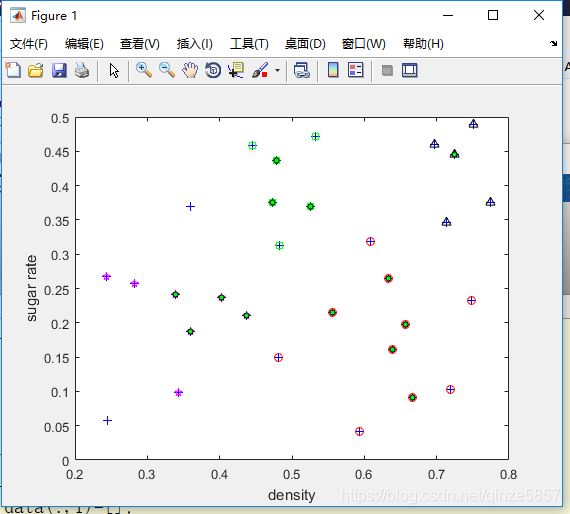
function show(melon_data,cluster_set)
plot(melon_data(:,1),melon_data(:,2),'+b');
hold on
cum_rows = cumsum(cluster_set.k_rows);
plot(cluster_set.cluster(1:cum_rows(1),1),cluster_set.cluster(1:cum_rows(1),2),'or');
plot(cluster_set.cluster(cum_rows(1)+1:cum_rows(2),1),cluster_set.cluster(cum_rows(1)+1:cum_rows(2),2),'sg');
plot(cluster_set.cluster(cum_rows(2)+1:cum_rows(3),1),cluster_set.cluster(cum_rows(2)+1:cum_rows(3),2),'^k');
plot(cluster_set.cluster(cum_rows(3)+1:end,1),cluster_set.cluster(cum_rows(3)+1:end,2),'pm');
xlabel('density');ylabel('sugar rate');
end
样本密度聚类个数为:4