以词搜图系统的一个改进版本
相对上次的改进
这次我们的改进,除了造出来更多的GUI界面以外,还可以在页面之间切换
加入了异常捕获,还增加了从网上搜索图片的功能
另外,文件路径不用手动输入辣,可以靠点击完成
然而套用百度API的问题仍然没有解决嘤嘤嘤
这个问题我暂时还真训练不出什么神经网络能够比百度API效果更好了草
不说了,跟各位分享分享我的代码吧
库导入
# -*- coding: utf-8 -*-
#导入包
#图形化
import tkinter as tk
from tkinter import filedialog
#文件夹
import os
#图像处理
from PIL import Image,ImageTk
import cv2
#数据处理
import pandas as pd
#OCR分析
from aip import AipOcr
#爬虫
import re
import urllib
from urllib import request
import requests
网络搜索的页面
网络搜索的页面我用一个类表示。我们会把爬取到的目标网址以链接的形式写入target.html文件中,用浏览器打开查看就可以了
GUI界面的背景图我在电脑里存着,background.jpg,是鬼灭之刃男女主的图片
#网页操作
class urlget():
def __init__(self):
#设计GUI界面布局
self.win=tk.Tk()
self.win.title("网络图片查询")
self.canvas=tk.Canvas(self.win,width=500,height=300,bd=0,highlightthickness=0)
self.imgpath='background.jpg'
self.img=Image.open(self.imgpath)
self.photo = ImageTk.PhotoImage(self.img)
self.canvas.create_image(300, 200, image=self.photo)
self.canvas.pack()
self.label=tk.Label(self.win,text="请输入您的关键词")
self.e1=tk.Variable()
self.entry=tk.Entry(self.win,textvariable=self.e1,insertbackground='blue', highlightthickness =2)
self.entry.pack()
self.b0=tk.Button(self.win,text="查询",command=self.searchurl)
self.b0.pack()
self.br=tk.Button(self.win,text='切换到本机',command=self.return_benji)
self.br.pack()
self.stp='查询完毕后请打开文件夹中target.html文件查看链接'
self.text2=tk.Text(self.win,width=30,height=1)
self.text2.insert(tk.INSERT,self.stp)
self.text2.pack()
def return_benji(self):#切换
self.win.destroy()
rename_next()
def searchurl(self):#利用爬虫技术查找网址
self.key=self.e1.get()
dat={'wrd':self.key}#关键词字典
self.key=urllib.parse.urlencode(dat)
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + self.key + '&ct=201326592&v=flip'#网址
url_request=request.Request(url)
url_response = request.urlopen(url_request) # 请求数据,可以和上一句合并
html = url_response.read().decode('utf-8') # 加编码,重要!转换为字符串编码,read()得到的是byte格式的。
jpglist = re.findall('"objURL":"(.*?)",',html,re.S) #re.S将字符串作为整体,在整体中进行匹配。
with open("target.html","w",encoding="utf-8")as f:#将链接写入HTML文件中,可以在浏览器打开
# 将爬取的页面
#print(html)
start='\n \n'
f.write(start)
count=1
for i in jpglist:
link=' +i+'">目标图片第%d张\n'%count
f.write(link)
count+=1
end=' \n'
f.write(end)
self.stp='查询完毕'
self.text2=tk.Text(self.win,width=30,height=1)
self.text2.insert(tk.INSERT,self.stp)
self.text2.pack()
#print(jpglist)
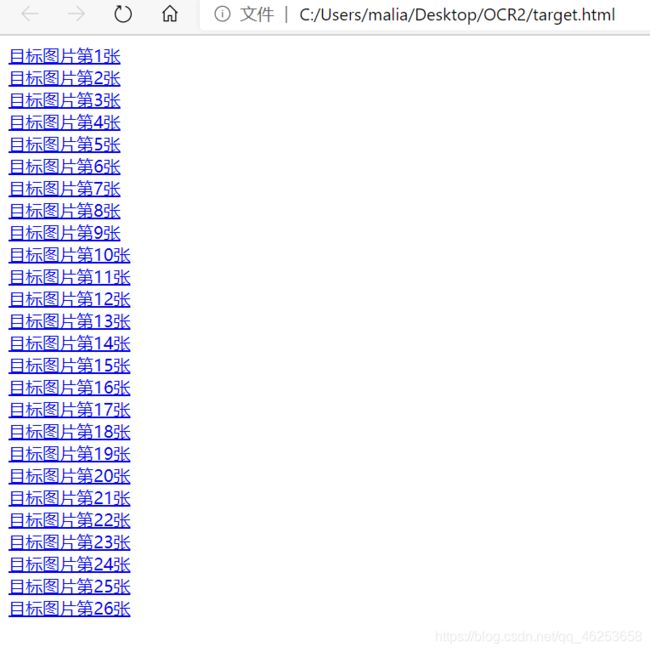
效果大概长这样吧这个HTML文件
本机的预处理操作
#重命名操作
class rename_next():
def __init__(self):
self.win=tk.Tk()
self.win.title("搜图")
self.canvas=tk.Canvas(self.win, width=500,height=300,bd=0, highlightthickness=0)
self.imgpath = 'background.jpg'
self.img = Image.open(self.imgpath)
self.photo = ImageTk.PhotoImage(self.img)
self.canvas.create_image(300, 200, image=self.photo)
self.canvas.pack()
self.label=tk.Label(self.win,text="亲爱的用户,如果您是初次使用,建议您先进行预处理操作。若非首次操作,可以进行下一步")
self.label.pack()
self.b3=tk.Button(self.win,text="预处理",command=self.rename)
self.b4=tk.Button(self.win,text="下一步",command=self.change2)
self.b3.pack()
self.b4.pack()
self.win.mainloop()
def rename(self):
#确定路径
path=folderpath
self.files=os.listdir(path)
self.i=0
#重命名
#要加一个断言调试
try:
for self.file in self.files:
#重命名
self.olddir=os.path.join(path,self.file)
self.filename=os.path.splitext(self.file)[0] #文件名
self.filetype=os.path.splitext(self.file)[1] #文件扩展名
self.Newdir=os.path.join(path,str(self.i)+'.jpg')
os.rename(self.olddir,self.Newdir)#重命名
self.i+=1
self.stp='文件预处理已经完毕'
self.text1=tk.Text(self.win,width=30,height=1)
self.text1.insert(tk.INSERT,self.stp)
self.text1.pack()
except FileExistsError as identifier:
self.stp='文件已经处理过'
self.text2=tk.Text(self.win,width=30,height=1)
self.text2.insert(tk.INSERT,self.stp)
self.text2.pack()
def change2(self):
self.win.destroy()
check_and_in()
重头戏,OCR识别
与上次一样,我们把本机的OCR图像识别内容存入一个csv文件
#OCR操作
class check_and_in():
def __init__(self):
self.win=tk.Tk()
self.win.title("搜图")
self.canvas=tk.Canvas(self.win, width=500,height=300,bd=0, highlightthickness=0)
self.imgpath = 'background.jpg'
self.img = Image.open(self.imgpath)
self.photo = ImageTk.PhotoImage(self.img)
self.canvas.create_image(300, 200, image=self.photo)
self.canvas.pack()
self.b5=tk.Button(self.win,text="OCR处理",command=self.ocr)
self.b6=tk.Button(self.win,text="查询",command=self.search)
self.label=tk.Label(self.win,text="请输入你的关键词")
self.e2=tk.Variable()
self.entry=tk.Entry(self.win,textvariable=self.e2,insertbackground='blue', highlightthickness =2)
self.b5.pack()
self.b6.pack()
self.b7=tk.Button(self.win,text="切换至网页",command=self.change_to_web)
self.b7.pack()
self.label.pack()
self.entry.pack()
def ocr(self):#等待优化中
self.APP_ID = '********'
self.API_KEY ='**************'
self.SECRET_KEY = '***************'
self.client= AipOcr(self.APP_ID, self.API_KEY, self.SECRET_KEY)#百度API直接套用,以后可以更改
self.path=folderpath
self.filelist=os.listdir(self.path)#打开文件夹
self.count=0
self.text=[]#文字内容
for self.file in self.filelist:
self.count+=1
for self.i in range(self.count):
self.file='%d.jpg'%self.i
self.image=self.get_file_content(self.path+'/'+self.file)
self.res=self.client.basicAccurate(self.image)
self.string=''
for self.item in self.res['words_result']:
self.string+=self.item['words']
self.text.append(self.string)
self.i+=1
#生成数据库
self.num=range(self.count)
self.number_column = pd.Series(self.num, name='number')
self.text_column = pd.Series(self.text, name='text')
self.predictions = pd.concat([self.number_column, self.text_column], axis=1)
self.save = pd.DataFrame({'number':self.num,'text':self.text})
self.save.to_csv('database.csv')
self.str='图片与OCR工作已经完成'
self.text1=tk.Text(self.win,width=30,height=1)
self.text1.insert(tk.INSERT,self.str)
self.text1.pack()
#网页端切换
def change_to_web(self):
self.win.destroy()
urlget()
#数据查询
def search(self):
#self.path=folderpath
self.path=folderpath
self.df=pd.read_csv('database.csv')
self.key=self.e2.get()
self.count=0
for self.i in self.df.text:
if self.key in self.i:
self.img=cv2.imread(self.path+'/%d.jpg'%self.count)
cv2.imshow("target",self.img)
cv2.waitKey()
cv2.destroyAllWindows()
self.count+=1
#内容读取
def get_file_content(self,filePath):
self.filePath=filePath
with open(self.filePath, 'rb') as fp:
return fp.read()
撒,开始实验吧
起始界面发现用类有超多的问题,就没有再用类了
#起始页面
if __name__=='__main__':
win=tk.Tk()
win.title("搜图")
canvas=tk.Canvas(win, width=500,height=300,bd=0, highlightthickness=0)
imgpath = 'background.jpg'
img = Image.open(imgpath)
photo = ImageTk.PhotoImage(img)
canvas.create_image(300, 200, image=photo)
canvas.pack()
label=tk.Label(win,text="请输入路径")
label.pack()
folderpath=filedialog.askdirectory()
def change1():
win.destroy()
#进入下一个界面
rename_next()
def change2():
win.destroy()
urlget()
b2=tk.Button(win,text="本机搜索下一步",command=change1)
b2.pack()
b3=tk.Button(win,text='网页端',command=change2)
b3.pack()
win.mainloop()
效果
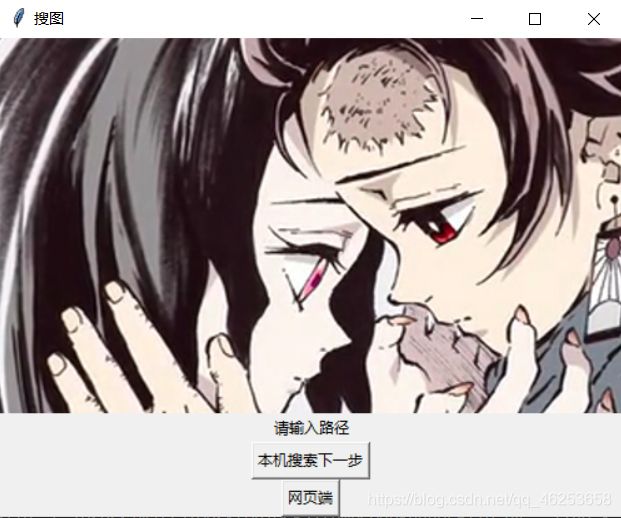
开始他就会打开文件夹让你挑文件路径,点击选择合适的路径就行
然后开始就是这个样子
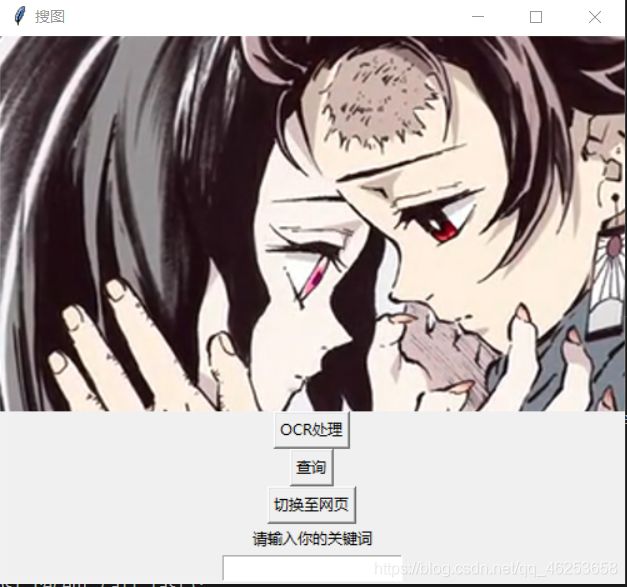
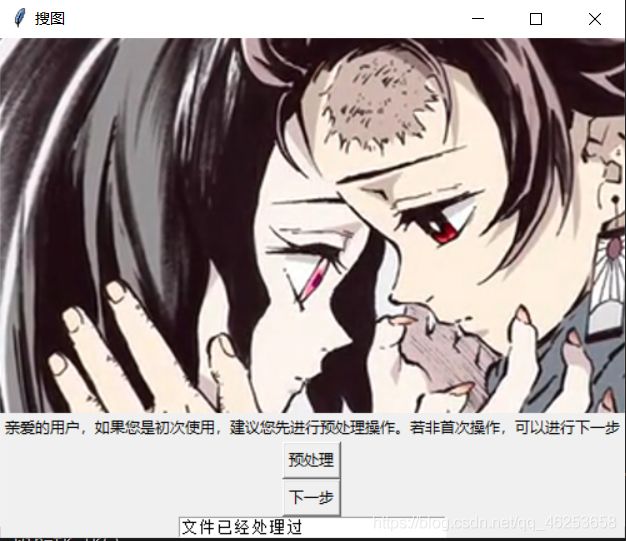
之后各大界面展示如下


希望各位多多支持,这是大一一个菜鸡唯一一个比较拿的出手的代码了真的
另外就是想蹲个大佬解释下能不能把类里面满天飞的self拿一些走真的是,看得我都特别烦