【机器学习】BP算法学习笔记
BP即Back Propagation的缩写,也就是反向传播的意思,顾名思义,将什么反向传播?一张动态图可以说明

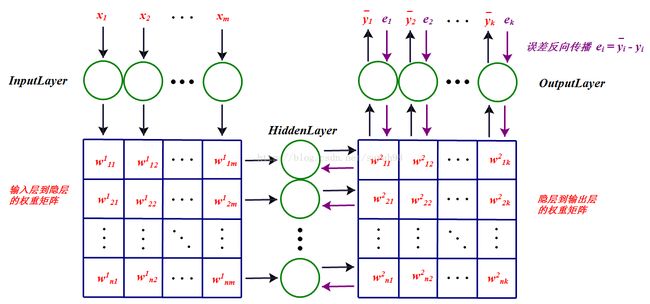
这个网络的工作原理应该很清楚了,首先,一组输入x1、x2、…、xm来到输入层,然后通过与隐层的连接权重产生一组数据s1、s2、…、sn作为隐层的输入,然后通过隐层节点的f(.)
激活函数后变为fi(e)f
其中sj表示隐层的第j个节点产生的输出,这些输出将通过隐层与输出层的连接权重产生输出层的输入,这里输出层的处理过程和隐层是一样的,最后会在输出层产生输出y¯j,这里j是指输出层第j个节点的输出。这只是前向传播的过程。
在这里,先解释一下隐层的含义,可以看到,隐层连接着输入和输出层,它到底是什么?它就是特征空间,隐层节点的个数就是特征空间的维数,或者说这组数据有多少个特征。而输入层到隐层的连接权重则将输入的原始数据投影到特征空间,比如sj就表示这组数据在特征空间中第j个特征方向的投影大小,或者说这组数据有多少份量的j特征。而隐层到输出层的连接权重表示这些特征是如何影响输出结果的,比如某一特征对某个输出影响比较大,那么连接它们的权重就会比较大。关于隐层的含义就解释这么多,至于多个隐层的,可以理解为特征的特征。
具体原理可以参照这篇文章
http://blog.csdn.net/zhongkejingwang/article/details/44514073
博客园博文http://www.cnblogs.com/21207-iHome/p/5227868.html
BP工作过程:
BP神经元示意图:
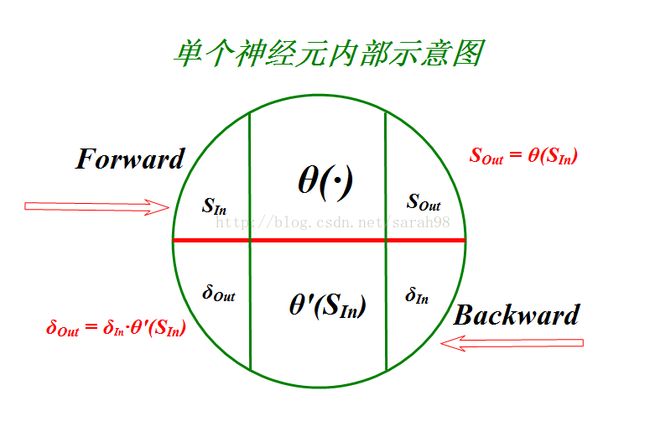
神经元主要功能:
- 计算数据,输出结果。
- 更新各连接权值。
- 向上一层反馈权值更新值,实现反馈功能。
BP神经网络基本思想
BP神经网络学习过程由信息的下向传递和误差的反向传播两个过程组成
正向传递:由模型图中的数据x从输入层到最后输出层z的过程。
反向传播:在训练阶段,如果正向传递过程中发现输出的值与期望的传有误差,由将误差从输出层返传回输入层的过程。返回的过程主要是修改每一层每个连接的权值w,达到减少误的过程。
BP神经网络设计
设计思路是将神经网络分为神经元、网络层及整个网络三个层次。
网络层设计
管理一个网络层的代码,分为隐藏层和输出层。 (输入层可直接用输入数据,不简单实现。)
网络层主要管理自己层的神经元,所以封装的结果与神经元的接口一样。对向实现自己的功能。
同时为了方便处理,添加了他下一层的引用。
Python实现:
import numpy as np
x = np.mat( '2,3,3,2,1,2,3,3,3,2,1,1,2,1,3,1,2;\
1,1,1,1,1,2,2,2,2,3,3,1,2,2,2,1,1;\
2,3,2,3,2,2,2,2,3,1,1,2,2,3,2,2,3;\
3,3,3,3,3,3,2,3,2,3,1,1,2,2,3,1,2;\
1,1,1,1,1,2,2,2,2,3,3,3,1,1,2,3,2;\
1,1,1,1,1,2,2,1,1,2,1,2,1,1,2,1,1;\
0.697,0.774,0.634,0.668,0.556,0.403,0.481,0.437,0.666,0.243,0.245,0.343,0.639,0.657,0.360,0.593,0.719;\
0.460,0.376,0.264,0.318,0.215,0.237,0.149,0.211,0.091,0.267,0.057,0.099,0.161,0.198,0.370,0.042,0.103\
').T
x = np.array(x)
y = np.mat('1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0')
y = np.array(y).T
'''
x = np.mat( '1,1,2,2;\
1,2,1,2\
').T
x = np.array(x)
y=np.mat('0,1,1,0')
y = np.array(y).T
'''
xrow, xcol = x.shape
yrow, ycol = y.shape
print ('x: ', x.shape, x)
print ('y: ', y.shape, y)
class BP:
def __init__(self, n_input, n_hidden_layer, n_output, learn_rate, error, n_max_train, value):
self.n_input = n_input
self.n_hidden_layer = n_hidden_layer
self.n_output = n_output
self.learn_rate = learn_rate
self.error = error
self.n_max_train = n_max_train
self.v = np.random.random((self.n_input, self.n_hidden_layer))
self.w = np.random.random((self.n_hidden_layer, self.n_output))
self.theta0 = np.random.random(self.n_hidden_layer)
self.theta1 = np.random.random(self.n_output)
self.b = []
self.yo = []
self.x = 0
self.y = 0
self.lossAll = []
self.lossAverage = 0
self.nRight = 0
self.value = value
def printParam(self):
print ('printParam')
print( '---------------')
print (' v: ', self.v)
print (' w: ', self.w)
print ('theta0: ', self.theta0)
print ('theta1: ', self.theta1)
print ('---------------')
def init(self, x, y):
#print 'init'
nx = len(x)
ny = len(y)
self.x = x
self.y = y
self.b = []
self.yo = []
for k in range(nx):
tmp = []
for h in range(self.n_hidden_layer):
tmp.append(0)
self.b.append(tmp)
tmp = []
for j in range(self.n_output):
tmp.append(0)
self.yo.append(tmp)
def printResult(self):
print( 'printResult')
self.calculateLossAll()
print('lossAll: ', self.lossAll)
print('lossAverage: ', self.lossAverage)
self.nRight = 0
for k in range(len(self.x)):
print(self.y[k], '----', self.yo[k])
self.nRight += 1
for j in range(self.n_output):
if(self.yo[k][j] > self.value[j][0] and self.y[k][j] != self.value[j][2]):
self.nRight -= 1
break
if(self.yo[k][j] < self.value[j][0] and self.y[k][j] != self.value[j][1]):
self.nRight -= 1
break
print( 'right rate: %d/%d'%(self.nRight, len(self.x)))
def printProgress(self):
print('yo: ', self.yo)
def calculateLoss(self, y, yo):
#print 'calculateLoss'
loss = 0
for j in range(self.n_output):
loss += (y[j] - yo[j])**2
return loss
def calculateLossAll(self):
self.lossAll = []
for k in range(len(self.x)):
loss = self.calculateLoss(self.y[k], self.yo[k])
self.lossAll.append(loss)
self.lossAverage = sum(self.lossAll) / len(self.x)
def calculateOutput(self, x, k):
#print 'calculateOutput'
for h in range(self.n_hidden_layer):
tmp = 0
for i in range(self.n_input):
tmp += self.v[i][h] * x[i]
self.b[k][h] = sigmoid(tmp - self.theta0[h])
for j in range(self.n_output):
tmp = 0
for h in range(self.n_hidden_layer):
tmp += self.w[h][j] * self.b[k][h]
self.yo[k][j] = sigmoid(tmp - self.theta1[j])
#print 'yo of x[k]', self.yo[k]
#print ' b of x[k]', self.b[k]
#print ' b:', self.b
#print 'yo:', self.yo
def sigmoid(x):
return 1.0 / (1.0 + np.exp(-1.0 * x))
class BPStandard(BP):
'''
标准bp算法就是每计算一个训练例就更新一次参数
'''
def updateParam(self, k):
#print 'updateParam: ', k
g = []
#print ' y: ', self.y
#print 'yo: ', self.yo
#print ' b: ', self.b
for j in range(self.n_output):
tmp = self.yo[k][j] * (1 - self.yo[k][j]) * (self.y[k][j] - self.yo[k][j])
g.append(tmp)
e = []
for h in range(self.n_hidden_layer):
tmp = 0
for j in range(self.n_output):
tmp += self.b[k][h] * (1.0 - self.b[k][h]) * self.w[h][j] * g[j]
e.append(tmp)
#print ' g: ', g
#print ' e: ', e
for h in range(self.n_hidden_layer):
for j in range(self.n_output):
self.w[h][j] += self.learn_rate * g[j] * self.b[k][h]
for j in range(self.n_output):
self.theta1[j] -= self.learn_rate * g[j]
for i in range(self.n_input):
for h in range(self.n_hidden_layer):
self.v[i][h] += self.learn_rate * e[h] * self.x[k][i]
for h in range(self.n_hidden_layer):
self.theta0[h] -= self.learn_rate * e[h]
def train(self, x, y):
print( 'train neural networks')
self.init(x, y)
self.printParam()
tag = 0
loss1 = 0
print('train begin:')
n_train = 0
nr = 0
while 1:
for k in range(len(x)):
n_train += 1
self.calculateOutput(x[k], k)
#loss = self.calculateLoss(y[k], self.yo[k])
self.calculateLossAll()
loss = self.lossAverage
#print 'k, y, yo, loss', k, y[k], self.yo[k], loss
if abs(loss1 - loss) < self.error:
nr += 1
if nr >= 100: # 连续100次达到目标才结束
break
else:
nr = 0
self.updateParam(k)
if n_train % 10000 == 0:
for k in range(len(x)):
self.calculateOutput(x[k], k)
self.printProgress()
if n_train > self.n_max_train or nr >= 100:
break
print('train end')
self.printParam()
self.printResult()
print ('train count: ', n_train)
class BPAll(BP):
def updateParam(self):
#print 'updateParam: ', k
g = []
#print ' y: ', self.y
#print 'yo: ', self.yo
#print ' b: ', self.b
for k in range(len(self.x)):
gk = []
for j in range(self.n_output):
tmp = self.yo[k][j] * (1 - self.yo[k][j]) * (self.y[k][j] - self.yo[k][j])
gk.append(tmp)
g.append(gk)
e = []
for k in range(len(self.x)):
ek = []
for h in range(self.n_hidden_layer):
tmp = 0
for j in range(self.n_output):
tmp += self.b[k][h] * (1.0 - self.b[k][h]) * self.w[h][j] * g[k][j]
ek.append(tmp)
e.append(ek)
#print ' g: ', g
#print ' e: ', e
for h in range(self.n_hidden_layer):
for j in range(self.n_output):
for k in range(len(self.x)):
self.w[h][j] += self.learn_rate * g[k][j] * self.b[k][h]
for j in range(self.n_output):
for k in range(len(self.x)):
self.theta1[j] -= self.learn_rate * g[k][j]
for i in range(self.n_input):
for h in range(self.n_hidden_layer):
for k in range(len(self.x)):
self.v[i][h] += self.learn_rate * e[k][h] * self.x[k][i]
for h in range(self.n_hidden_layer):
for k in range(len(self.x)):
self.theta0[h] -= self.learn_rate * e[k][h]
def train(self, x, y):
print('train neural networks')
self.init(x, y)
tag = 0
loss1 = 0
print('train begin:')
n_train = 0
self.printParam()
nr = 0
while 1:
n_train += 1
for k in range(len(x)):
self.calculateOutput(x[k], k)
self.calculateLossAll()
loss = self.lossAverage
if abs(loss - loss1) < self.error:
nr += 1
# 连续100次达到目标才结束
if(nr >= 100):
break;
else:
nr = 0
self.updateParam()
if n_train % 10000 == 0:
self.printProgress()
print('train end')
self.printParam()
self.printResult()
print('train count: ', n_train)
if __name__ == '__main__':
# 参数分别是 属性数量,隐层神经元数量,输出值数量,学习率,误差
# 最大迭代次数 以及 对应每个输出的取值(用于计算正确率)
n_input = xcol
n_hidden_layer = 10
n_output = ycol
learn_rate = 0.1
error = 0.005
n_max_train = 1000000
value = [[0.5, 0, 1]]
bps = BPStandard(n_input, n_hidden_layer, n_output, learn_rate, error, n_max_train, value)
bpa = BPAll(n_input, n_hidden_layer, n_output, learn_rate, error, n_max_train, value)
bpa.train(x, y)
#bps.train(x, y)