hadoop 集群配置(高可用)
hadoop集群高可用
- 配置三台虚拟机
- 先配置jdk和zookeeper
- 配置hadoop
配置三台虚拟机
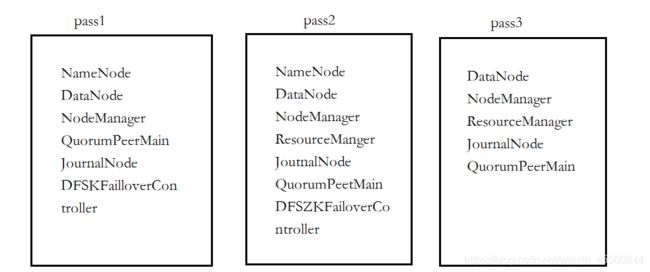
192.168.199.161 pass1
192.168.199.162 pass2
192.168.199.163 pass3
先配置jdk和zookeeper
见 jdk、zookeeper环境配置
配置hadoop
解压hadoop安装包
[root@pass1 install]# tar -zxvf ./hadoop-2.6.0-cdh5.14.2.tar.gz -C ../bigdata/
[root@pass1 install]# cd ../bigdata/
[root@pass1 bigdata]# ls
hadoop-2.6.0-cdh5.14.2 jdk180
[root@pass1 bigdata]# mv ./hadoop-2.6.0-cdh5.14.2/ hadoop260
进入/opt/bigdata/hadoop260/etc/hadoop 对如下文件进行配置
hadoop-env.sh
mapred-env.sh
yarn-env.sh
Slaves
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
hadoop-env.sh
export JAVA_HOME=/opt/bigdata/jdk180/
mapred-env.sh
export JAVA_HOME=/opt/bigdata/jdk180/
yarn-env.sh
export JAVA_HOME=/opt/bigdata/jdk180/
slaves
pass1
pass2
pass3
core-site.xml(配置完此步,需要在hadoop260目录下建hadoop2目录)
<!-- HDFS namenode地址 -->
fs.defaultFS</name>
hdfs://mycluster</value>
</property>
<!-- hadoop运行是存储路径 -->
hadoop.tmp.dir</name>
/opt/bigdata/hadoop260/hadoop2</value>
</property>
dfs.journalnode.edits.dir</name>
/opt/bigdata/hadoop260/hadoop2/jn</value>
</property>
hadoop.proxyuser.root.hosts</name>
*</value>
</property>
hadoop.proxyuser.root.groups</name>
*</value>
</property>
ha.zookeeper.quorum</name>
pass1:2181,pass2:2181,pass3:2181</value>
</property>
</configuration>
hdfs-site.xml
dfs.replication</name>
1</value>
</property>
dfs.nameservices</name>
mycluster</value>
</property>
dfs.ha.namenodes.mycluster</name>
nn1,nn2</value>
</property>
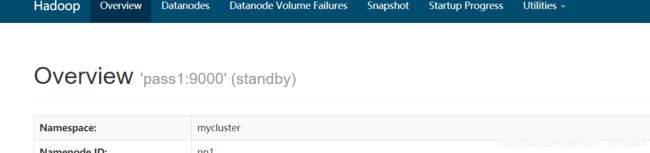
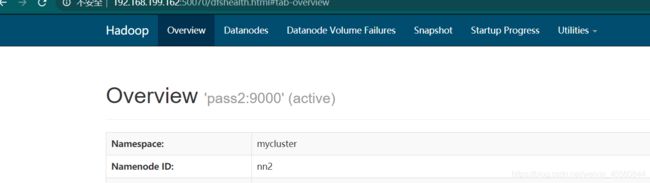
dfs.namenode.rpc-address.mycluster.nn1</name>
pass1:9000</value>
</property>
dfs.namenode.rpc-address.mycluster.nn2</name>
pass2:9000</value>
</property>
dfs.namenode.http-address.mycluster.nn1</name>
pass1:50070</value>
</property>
dfs.namenode.http-address.mycluster.nn2</name>
pass2:50070</value>
</property>
dfs.namenode.shared.edits.dir</name>
qjournal://pass1:8485;pass2:8485;pass3:8485/mycluster</value>
</property>
dfs.client.failover.proxy.provider.mycluster</name>
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
dfs.permissions.enable</name>
false</value>
</property>
dfs.ha.fencing.methods</name>
shell(/bin/true)</value>
</property>
dfs.ha.fencing.ssh.private-key-files</name>
/root/.ssh/id_rsa</value>
</property>
dfs.ha.automatic-failover.enabled</name>
true</value>
</property>
</configuration>
mapred-site.xml
[root@pass1 hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@pass1 hadoop]# vi mapred-site.xml
mapreduce.framework.name</name>
yarn</value>
</property>
mapreduce.jobhistory.address</name>
pass1:10020</value>
</property>
mapreduce.jobhistory.webapp.address</name>
pass1:19888</value>
</property>
</configuration>
yarn-site.xml
<!-- reducer获取数据方式 -->
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- 激活 RM 高可用 -->
yarn.resourcemanager.ha.enabled</name>
true</value>
</property>
<!-- 指定 RM 的集群 id -->
yarn.resourcemanager.cluster-id</name>
RM_CLUSTER</value>
</property>
<!-- 定义 RM 的节点-->
yarn.resourcemanager.ha.rm-ids</name>
rm1,rm2</value>
</property>
<!-- 指定 RM1 的地址 -->
yarn.resourcemanager.hostname.rm1</name>
pass2</value>
</property>
<!-- 指定 RM2 的地址 -->
yarn.resourcemanager.hostname.rm2</name>
pass3</value>
</property>
<!-- 激活 RM 自动恢复 -->
yarn.resourcemanager.recovery.enabled</name>
true</value>
</property>
<!-- 配置 RM 状态信息存储方式,有 MemStore 和 ZKStore-->
yarn.resourcemanager.store.class</name>
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 配置为 zookeeper 存储时,指定 zookeeper 集群的地址 -->
yarn.resourcemanager.zk-address</name>
pass1:2181,pass2:2181,pass3:2181</value>
</property>
<!-- 日志聚集功能使用 -->
yarn.log-aggregation-enable</name>
true</value>
</property>
<!-- 日志保留时间设置7天 -->
yarn.log-aggregation.retain-seconds</name>
604800</value>
</property>
</configuration>
hadoop环境变量配置
[root@pass1 hadoop]# vi /etc/profile.d/env.sh
export HADOOP_HOME=/opt/bigdata/hadoop260
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
[root@pass1 hadoop]# source /etc/profile.d/env.sh
往其他三个虚拟机传haoop及环境变量配置
[root@pass1 hadoop]# xrsync /etc/profile.d/env.sh
[root@pass1 bigdata]# xrsync hadoop260/
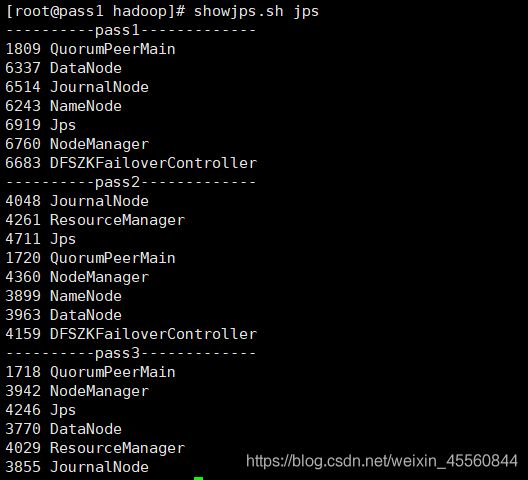
启动hadoop
在journalnode配置的节点上启动(我的三台都有journalnode)
hadoop-daemon.sh start journalnode
初始化namenode(pass1,pass2)
hadoop namenode -format
在namenode节点上启动(pass1、pass2)
hadoop-daemon.sh start namenode
主节点上启动
[root@pass1 hadoop260]# ./bin/hdfs namenode -bootstrapStandby
[root@pass1 hadoop260]# ./bin/hdfs zkfc -formatZK
[root@pass1 hadoop260]# ./sbin/stop-dfs.sh
[root@pass1 hadoop260]# ./sbin/start-dfs.sh
[root@pass1 hadoop260]# ./sbin/start-yarn.sh