DBSCAN聚类算法原理总结2
DBSCAN聚类算法三部分:
1、 DBSCAN原理、流程、参数设置、优缺点以及算法;
http://blog.csdn.net/zhouxianen1987/article/details/68945844
2、 matlab代码实现;
blog:http://blog.csdn.net/zhouxianen1987/article/details/68946169
code:http://download.csdn.net/detail/zhouxianen1987/9789230
3、 C++代码实现及与matlab实例结果比较。
blog:http://blog.csdn.net/zhouxianen1987/article/details/68946278
code:http://download.csdn.net/detail/zhouxianen1987/9789231
DBSCAN(Density-based spatial clustering ofapplications with noise)是Martin Ester, Hans-PeterKriegel等人于1996年提出的一种基于密度的空间的数据聚类方法,该算法是最常用的一种聚类方法[1,2]。该算法将具有足够密度区域作为距离中心,不断生长该区域,算法基于一个事实:一个聚类可以由其中的任何核心对象唯一确定[4]。该算法利用基于密度的聚类的概念,即要求聚类空间中的一定区域内所包含对象(点或其他空间对象)的数目不小于某一给定阈值。该方法能在具有噪声的空间数据库中发现任意形状的簇,可将密度足够大的相邻区域连接,能有效处理异常数据,主要用于对空间数据的聚类,优缺点总结如下[3,4]:
优点:
(1)聚类速度快且能够有效处理噪声点和发现任意形状的空间聚类;
(2)与K-MEANS比较起来,不需要输入要划分的聚类个数;
(3)聚类簇的形状没有偏倚;
(4)可以在需要时输入过滤噪声的参数。
缺点:
(1)当数据量增大时,要求较大的内存支持I/O消耗也很大;
(2)当空间聚类的密度不均匀、聚类间距差相差很大时,聚类质量较差,因为这种情况下参数MinPts和Eps选取困难。
(3)算法聚类效果依赖与距离公式选取,实际应用中常用欧式距离,对于高维数据,存在“维数灾难”。
基本概念[5]:如下基本概念在[6]中有更为详细说明介绍。
(1)Eps邻域:给定对象半径Eps内的邻域称为该对象的Eps邻域;
(2)核心点(core point):如果对象的Eps邻域至少包含最小数目MinPts的对象,则称该对象为核心对象;
(3)边界点(edge point):边界点不是核心点,但落在某个核心点的邻域内;
(4)噪音点(outlier point):既不是核心点,也不是边界点的任何点;
(5)直接密度可达(directly density-reachable):给定一个对象集合D,如果p在q的Eps邻域内,而q是一个核心对象,则称对象p从对象q出发时是直接密度可达的;
(6)密度可达(density-reachable):如果存在一个对象链 p1, …,pi,.., pn,满足p1 = p 和pn = q,pi是从pi+1关于Eps和MinPts直接密度可达的,则对象p是从对象q关于Eps和MinPts密度可达的;
(7)密度相连(density-connected):如果存在对象O∈D,使对象p和q都是从O关于Eps和MinPts密度可达的,那么对象p到q是关于Eps和MinPts密度相连的。
(8)类(cluster):设非空集合,若满足:,
(a),且从密度可达,那么。
(b)和密度相连。
则称构成一个类簇
有关核心点、边界点、噪音点以及直接密度可达、密度可达和密度相连解释如图1[1]:

图1红色为核心点,黄色为边界点,蓝色为噪音点,minPts = 4,Eps是图中圆的半径大小有关“直接密度可达”和“密度可达”定义实例如图2所示[5]:其中,Eps用一个相应的半径表示,设MinPts=3,请分析Q,M,P,S,O,R这5个样本点之间的关系。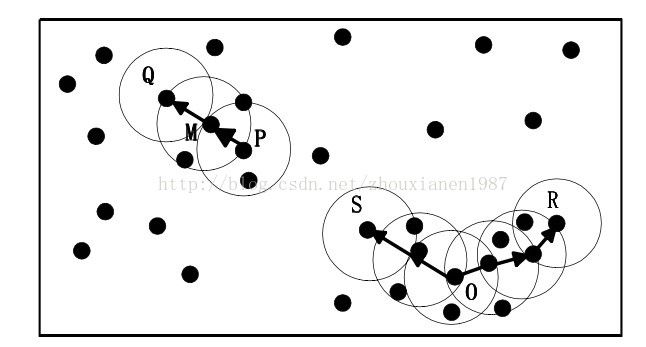
图2 “直接密度可达”和“密度可达”概念示意描述。根据前文基本概念的描述知道:由于有标记的各点M、P、O和R的Eps近邻均包含3个以上的点,因此它们都是核对象;M是从P“直接密度可达”;而Q则是从M“直接密度可达”;基于上述结果,Q是从P“密度可达”;但P从Q无法“密度可达”(非对称)。类似地,S和R从O是“密度可达”的;O、R和S均是“密度相连”(对称)的。
DBSCAN算法原理[5]:
(1)DBSCAN通过检查数据集中每点的Eps邻域来搜索簇,如果点p的Eps邻域包含的点多于MinPts个,则创建一个以p为核心对象的簇;
(2)然后,DBSCAN迭代地聚集从这些核心对象直接密度可达的对象,这个过程可能涉及一些密度可达簇的合并;
(3)当没有新的点添加到任何簇时,该过程结束。
有关算法的伪代码wiki百科中给出了,[5]用中文描述了其流程:
DBSCAN算法伪代码描述:
输入:数据集D,给定点在邻域内成为核心对象的最小邻域点数:MinPts,邻域半径:Eps
输出:簇集合
-
(1) 首先将数据集D中的所有对象标记为未处理状态 -
(2) for(数据集D中每个对象p) do -
(3) if (p已经归入某个簇或标记为噪声) then -
(4) continue; -
(5) else -
(6) 检查对象p的Eps邻域 NEps(p) ; -
(7) if (NEps(p)包含的对象数小于MinPts) then -
(8) 标记对象p为边界点或噪声点; -
(9) else -
(10) 标记对象p为核心点,并建立新簇C, 并将p邻域内所有点加入C -
(11) for (NEps(p)中所有尚未被处理的对象q) do -
(12) 检查其Eps邻域NEps(q),若NEps(q)包含至少MinPts个对象,则将NEps(q)中未归入任何一个簇的对象加入C; -
(13) end for -
(14) end if -
(15) end if -
(16) end for
wiki百科中代码描述:
-
DBSCAN(D, eps, MinPts) { -
C = 0 -
foreach point P in dataset D { -
ifP is visited -
continue next point -
mark P as visited -
NeighborPts = regionQuery(P, eps) -
ifsizeof(NeighborPts) < MinPts -
mark P as NOISE -
else { -
C = next cluster -
expandCluster(P, NeighborPts, C, eps, MinPts) -
} -
} -
} -
expandCluster(P, NeighborPts, C, eps, MinPts) { -
add Pto cluster C -
foreach point P' in NeighborPts { -
ifP' is not visited { -
mark P' as visited -
NeighborPts' = regionQuery(P', eps) -
if sizeof(NeighborPts') >= MinPts -
NeighborPts = NeighborPts joined with NeighborPts' -
} -
ifP' is not yet member of any cluster -
add P' to cluster C -
} -
} -
regionQuery(P, eps) -
returnall points within P's eps-neighborhood (including P)
时间复杂度:
(1)DBSCAN的基本时间复杂度是 O(N*找出Eps领域中的点所需要的时间), N是点的个数。最坏情况下时间复杂度是O(N2)
(2)在低维空间数据中,有一些数据结构如KD树,使得可以有效的检索特定点给定距离内的所有点,时间复杂度可以降低到O(NlogN)
空间复杂度:低维和高维数据中,其空间都是O(N),对于每个点它只需要维持少量数据,即簇标号和每个点的标识(核心点或边界点或噪音点)
参数设置:DBSCAN共包括3个输入数据:数据集D,给定点在邻域内成为核心对象的最小邻域点数:MinPts,邻域半径:Eps,其中Eps和MinPts需要根据具体应用人为设定。
(1) Eps的值可以使用绘制k-距离曲线(k-distance graph)方法得当,在k-距离曲线图明显拐点位置为对应较好的参数。若参数设置过小,大部分数据不能聚类;若参数设置过大,多个簇和大部分对象会归并到同一个簇中。
K-距离:K距离的定义在DBSCAN算法原文中给出了详细解说,给定K邻域参数k,对于数据中的每个点,计算对应的第k个最近邻域距离,并将数据集所有点对应的最近邻域距离按照降序方式排序,称这幅图为排序的k距离图,选择该图中第一个谷值点位置对应的k距离值设定为Eps。一般将k值设为4。原文如下[2]:


(2) MinPts的选取有一个指导性的原则(a rule of thumb),MinPts≥dim+1,其中dim表示待聚类数据的维度。MinPts设置为1是不合理的,因为设置为1,则每个独立点都是一个簇,MinPts≤2时,与层次距离最近邻域结果相同,因此,MinPts必须选择大于等于3的值。若该值选取过小,则稀疏簇中结果由于密度小于MinPts,从而被认为是边界点儿不被用于在类的进一步扩展;若该值过大,则密度较大的两个邻近簇可能被合并为同一簇。因此,该值是否设置适当会对聚类结果造成较大影响。
参考资料:
[1] https://en.wikipedia.org/wiki/DBSCAN
[2] Ester,Martin; Kriegel, Hans-Peter; Sander,Jörg; Xu, Xiaowei (1996). Simoudis, Evangelos; Han, Jiawei; Fayyad, Usama M.,eds. Adensity-based algorithm for discovering clusters in large spatial databaseswith noise. Proceedings of the Second International Conference on KnowledgeDiscovery and Data Mining (KDD-96). AAAI Press.pp. 226–231.CiteSeerX 10.1.1.121.9220. ISBN 1-57735-004-9.
[3] 各种聚类算法的比较
http://blog.163.com/qianshch@126/blog/static/48972522201092254141315/
[4] http://www.cnblogs.com/chaosimple/p/3164775.html
[5] https://wenku.baidu.com/view/ce3e324aa8956bec0975e3d5.html
[6]http://blog.csdn.net/itplus/article/details/10088625
[7] http://www.tuicool.com/articles/euAZneu
[8] http://cn.mathworks.com/matlabcentral/fileexchange/52905-dbscan-clustering-algorithm
[9] http://blog.csdn.net/snnxb/article/details/29880387
[10] 聚类算法-DBSCAN-C++实现,http://blog.csdn.net/k76853/article/details/50440182
[11] DBSCAN聚类算法C++实现,http://blog.csdn.net/u011367448/article/details/18549823
[12] DBSCAN 算法介绍以及C++实现,http://blog.csdn.net/u011557212/article/details/53203323
[13] https://github.com/siddharth-agrawal/DBSCAN
[14] http://download.csdn.net/download/piaominnan/8480767