决策树与集成学习的结合——GBDT和XGBoost
这两个算法在面经中提到较多,故而整理一下。
1.集成学习(将多个弱学习器组合成为强学习器)
串行:Boosting,后一个学习器依赖于前一个,故为串行
- 比较有名的是AdaBoost,每次迭代训练一个学习器,并提高前一轮学习器分类错误样本的权值,降低分类正确的权值
并行:bagging(样本扰动)、随机森林(样本扰动和属性扰动)
Bagging和Boosting的区别:
1)样本选择上:Bagging训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。Boosting每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:Bagging使用均匀取样,每个样例的权重相等。Boosting根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:Bagging所有预测函数的权重相等。Boosting每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:Bagging各个预测函数可以并行生成。Boosting各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
2.决策树
(1)最优属性划分
决策树的叶节点对应于决策成果,其他每个节点对应于一个属性测试。
可通过信息增益(ID3决策树)、增益率(C4.5)、基尼指数(CART)等策略来进行最优属性划分。
信息增益对可取值数目较多的属性有所偏好,所以C4.5采用信息增益率作为划分依据,在信息增益基础上除以IV(a)。但是仍不能完全解决以上问题,而是有所改善,这个时候引入了CART树,它使用gini系数作为节点的分裂依据,反映了随机抽取两个样本,,其类别标记不一致的概率。
(2)剪枝策略
目的:防止过拟合
预剪枝:划分前估计能否带来精度提升(预留一部分数据集进行评估)
后剪枝:在完整的决策树上自底向上地对非叶节点考查,看替换为叶节点是否提升精度
(3)分类与回归决策树
分类决策树:上面提到的ID3/C4.5决策树(西瓜书)
回归决策树:它的作用在于数值预测,例如明天的温度、用户的年龄等等,而且对基于回归树所得到的数值进行加减是有意义的(例如10岁+5岁-3岁=12岁)。

3.GBDT(Gradient Boosting Decision Tree)
属于Boosting家族的一员,将决策树与集成思想进行了有效的结合。GBDT使用到了回归决策树,它将累加所有树的结果作为最终结果。在前一颗树的梯度方向生成下一颗树,每棵树都在学习前面树尚存的不足。用于一个简单的例子来说明GBDT,假如某人的年龄为30岁,第一次用20岁去拟合,发现损失还有10岁,第二次用6岁去拟合10岁,发现损失还有4岁,第三次用3岁去拟合4岁,依次下去直到损失在我们可接受范围内。
一句话总结原理:先用一个初始值去学习一棵树,然后在叶子处得到预测值以及预测后的残差,之后的树则基于之前树的残差不断的拟合得到,累加所有树的结果作为最终结果。
(1)残差


(2)梯度下降


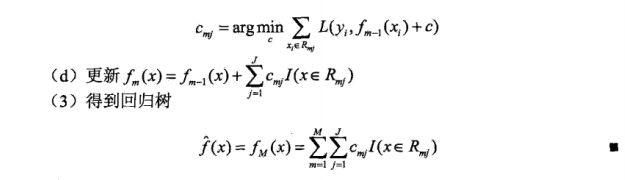
(3)优缺点
优点:预测精度高、能处理非精度数据。
缺点:当数据集大且较为复杂时,迭代次数多,计算量大。
4.XGBoost
GBDT往往要生成很多数量的树才能达到令人满意的准确率,此算法是针对GBDT计算量大的缺点所做的改进
(1)损失函数
和GBDT方法一样,XGBoost的提升模型也是采用残差,不同的是分裂结点选取的时候不一定是最小平方损失,其损失函数如下,较GBDT其根据树模型的复杂度加入了一项正则化项
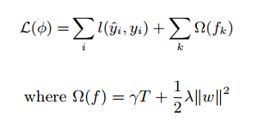

(2)XGBoost与GBDT的区别
- 正则项:XGBoost在目标函数里加入了正则项,用于控制模型的复杂度
- 导数:传统的GBDT使用的是梯度下降法,只用到一阶导数,XGBoost使用了牛顿法,进行了二阶泰勒展开,同时用到了一阶和二阶导数,可以加快优化速度
- 列抽样:XGBoost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算
- 分裂节点:GBDT使用的是gini系数进行分裂,但枚举所有可能的分割点效率很低,XGBoost根据百分位法列举几个可能成为分割点的候选者,然后从候选者中根据上面求分割点的公式计算找出最佳的分割点
- 算法效率:考虑了当数据量比较大,内存不够时怎么有效的使用磁盘,主要是结合多线程、数据压缩、分片的方法
- 缺失值:xgboost可以为缺失值自动学习分裂方向,这能大大提升算法的效率
(3)GBDT与RF的区别
- 随机森林采用的bagging思想,而GBDT采用的boosting思想。一个并行,一个串行。
- 组成随机森林的树可以是分类树,也可以是回归树;而GBDT只能由回归树组成。但RF做回归没有做分类性能好
- 对于最终的输出结果而言,随机森林采用多数投票等;而GBDT则是将所有结果累加起来,或者加权累加起来。
- 随机森林对异常值不敏感;GBDT对异常值非常敏感。
- 随机森林抗干扰能力强,即使有缺失值和缺失特征,数据不平衡也能保持不错的性能。
- 随机森林是通过减少模型方差提高性能;GBDT是通过减少模型偏差提高性能。