Swift 算法实战之路
Swift 算法实战之路:动态规划
(点击上方公众号,可快速关注)
来源:伯乐在线专栏作者 - 故胤道长
链接:http://ios.jobbole.com/88509/
点击 → 了解如何加入专栏作者
Swift 算法实战之路(一)
Swift 算法实战之路(二)
Swift 算法实战之路:二分搜索
Swift 算法实战之路:深度和广度优先搜索

之前的算法之路,分析的问题大多比较具体简单 — 可以直接套用一种方法解决。今天要讲的动态规划,其面对的问题通常是无法一蹴而就,需要把复杂的问题分解成简单具体的小问题,然后通过求解简单问题,去推出复杂问题的最终解。

Domino Effect
形象的理解就是为了推倒一系列纸牌中的第100张纸牌,那么我们就要先推倒第1张,再依靠多米诺骨牌效应,去推倒第100张。
实例讲解
斐波拉契数列是这样一个数列:1, 1, 2, 3, 5, 8, … 除了第一个和第二个数字为1以外,其他数字都为之前两个数字之和。现在要求第100个数字是多少。
这道题目乍一看是一个数学题,那么要求第100个数字,很简单,一个个数字算下去就是了。假设F(n)表示第n个斐波拉契数列的数字,那么我们易得公式F(n) = F(n – 1) + F(n – 2),n >= 2,下面就是体力活。当然这道题转化成代码也不是很难,最粗暴的解法如下:
func Fib() -> Int {
var prev = 0
var curr = 1
for _ in 1 ..< 100 {
var temp = curr
curr = prev + curr
prev = temp
}
return curr
}
用动态规划怎么写呢?首先要明白动态规划有以下几个专有名词:
-
初始状态,即此问题的最简单子问题的解。在斐波拉契数列里,最简单的问题是,一开始给定的第一个数和第二个数是几?自然我们可以得出是1
-
状态转移方程,即第n个问题的解和之前的 n – m 个问题解的关系。在这道题目里,我们已经有了状态转移方程F(n) = F(n – 1) + F(n – 2)
所以这题要求F(100),那我们只要知道F(99)和F(98)就行了;想知道F(99),我们只要知道F(98)和F(97)就行了;想要知道F(98),我们需要知道F(97)和F(96)。。。,以此类推,我们最后只要知道F(2)和F(1)的值,就可以推出F(100)。而F(2)和F(1)正是我们所谓的初始状态,即 F(2) = 1,F(1) =1。所以代码如下:
func Fib(n: Int) -> Int {
// 定义初始状态
guard n > 0 else {
return 0
}
if n == 1 || n == 2 {
return 1
}
// 调用状态转移方程
return Fib(n - 1) + Fib(n - 2)
}
print(Fib(100))
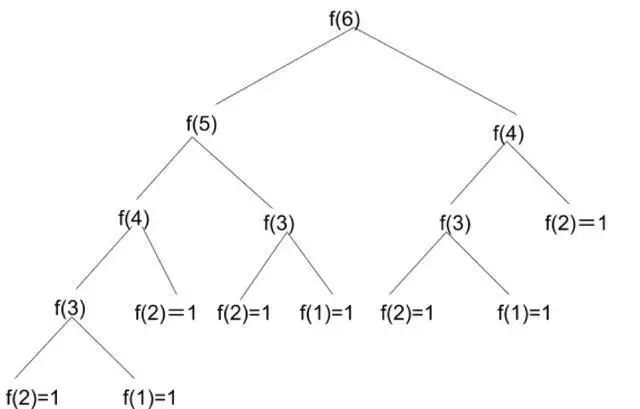
斐波拉契数列的动态规划
这种递归的写法看起来简洁明了,但是上面写法有一个问题:我们要求F(100),那么要计算F(99)和F(98);要计算F(99),我们要计算F(98)和F(97)。。。大家已经发现到这一步,我们已经重复计算两次F(98)了。而之后的计算中还会有大量的重复,这使得这个解法的复杂度非常之高。解决方法就是,用一个数组,将计算过的值存起来,这样可以用空间上的牺牲来换取时间上的效率提高,代码如下:
var nums = [Int](count: 100, repeatedValue: 0)
func Fib(n: Int) -> Int {
// 定义初始状态
guard n > 0 else {
return 0
}
if n == 1 || n == 2 {
return 1
}
// 如果已经计算过,直接调用,无需重复计算
if nums[n - 1] != 0 {
return nums[n - 1]
}
// 将计算后的值存入数组
nums[n - 1] = Fib(n - 1) + Fib(n - 2)
return nums[n - 1]
}
动态转移虽然看上去十分高大上,但是它也存在两个致命缺点:
-
栈溢出:每一次递归,程序都会将当前的计算压入栈中。随着递归深度的加深,栈的高度也越来越高,直到超过计算机分配给当前进程的内存容量,程序就会崩溃。
-
数据溢出:因为动态规划是一种由简至繁的过程,其中积蓄的数据很有可能超过系统当前数据类型的最大值,导致崩溃。
而这两个bug,我们上面这道求解斐波拉契数列第100个数的题目就都遇到了。
-
首先,递归的次数很多,我们要从F(100) = F(99) + F(98) ,一直推理到F(3) = F(2) + F(1),这样很容易造成栈溢出。
-
其次,F(100)应该是一个很大的数。实际上F(40)就已经突破一亿,F(100)一定会造成整型数据溢出。
当然,这两个bug也有相应的解决方法。对付栈溢出,我们可以把递归写成循环的形式(所有的递归都可改写成循环);对付数据溢出,我们可以在程序每次计算中,加入数据溢出的检测,适时终止计算,抛出异常。
iOS实战演练
笔者以前在硅谷参加了一个hackthon大赛,当时是要做一个扫描英文单词出翻译的app。它大概长这样:
扫描单词出翻译
当时这个App其他部分运行非常流畅,就是在打开摄像头扫描单词的时候,会出现误读的情况。比如手写的“price”,机器会识别成“pr1ce”,从而无法对其进行正确的翻译。笔者对这种情况进行了相应的优化处理,方法如下:
-
缩小误差范围:将所有的单词构造成前缀树。然后对于扫描的内容,搜索出相应可能的单词。具体做法可以参考《Swift 算法实战之路:深度和广度优先搜索》一文中搜索单词的方法。
-
计算出最接近的单词:假如上一步,我们已经有了10个可能的单词,那么怎么确定最接近真实情况的单词呢?这里我们要定义两个单词的距离 — 从第一个单词wordA,到第二个单词wordB,有三种操作:
-
删除一个字符
-
添加一个字符
-
替换一个字符
-
综合上述三种操作,用最少步骤将单词wordA变到单词wordB,我们就称这个值为两个单词之间的距离。比如 pr1ce -> price,只需要将 1 替换为 i 即可,所以两个单词之间的距离为1。pr1ce -> prize,要将 1 替换为 i ,再将 c 替换为 z ,所以两个单词之间的距离为2。相比于prize,price更为接近原来的单词。
现在问题转变为实现下面这个方法:
func wordDistance(wordA: String, wordB: String) -> Int { ... }
要解决这个复杂的问题,我们不如从一个简单的例子出发:求“abce”到“abdf”之间的距离。它们两之间的距离,无非是下面三种情况中的一种。
-
删除一个字符:假如已知 wordDistance("abc", "abdf") ,那么“abce”只需要删除一个字符到达“abc”,然后就可以得知“abce”到“abdf”之间的距离。
-
添加一个字符:假如已知 wordDistance("abce", "abd"),那么我们只要让“abd”添加一个字符到达“abdf”即可求出最终解。
-
替换一个字符:假如已知 wordDistance("abc", "abd"),那么就可以依此推出 wordDistance("abce", "abde") = wordDistance("abc", "abd")。故而只要将末尾的“e”替换成”f”,就可以得出wordDistance("abce", "abdf")
这样我们就可以发现,求解任意两个单词之间的距离,只要知道之前单词组合的距离即可。我们用dp[i][j]表示第一个字符串wordA[0…i] 和第2个字符串wordB[0…j] 的最短编辑距离,那么这个动态规划的两个重要参数分别是:
-
初始状态:dp[0][j] = j,dp[i][0] = i
-
状态转移方程:dp[i][j] = min(dp[i – 1][j – 1], dp[i – 1][j], dp[i][j – 1]) + 1
再举例解释一下,”abc”到”xyz”,dp[2][1]就是”ab”到”x”的距离,不难看出是2;dp[1][2]就是”a”到”xy”的距离,是2;dp[1][1]也就是”a”到”x”的距离,很显然就是1。所以dp[2][2]即”ab”到”xy”的距离是min(dp[2][1], dp[1][2], dp[1][1]) + 1就是2.
有了初始状态和状态转移方程,那么动态规划的代码就出来了:
func wordDistance(wordA: String, _ wordB: String) -> Int {
let aChars = [Character](wordA.characters)
let bChars = [Character](wordB.characters)
let aLen = aChars.count
let bLen = bChars.count
var dp = Array(count: aLen + 1, repeatedValue:(Array(count: bLen + 1, repeatedValue: 0)))
for i in 0 ... aLen {
for j in 0 ... bLen {
// 初始情况
if i == 0 {
dp[i][j] = j
} else if j == 0 {
dp[i][j] = i
// 特殊情况
} else if aChars[i - 1] == bChars[j - 1] {
dp[i][j] = dp[i - 1][j - 1]
} else {
// 状态转移方程
dp[i][j] = min(dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]) + 1
}
}
}
return dp[aLen][bLen]
}
用动态规划计算出单词之间的距离之后,在做一些相应的优化,就可以准确的识别出扫描的单词。
全系列总结
动态规划算是算法进阶中比较重要的一环,它的思想就是把复杂问题化为简单具体问题,然后分析出初始状态和状态转移方程,从而推出最终解。也许它在实际编程或是iOS开发中出现频率不高,但是这种删繁就简的思路,却可以应用在生活或者工作中的方方面面。
Swift算法实战系列前前后后一共9篇:
-
第1篇是分析Swift的基本语法。谈的是如何快速有效书写Swift的技巧;
-
第2 – 5篇主要是讲各种数据结构。分别讲了数组、字符串、字典、链表、栈、队列、二叉树;
-
第6 – 9篇分析的是各种基本算法。搜索、排序、深度和广度优先搜索、递归和动态规划都有涉及。
整个系列的目的就是用Swift说清楚最基本的算法和数据结构知识,所以语言尽可能通俗易懂。动态规划再往上讲,就比较阳春白雪了,故而至此收笔。感谢大家的阅读和指教。