学习Java的同学注意了!!!
学习过程中遇到什么问题或者想获取学习资源的话,欢迎加入Java学习交流群,群号码:589809992 我们一起学Java!
阅读目录
- 参考资料
- 前言
- 从对立到统一,字节流和字符流
- 从抽象到具体,数据的来源和目的
- 从简单到丰富,使用 Decorator 模式扩展功能
- Java 7 中引入的 NIO.2
- NIO.2 中的异步 I/O
- 总结
参考资料
该文中的内容来源于 Oracle 的官方文档。Oracle 在 Java 方面的文档是非常完善的。对 Java 8 感兴趣的朋友,可以从这个总入口Java SE 8 Documentation 开始寻找感兴趣的内容。本博客不定期从 Oracle 官网搬砖。这一篇主要讲 Java 中的 I/O,官方文档在这里 Java I/O, NIO, and NIO.2。
前言
不知道大家看到这个标题会不会笑我,一个使用 Java 多年的老程序员居然一直没有记住 Java 中的 I/O。不过说实话,Java 中的 I/O 确实含有太多的类、接口和抽象类,而每个类又有好几种不同的构造函数,而且在 Java 的 I/O 中又广泛使用了 Decorator 设计模式(装饰者模式)。总之,即使是在 OO 领域浸淫多年的老手,看到下面这样的调用一样会蛋疼:
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("somefile.txt")));当然,这仅仅只是我为了体现 Java I/O 的错综复杂的构造函数而虚构出来的一个例子,现实中创建一个 BufferedReader 很少会嵌套这么深,因为可以直接使用 FileReader 而避免多创建一个 FileInputStream。但是从一个 InputStream 转化成一个 BufferedReader 总是有那么几步路要走的,比如下面这个例子:
URL cnblogs = new URL("http://www.cnblogs.com/");
BufferedReader reader = new BufferedReader(new InputStreamReader(cnblogs.openStream()));Java I/O 涉及到的类也确实特别多,不仅有分别用于操作字符流和字节流的 InputStream 和 Reader、OutputStream 和 Writer,还有什么 BufferedInputStream、BufferedReader、PrintWriter、PrintStream等,还有用于沟通字节流和字符流的桥梁 InputStreamReader 和 OutputStreamWriter,每一个类都有其不同的应用场景,如此细致的划分,光是名字就足够让人晕头转向了。
我一直记不住 Java I/O 中各种细节的另一个原因可能是我深受 ANSI C 的荼毒吧。在 C 语言的标准库中,将文件的打开方式分为两种,一种是将文件当成二进制格式打开,一种是当成文本格式打开。这和 Java 中的字节流和字符流的划分有相似之处,但却掩盖了所有的数据其实都是字节流这样的本质。ANSI C 用多了,总以为二进制格式和文本格式是同一个层面的两种对立面,只能对立而不能统一,却不知在 Java 中,字符流是对字节流的更高层次的封装,最底层的 I/O 都是建立在字节流的基础上的。如果抛开 ANSI C 语言的标准 I/O 库,直接考察操作系统层面的 POSIX I/O,会发现操作的一切都是原始的字节数据,根本没有什么字节字符的区别。
除此之外,Java 走得更远,它考虑到了各种更加广泛的字节流,而不仅仅限于文件。比如网络中传输的数据、内存中传输的对象等等,都可以用流来抽象。但是不同的流具有不同的特性,有的流可以随机访问,而有的却只能顺序访问,有的可以解释为字符,有的不能。在能解释为字符的流中,有的一次只能访问一个字符,有的却可以一次访问一行,而且把字节流解释成字符流,还要考虑到字符编码的问题。
以上种种,均是造成 Java I/O 中类和接口多、对象构造方式复杂的原因。
从对立到统一,字节流和字符流
先来说对立。在 Java 中如果要把流中的数据按字节来访问,就应该使用 InputStream 和 OutputStream,如果要把流中的数据按字符来访问,就应该使用 Reader 和 Writer。上面提到的这四个类都是抽象类,是所有其它具体类的基础。不能直接构造 InputStream、OutputStream、Reader 和 Writer 类的实例,但是根据 OO 原则,可以这样用:
InputStream in = new FileInputStream("somefile");
int c = in.read();或者这样:
Reader reader = new FileReader("somefile");
int c = reader.read();这里的 FileInputStream 和 FileReader 就是具体的类,这样的类还有很多,都位于 java.io 包中。文件读写是我们最常用的操作,所以最常用的就是 FileInputStream、FileOutputStream、FileReader、FileWriter这四个。这几个类的构造函数有多个,但是最简单的,肯定是接受一个代表文件路径的字符串做参数的那一个。根据 OO 原则,我们一般使用更加抽象的 InputStream、OutputStream、Reader、Writer 来引用具体的对象。所以,在考察 API 的时候,只需要考察这四个抽象类就可以了,其它的具体类,基本上只需要考察它们的构造方式。
而这几个类的 API 也确实很好记,用来输入的两个类 InputStream 和 Reader 主要定义了read()方法,而用来输出的两个类 OutputStream 和 Writer 主要定义了write()方法。所不同者,前者操作的是字节,后者操作的是字符。read()和write()最简单的用法是这样的:
package com.xkland.sample;
import java.io.InputStream;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.FileNotFoundException;
public class JavaIODemo {
public static void main(String[] args) {
if(args.length < 1){
System.out.println("Usage: JavaIODemo filename");
return;
}
String somefile = args[0];
InputStream in = null;
try{
in = new FileInputStream(somefile);
int c;
while((c = in.read()) != -1) { //这里用到read()
System.out.write(c); //这里用到write()
}
}catch(FileNotFoundException e){
System.out.println("File not found.");
}catch(IOException e){
System.out.println("I/O failed.");
}finally{
if(in != null){
try {
in.close();
}catch(IOException e){
//关闭流时产生的异常,直接抛弃
}
}
}
}
} 上面的例子展示了read()和write()的用法,在 InputStream 和 OutputStream 中,这两个方法操作的都是字节,但是,这里用来保存这个字节的变量却是int类型的。这正是 API 设计的匠心所在,因为int的宽度明显比byte要大,所以将一个byte读入到一个int之后,有效的数据只占据int型变量的最低8位,如果read()方法返回的是有效数据,那么这个int型的变量永远都不可能是负数。在这种情况下,read()方法可以用返回负数的方式来表示碰到特殊情况,比如返回-1表示到达了流的末尾,也就是用-1代表EOF。write()方法接受的参数也是int型的,但是它只把这个int型变量的最低8位写入流,其余的数据被忽略。
上面的例子还展示了 Java I/O 的一些特征:
- InputStream、OutputStream、Reader、Writer 等资源用完之后要关闭;
- 所有的 I/O 操作都可能产生异常,包括调用
close()方法。
这两个特征搅到一起就比较复杂了,本来因为异常的产生就容易让流的close()语句执行不到,所以只有把close()写到finally块中,但是在finally块中调用close()又要写一层try...catch...代码块。如果同时有多个流需要关闭,而前面的close()抛出异常,则后面的close()将不会执行,极易发生资源泄露。再加上如果前面的catch()块中的异常被重新抛出,而finally块中又没有处理好异常的话,前面的异常会被抑制,所以大部分人都 hold 不住这样的代码,包括 Oracle 的官方教程中的写法都是错误的。下面来看一下 Oracle 官方教程中的例子:
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class CopyBytes {
public static void main(String[] args) throws IOException {
FileInputStream in = null;
FileOutputStream out = null;
try {
in = new FileInputStream("xanadu.txt");
out = new FileOutputStream("outagain.txt");
int c;
while ((c = in.read()) != -1) {
out.write(c);
}
} finally {
if (in != null) {
in.close();
}
if (out != null) {
out.close();
}
}
}
} 官方教程写得比我更偷懒,它直接让main()方法抛出IOException而避免了异常处理,也避免了在finally块中的close()语句外再写一层try...catch...。但是,这个示例的漏洞有两个,其一是如果in.close()抛出了异常,则out.close()就不会执行;其二是如果try块中抛出了异常,finally块中又抛出了异常,则前面抛出的异常会被丢弃。为了解决这个问题,Java 7中新加入了try-with-resource语法。后面都用这种方式写代码。
很显然,一次处理一个字节效率是及其低下的,所以read()和write()还有别的重载版本:
int read(byte[] b) int read(byte[] b, int off, int len) void write(byte[] b) void write(byte[] b, int off, int len) 它们都可以一次操作一块数据,用字节数组做为存储数据的容器。read()返回的是实际读取的字节数。而对于 Reader 和 Writer,它们的read()和write()方法的定义是这样的:
int read() int read(char[] cbuf) int read(char[] cbuf, int off, int len) void write(int c) void write(char[] cbuf) void write(char[] cbuf, int off, int len) void write(String str) void write(String str, int off, int len) 可以看出,使用 Reader 和 Writer 一次操作一个字符的时候,依然使用的是int型的变量。如果一次操作一块数据,则使用字符数组。输出的时候,还可以直接使用字符串。
到这里,已经可以很轻易记住八个类了:InputStream、OutputStream、Reader、Writer、FileInputStream、FileOutputStream、FileReader、FileWriter。前四个是抽象类,后四个是操作文件的具体类。而且这八个类分成两组,一组操作字节流,一组操作字符流。很简单的对立分组。
然而,前面我提到过,其实字节流和字符流并不是完全对立的存在,其实字符流是在字节流上更高层次的封装。在底层,一切数据都是字节,但是经过适当的封装,可以把这些字节解释成字符。而且,并不是所有的 Reader 都是可以像 FileReader 那样直接创建的,有时,只能拿到一个可以读取字节数据的 InputStream,却需要在它之上封装出一个 Reader,以方便按字符的方式读取数据。最典型的例子就是可以这样访问一个网页:
URL cnblogs = new URL("http://www.cnblogs.com/");
InputStream in = cnblogs.openStream();这时,拿到的是字节流 InputStream,如果想获得按字符读取数据的 Reader,可以这样创建:
Reader reader = new InputStreamReader(in);所以, InputStreamReader 是沟通字节流和字符流的桥梁。同样的桥梁还用用于输出的 OutputStreamWriter。至此,不仅又轻松地记住了两个类,也再次证明了字节流和字符流既对立又统一的辩证关系。
从抽象到具体,数据的来源和目的
InputStream、OutputStream、Reader 和 Writer 是抽象的,根据不同的数据来源和目的又有不同的具体类。前面的例子中提到了基于 File 的流,也初步展示了一个基于网络的流。结合平时使用计算机的经验,我们也可以想到其它一些不同的数据来源和目的,比如从内存中读取字节或把字节写入内存,从字符串中读取字符或者把字符写入字符串等等,还有从管道中读取数据和向管道中写入数据等等。根据不同的数据来源和目的,可以有这样一些具体类:FileInputStream、ByteArrayInputStream、PipedInputStream、FileOutputStream、ByteArrayOutputStream、PipedOutputStream、FileReader、StringReader、CharArrayReader、PipedReader、FileWriter、StringWriter、CharArrayWriter、PipedWriter等。从这些类的命名可以看出,凡是以Stream结尾的,都是操作字节的流,凡是以 Reader 和 Writer 结尾的,都是操作字符的流。只有 InputStreamReader 和 OutputStreamWriter 是例外,它是沟通字节和字符的桥梁。对于这些具体类,使用起来是没有什么困难的,只需要考察它们的构造函数就可以了。下面两幅 UML 类图可以展示这些类的关系。
InputStreams 和 Readers:
OutputStreams 和 Writers: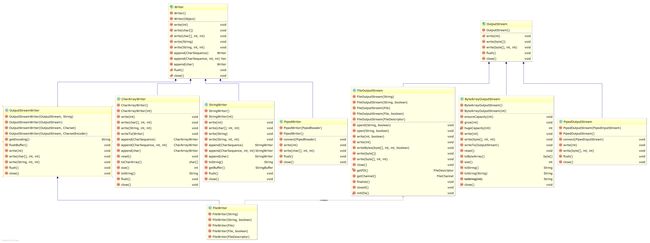
从简单到丰富,使用 Decorator 模式扩展功能
从前文可以看出,所有的流都支持read()和write(),但是这样的功能毕竟还是太简单,有时还需要更高层次的功能需求,所以需要使用 Decorator 模式来对流进行扩展。比如,一次操作一个字节或一个字符效率太低,想把数据先缓存在内存中再进行操作,就可以扩展出 BufferedInputStream、BufferedReader、BufferedOutputStream、BufferedWriter 类。可以猜测到,BufferedOutputStream 和 BufferedWriter 类中一定有一个flush()方法,用来把缓存的数据写入到流中。而且,BufferedReader 还有 readLine() 方法,可以一次读取一行字符,甚至可以再扩展出一个 LineNumberReader,还可以提供行号的支持。再比如,有时从流中读出一个字节或一个字符后,又不想要了,想把它还回去,就可以再扩展出 PushbackInputStream 和 PushbackReader,提供unread()方法将刚读取的字节或字符还回去。可以想象,这种还回去的功能应该是需要缓存功能支持的,所以它们应该是在 BufferedInputStream 和 BufferedReader 外面又加了一层的装饰。这就是 Decorator 模式。
Java I/O 中自带的这种扩展类还有很多,不容易记。后面的介绍中,会针对重要的类举几个例子。在此之前,还是通过 UML 类图来了解一下扩展类。
从 InputStream 扩展的类:
从 Reader 扩展的类:
从 OutputStream 扩展的类: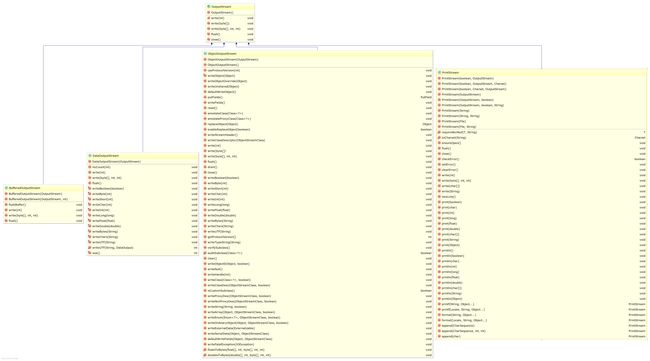
从 Writer 扩展的类: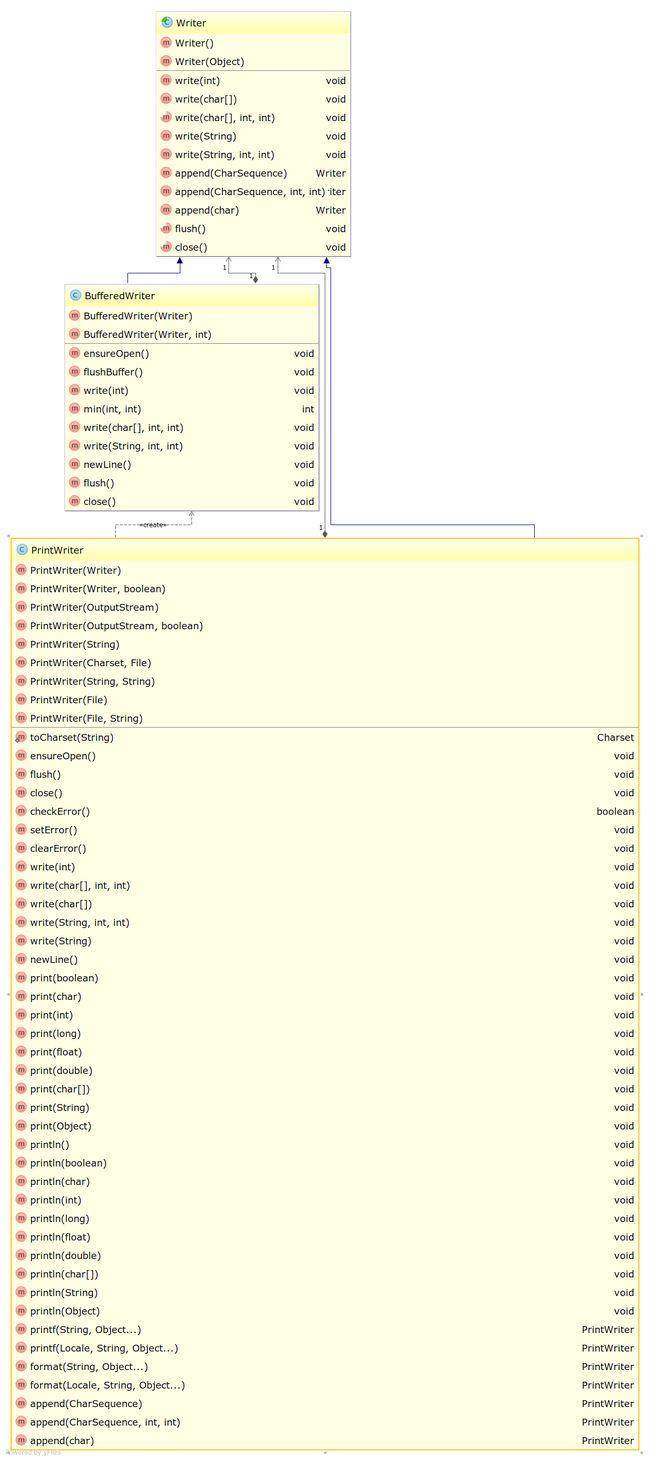
从上图中可以看到,每一个分组中扩展的类的数量是不一样的,再也不是一种对称的关系。仔细一想也很好理解,例如 Pushback 这样的功能就只能用在输入流 InputStream 和 Reader 上,而向输出流中写入数据就像泼出去的水,没办法再 Pushback 了。再例如,向流中写入对象和读取对象,操作的肯定是字节流而不是字符流,所以只有 ObjectInputStream 和 ObjectOutputStream,而没有相应的 Reader 和 Writer 版本。再例如打印,操作的肯定是输出流,所以只有 PrintStream 和 PrintWriter,没有相应的输入流版本,这没有什么好奇怪的。
在这些类中,可以通过 PrintStream 和 PrintWriter 向流中写入格式化的文本,也可以通过 DataInputStream 和 DataOutputStream 从流中读取或向流中写入原始的数据,还可以通过 ObjectInputStream 和 ObjectOutputStream 从流中读取或写入一个完整的对象。如果要从流中读取格式化的文本,就必须使用 java.util.Scanner 类了。
下面先看一个简单的示例,使用 DataOutputStream 的writeInt()、writeDouble()以及writeUTF()方法将int、double、String类型的数据写入流中,然后再使用 DataInputStream 的readInt()、readDouble()、readUTF()方法从流中读取int、double、String类型的数据。为了简单起见,就使用基于文件的流作为存储数据的方式。代码如下:
package com.xkland.sample;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import java.io.EOFException;
public class DataStreamsDemo {
public static void writeToFile(String filename){
double[] prices = { 19.99, 9.99, 15.99, 3.99, 4.99 };
int[] units = { 12, 8, 13, 29, 50 };
String[] descs = {
"Java T-shirt",
"Java Mug",
"Duke Juggling Dolls",
"Java Pin",
"Java Key Chain"
};
try(DataOutputStream out = new DataOutputStream(
new BufferedOutputStream(
new FileOutputStream(filename)))){
for (int i = 0; i < prices.length; i ++) {
out.writeDouble(prices[i]);
out.writeInt(units[i]);
out.writeUTF(descs[i]);
}
}catch(IOException e){
System.out.println(e.getMessage());
}
}
public static void readFromFile(String filename){
double price;
int unit;
String desc;
double total = 0.0;
try(DataInputStream in = new DataInputStream(
new BufferedInputStream(
new FileInputStream(filename)))){
while (true) {
price = in.readDouble();
unit = in.readInt();
desc = in.readUTF();
System.out.format("You ordered %d" + " units of %s at $%.2f%n", unit, desc, price);
total += unit * price;
}
}catch(EOFException e){
//达到文件末尾
System.out.format("所有数据已读入,总价格为:$%.2f%n", total);
}catch(IOException e){
System.out.println(e.getMessage());
}
}
} 然后在main()方法中这样调用:
package com.xkland.sample;
public class JavaIODemo {
public static void main(String[] args) {
if(args.length < 1){
System.out.println("Usage: JavaIODemo filename");
return;
}
//向文件中写入数据
DataStreamsDemo.writeToFile(args[0]);
//从文件中读取数据并显示
DataStreamsDemo.readFromFile(args[0]);
}
}然后这样运行该程序:
java com.xkland.sample.JavaIODemo /home/youxia/testfile最后输出是这样:
You ordered 12 units of Java T-shirt at $19.99
You ordered 8 units of Java Mug at $9.99
You ordered 13 units of Duke Juggling Dolls at $15.99
You ordered 29 units of Java Pin at $3.99
You ordered 50 units of Java Key Chain at $4.99
所有数据已读入,总价格为:$892.88 如果使用cat命令查看/home/youxia/testfile文件的内容,只会看到一堆乱码,说明该文件是以二进制格式存储的。如下:
youxia@ubuntu:~$cat testfile
@3�p��
=
Duke Juggling Dolls@�� �Q�Java Pin@ �\(�2Java Key Chain 上面的代码展示了 DataInputStream 和 DataOutputStream 的用法,通过前面的探讨,对它们这样层层包装的构造方式已经见怪不怪了。并且在示例代码中使用了 Java 7 中新引入的try-with-resource语法,这样大大减少了代码的复杂度,所有打开的流都可以自动关闭,而且异常处理也更简洁。从代码中还可以看到,需要捕获 DataInputStream 的 EOFException 异常才能判断读取到了文件结尾。另外,使用这种方式写入和读取数据要非常小心,写入数据的顺序和读取数据的顺序一定要保持一致,如果先写一个int,再写一个double,则一定要先读一个int,再读一个double,否则只会读取错误的数据。不信可以通过修改上述示例代码中读取数据的顺序进行测试。
使用 DataInputStream 和 DataOutputStream 只能写入和读取原始的数据类型的数据,如byte、char、short、float等,如果要读取和写入复杂的对象就不行了,比如java.math.BigDecimal。这个时候就需要使用 ObjectInputStream 和 ObjectOutputStream 了。所有需要写入流和从流读取的 Object 必须实现Serializable接口,然后调用 ObjectInputStream 和 ObjectOutputStream 的writeObject()方法和readObject()方法就可以了。而且很奇妙的是,如果一个 Object 中包含了其它的 Object 对象,则这些对象都会被写入到流中,而且能保持它们之间的引用关系。从流中读取对象的时候,这些对象也会同时被读入内存,并保持它们之间的引用关系。如果把同一批对象写入不同的流,再从这些流中读出,就会获得这些对象多个副本。这里就不举例了。
与以二进制格式写入和读取数据相对的,就是以文本的方式写入和读取数据。PrintStream 和 PrintWriter 中的 Print 就是代表着输出能供人读取的数据。比如浮点数3.14可以输出为字符串"3.14"。利用 PrintStream 和 PrintWriter 中提供的大量print()方法和println()方法就可以做到这点,利用format()方法还可以进行更加复杂的格式化。把上面的例子做少量修改,如下:
package com.xkland.sample;
import java.io.*;
import java.util.Scanner;
public class PrintStreamDemo {
public static void writeToFile(String filename){
double[] prices = { 19.99, 9.99, 15.99, 3.99, 4.99 };
int[] units = { 12, 8, 13, 29, 50 };
String[] descs = {
"Java T-shirt",
"Java Mug",
"Duke Juggling Dolls",
"Java Pin",
"Java Key Chain"
};
try(PrintStream out = new PrintStream(
new BufferedOutputStream(
new FileOutputStream(filename)))){
for (int i = 0; i < prices.length; i ++) {
out.println(prices[i]);
out.println(units[i]);
out.println(descs[i]);
}
}catch(IOException e){
System.out.println(e.getMessage());
}
}
public static void readFromFile(String filename){
double price;
int unit;
String desc;
double total = 0.0;
try(Scanner s = new Scanner(new BufferedReader(new FileReader(filename)))){
s.useDelimiter("\n");
while (s.hasNext()) {
price = s.nextDouble();
unit = s.nextInt();
desc = s.next();
System.out.format("You ordered %d" + " units of %s at $%.2f%n", unit, desc, price);
total += unit * price;
}
System.out.format("所有数据已读入,总价格为:$%.2f%n", total);
}catch(IOException e){
System.out.println(e.getMessage());
}
}
} 这时输出的数据和输入的数据都是经过良好格式化的,非常便于阅读和打印,但是在处理数据的时候需要进行适当的转换和解析,所以会一定程度上影响效率。在使用java.util.Scanner时,可以使用useDelimiter()方法设置合适的分隔符,在 Linux 系统中,空格、冒号、逗号都是常用的分隔符,具体情况具体分析。在上面的例子中,我直接将每个数据作为一行保存,这样更加简单。如果使用cat命令查看/home/youxia/testfile文件的内容,可以看到格式良好的数据,如下:
youxia@ubuntu:~$ cat testfile
19.99
12
Java T-shirt
9.99
8
Java Mug
15.99
13
Duke Juggling Dolls
3.99
29
Java Pin
4.99
50
Java Key Chain如果不想使用流,只想像 C 语言那样简单地操作文件,可以使用 RandomAccessFile 类。
对于 PrintStream 和 PrintWriter,我们用得最多的就是基于命令行的标准输入输出,也就是从键盘读入数据和向屏幕写入数据。Java 中有几个内建的对象,它们分别是 System.in、System.out、System.err,因为平时用得多,我就不一一细讲了。需要说明的是,这几个对象都是字节流而不是字符流,这也可以理解,虽然我们的键盘不能输入纯二进制数据,但是通过管道和文件重定向却可以,在控制台中输出乱码也是常见的现象,所以这几个流必须是字节流而不是字符流。如果要想按字符的方式读取标准输入,可以使用 InputStreamReader 这样转换一下:
InputStreamReader cin = new InputStreamReader(System.in); 除此之外,还可以使用 System.console 对象,它是 Console 类的一个实例。它提供了几个实用的方法来操作命令行,如readLine()、readPassword()等,它的操作是基于字符流的。不过在使用 System.console 之前,先要判断它是否存在,如果操作系统不支持或程序运行在一个没有命令行的环境中,则其值为null。
Java 7 中引入的 NIO.2
早在 2002 年发布的 Java 1.4 中就引入了所谓的 New I/O,也就是 NIO。但是依然被打脸, NIO 还是不那么好用,还白白浪费了 New 这个词,搞得 Java 7 中对 I/O 的改进不得不称为 NIO.2。在 Java 7 之前的 I/O 怎么不好用呢?主要表现在以下几点:
- 在不同的操作系统中,对文件名的处理不一致;
- 不方便对目录树进行遍历;
- 不能处理符号链接;
- 没有一致的文件属性模型,不能方便地访问文件的属性。
所以,虽然存在java.io.File类,我前文中却没有介绍它。在 Java 7 中,引入了 Path、Paths、Files等类来对文件进行操作。Path 代表文件的路径,不同操作系统有不同的文件路径格式,而且还有绝对路径和相对路径之分。可以这样创建路径:
Path absolute = Paths.get("/", "home", "youxia");
Path relative = Paths.get("myprog", "conf", "user.properties"); 静态方法Paths.get()可以接受一个或多个字符串,然后它将这些字符串用文件系统默认的路径分隔符连接起来。然后它对结果进行解析,如果结果在指定的文件系统上不是一个有效的路径,那么它会抛出一个 InvalidPathException 异常。当然,也可以给该方法传递一个含有分隔符的字符串:
Path home = Paths.get("/home/youxia");Path 类提供很多有用的方法对路径进行操作。例如:
Path home = Paths.get("/home/youxia");
Path conf = Paths.get("myprog", "conf", "user.properties");
home.resolve(conf); // 返回"/home/youxia/myprog/conf/user.properties"
Path another_home = Paths.get("/home/another");
home.relativize(another_home); //返回相对路径"../another"
Paths.get("/home/youxia/../another/./myprog").normalize(); //去掉路径中冗余,返回"/home/another/myprog"
conf.toAbsolutePath(); //根据程序的运行目录返回绝对路径,如过在用户的根目录中启动程序,则返回"/home/youxia/myprog/conf/user.properties"
conf.getParent(); //获得路径的不含文件名的部分,返回"myprog/conf/"
conf.getFileName(); //获得文件名,返回"user.properties"
conf.getRoot(); //获得根目录使用 Files 类可以快速实现一些常用的文件操作。例如,可以很容易地读取一个文件的全部内容:
byte[] bytes = Files.readAllBytes(path);如果想将文件内容解释为字符串,可以在 readAllBytes 后调用:
String content = new String(bytes, StandardCharsets.UTF_8);也可以按行来读取文件:
List lines = Files.readAllLines(path); 反过来,将一个字符串写入文件:
Files.write(path, content.getBytes(StandardCharsets.UTF_8));按行写入:
Files.write(path, lines);将内容追加到指定文件中:
Files.write(path, lines, StandardOpenOption.APPEND);当然,仍然可以使用前文介绍的 InputStream、OutputStream、Reader、Writer 类。这样创建它们:
InputStream in = Files.newInputStream(path);
OutputStream out = Files.newOutputStream(path);
Reader reader = Files.newBufferedReader(path);
Writer in = Files.newBufferedWriter(path); 同时,使用Files.copy()方法,可以简化某些工作:
Files.copy(in, path); //将一个 InputStream 中的内容保存到一个文件中
Files.copy(path, out); //将一个文件的内容复制到一个 OutputStream 中一些创建、删除、复制、移动文件和目录的操作:
Files.createDirectory(path); //创建一个新目录
Files.createFile(path); //创建一个空文件
Files.exists(path); //检测一个文件或目录是否存在
Files.createTempFile(prefix, suffix); //创建一个临时文件
Files.copy(fromPath, toPath); //复制一个文件
Files.move(fromPath, toPath); //移动一个文件
Files.delete(path); //删除一个文件 如果目标文件或目录存在的话,copy()和move()方法会失败。如果希望覆盖一个已存在的文件,可以使用StandardCopyOption.REPLACE_EXISTING选项。也可以指定使用原子方式来执行移动操作,这样要么移动操作成功完成,要么源文件依然存在,可以使用StandardCopyOption.ATOMIC_MOVE选项。
可以通过Files.isSymbolicLink()方法判断一个文件是否是符号链接,还可以通过File.readSymbolicLink()方法读取该符号链接目标的真实路径。关于文件属性,Java 7 中提供了 BasicFileAttributes 对真正通用的文件属性进行了抽象,对于更具体的文件属性,还提供了 PosixFileAttributes 等类。可以使用Files.readAttributes()方法读取文件的属性。关于符号链接和属性,来看一个示例:
package com.xkland.sample;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.LinkOption;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.attribute.PosixFileAttributes;
public class JavaIODemo {
public static void main(String[] args) {
if(args.length < 1){
System.out.println("Usage: JavaIODemo filename");
return;
}
Path path = Paths.get(args[0]);
Path real = null;
try{
if(Files.isSymbolicLink(path)){
real = Files.readSymbolicLink(path);
}
PosixFileAttributes attr = Files.readAttributes(path, PosixFileAttributes.class, LinkOption.NOFOLLOW_LINKS);
System.out.format("%s, size: %d, isSymbolicLink: %b .", path, attr.size(), attr.isSymbolicLink());
System.out.println();
PosixFileAttributes attrOfReal = Files.readAttributes(real, PosixFileAttributes.class);
System.out.format("%s, size: %d, isSymbolicLink: %b .", real, attrOfReal.size(), attrOfReal.isSymbolicLink());
System.out.println();
} catch (IOException e) {
e.printStackTrace();
}
}
} 如果这样运行程序,可以查看/etc/alternatives/js文件是否是符号链接,并查看具体链接到哪个文件:
youxia@ubuntu:~$java com.xkland.sample.JavaIODemo /etc/alternatives/java
/etc/alternatives/java, size: 35, isSymbolicLink: true .
/usr/java/jdk1.8.0_102/jre/bin/java, size: 7734, isSymbolicLink: false . NIO.2 API 会默认跟随符号链接,如果不要上述示例代码中的LinkOption.NOFOLLOW_LINKS选项,则Files.readAttributes()返回的结果就是实际文件的属性,而不是符号链接文件的属性。
NIO.2 中的异步 I/O
由于 I/O 操作经常会阻塞,所以编写异步 I/O 操作的代码从来都是提高程序运行效率的有效手段。特别是 Node.js 的出现,使异步 I/O 的影响达到空前的巨大,基于 Callback 的异步 I/O 早已深入人心。 Java 7 中有三个新的异步通道:
- AsynchronousFileChannel —— 用于文件 I/O;
- AsynchronousSocketChannel —— 用于套接字 I/O,支持超时;
- AsynchronousServerSocketChannel —— 用于套接字接受异步链接。
这里只考察一下基于文件的异步 I/O。使用异步 I/O 有两种形式,一种是基于 Future,一种是基于 Callback。使用 Future 的示例代码如下:
try{
Path file = Paths.get("/home/youxia/testfile");
AsynchronousFileChannel channel = AsynchronousFileChannel.open(file); //异步打开文件
ByteBuffer buffer = ByteBuffer.allocate(100_000);
Future result = channel.read(buffer, 0); //读取 100 000 字节
while(!result.isDone()){
//干点儿别的事情
}
Integer bytesRead = result.get(); //获取结果
System.out.println("已读取的字节数:" + bytesRead);
}catch(IOException | ExecutionException | InterruptedException e){
System.out.println(e.getMessage());
} 如果使用基于 Callback 的异步 I/O,其示例代码是这样的:
try{
Path file = Paths.get("/home/youxia/testfile");
AsynchronousFileChannel channel = AsynchronousFileChannel.open(file);
ByteBuffer buffer = ByteBuffer.allocate(100_000); //异步方式打开文件,分配缓冲区准备读取,和前面是一样的
channel.read(buffer, 0, buffer, new CompletionHandler(){
public void completed(Integer result, ByteBuffer attachment){
System.out.println("已读取的字节数:" + bytesRead);
}
public void failed(Throwable exception, ByteBuffer attachment){
System.out.println(exception.getMessage());
}
}); //调用 channel.read() 的另一个版本,接受一个 CompletionHandler 类的对象做参数
}catch(IOException e){
System.out.println(e.getMessage());
} 在这里,创建了一个回调对象,该对象有completed()方法和failed()方法,根据 I/O 操作是否成功相应的方法会被回调,这和 Node.js 中的异步 I/O 是何其的相似啊。
总结
写完这一篇,估计我是再也不会忘记 Java I/O 的用法了。认真读完我这一篇的朋友应该也一样,如果读一遍又忘记了的话,就多读几遍。当然,我这一篇文章仍不可能包含 Java I/O 的方方面面。关于具体的 API,大家直接查看 Oracle 的官方文档就可以了。读到这里的朋友,请不要忘记给个推荐,谢谢。
学习Java的同学注意了!!!
学习过程中遇到什么问题或者想获取学习资源的话,欢迎加入Java学习交流群,群号码:589809992 我们一起学Java!