【温故而知新】线性回归(Linear Regression)
本文主要以下几个角度来讲解线性回归:
- 最小二乘法LSE(矩阵表达,几何意义)
- 概率角度:最小二乘法LSE——noise为Gaussian MLE
- 正则化:
- L1——Lasso
- L2——Ridge
- 正则化的几何解释
最小二乘法
定义为:通过给定样本数据集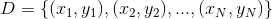 ,
, ![]() ,
, ![]() ,试图学习到这样的一个模型,使得对于任意的输入特征向量
,试图学习到这样的一个模型,使得对于任意的输入特征向量![]() ,模型的预测输出
,模型的预测输出 能够表示为输入特征向量
能够表示为输入特征向量 的线性函数,即满足:
的线性函数,即满足:
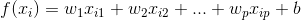
也可以写成矩阵的形式:
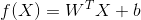
其中,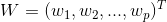 和
和 称为模型的参数。
称为模型的参数。
为了求解线性模型的参数 和,首先我们定义损失函数,在回归任务中,常用的损失函数是均方误差:
和,首先我们定义损失函数,在回归任务中,常用的损失函数是均方误差:
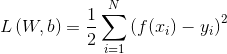
优化损失函数就是我们的目标,基于均方误差损失函数来求解模型参数的方差,也就是我们熟悉的最小二乘法,最小二乘法的思想其实就是寻找一个超平面,使得训练数据集 中的所有样本点到这个超平面的欧式距离最小。
中的所有样本点到这个超平面的欧式距离最小。
OK,接下来就是优化问题了,如何取优化该损失函数,从而获得最优模型参数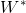 和
和 ,因为该损失函数是凸函数,根据极值存在的必要条件,我们可以运用解析法进行求解。
,因为该损失函数是凸函数,根据极值存在的必要条件,我们可以运用解析法进行求解。
下面我们将给出详细的推导求解和的过程:
1. 首先将参数和进行合并,用 来进行表示:
来进行表示:![]() , 容易知道
, 容易知道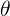 是
是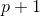 维度。
维度。
对输入特征向量进行改写,,则全体训练集,可用矩阵进行如下表示:
对输入特征向量的输出标签,可以改写为:
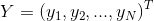
2. 根据1.我们可以知道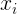 是一个
是一个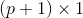 的列向量,这样模型的预测结果可以写成矩阵形式:
的列向量,这样模型的预测结果可以写成矩阵形式:
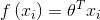
3. 根据1和2,损失函数可以转化为矩阵形式:


![]()
根据极值存在的必要条件,下面进行对参数的求导:
Method 1:
![]()
![]() ,这里的
,这里的![]()
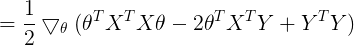
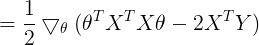
Method 2:
![]()
![]() 对上一步结果进行展开
对上一步结果进行展开
![]() 转换为迹运算
转换为迹运算
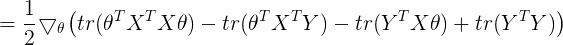 对上一步结果进行展开
对上一步结果进行展开
根据常见矩阵求导公式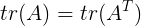 ,可知
,可知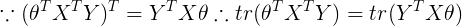
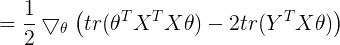
根据常见矩阵求导公式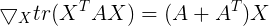 ,可知
,可知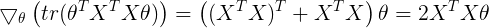
根据常见矩阵求导公式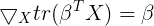 ,可知
,可知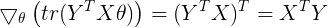
综上可知,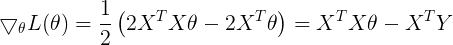
令![]() ,可得
,可得![]() ,求解得到
,求解得到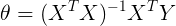
需要注意,要保证对称矩阵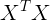 是可逆的,如果不可逆,则解析法求解失效。
是可逆的,如果不可逆,则解析法求解失效。
几何意义
1. 第一种几何解释
如下图所示:误差与所有的红色距离有关;

2. 第二种几何解释
把误差被分配到p个维度上;
由最小二乘法可知:
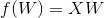
其中矩阵![]() 。
。
, 这里
 对一列一列来看,这
对一列一列来看,这 个N维向量就构成维子空间;这里的
个N维向量就构成维子空间;这里的![]() 是不在维子空间,除非数据集每个样本点都被完全拟合;
是不在维子空间,除非数据集每个样本点都被完全拟合;
在这里我们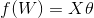 改写成
改写成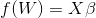 ;
;
几何意义:在维子空间找到一个平面![]() ,使得
,使得![]() 与此
与此![]() 最近,即
最近,即![]() 在维子空间的投影,则满足
在维子空间的投影,则满足![]() 与维子空间的基向量垂直。如下图所示:
与维子空间的基向量垂直。如下图所示:

综上可知: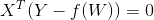
![]()
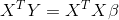
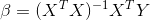
概率视角
概率视角主要考察最小二乘法与高斯分布之间的关系
考虑第 个样本
个样本 的真实输出
的真实输出 和
和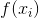 存在如下关系:
存在如下关系:
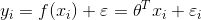
其中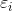 表示由噪声引起的误差项,服从均值0,标准差为
表示由噪声引起的误差项,服从均值0,标准差为 的高斯分布,则
的高斯分布,则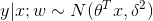 。
。
整理可得: ![]()
利用对数最大似然估计有:


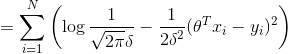
![]()
![]()
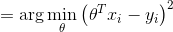 等价于损失函数
等价于损失函数
综上可知:最小二乘估计等价于噪声服从高斯分布的极大似然估计;
正则化
由上面可知,最小二乘的损失函数为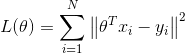 ,解析解为
,解析解为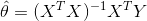 。
。
其中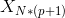 ,
, 个样本,
个样本,![]() ,多出来的一维度是因为方便与偏置加法计算。一般情况下,
,多出来的一维度是因为方便与偏置加法计算。一般情况下,![]() ;
;
模型过拟合的解决方案:
- 加数据
- 特征选择/特征提取.(PCA)
- 正则化
正则化框架如下:
![\arg \min_\theta \left [ L(\theta) + \lambda P(\theta) \right ]](http://img.e-com-net.com/image/info8/ab15f99b5c14455293f01f8f05788f51.gif)
其中,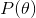 为惩罚项, L1: lasso,
为惩罚项, L1: lasso, ![]()
L2: Ridge, ![]()
带L1正则化的线性回归的损失函数:
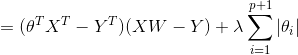

由于 的正负无法确定,因为这里将转换成
的正负无法确定,因为这里将转换成 进行求导,
进行求导,![]() 为符号函数。
为符号函数。
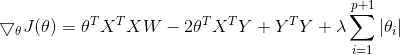

![]()
令![]() ,可得
,可得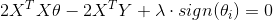 ,有
,有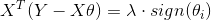 , 在这里是得不到解析解的,那么如何求解L1正则化的极小值呢?可采用坐标轴下降法(Coordinate Descent)和最小角回归法(Least Angle Regressionm), 此处不展开。
, 在这里是得不到解析解的,那么如何求解L1正则化的极小值呢?可采用坐标轴下降法(Coordinate Descent)和最小角回归法(Least Angle Regressionm), 此处不展开。
带L2正则化的线性回归的损失函数:

![]()
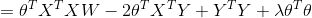
![]()
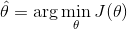
在前边已经详细推导过,这里不在详细推导,求导结果为 ![]()
令![]() ,可得
,可得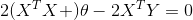 ,求解得到
,求解得到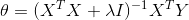
正则化的几何解释
带L2正则化的线性回归:
在最大似然估计中,是假设权重是未知的参数,从而求得对数似然函数:
在最大化后验概率估计中,是将权重看作随机变量,也具有某种概率分布,从而有:
![]()
利用最大化后验概率可以有:
后验概率函数: ![]()
后验概率函数是在似然函数的基础上增加了 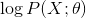 ,
,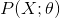 的意义为对权重系数的概率分布的先验假设,在收集到足够的数据集,则依据在数据集下的后验概率对权重系数进行修正,从而完成对权重系数的估计。
的意义为对权重系数的概率分布的先验假设,在收集到足够的数据集,则依据在数据集下的后验概率对权重系数进行修正,从而完成对权重系数的估计。
这里假设权重系数的先验分布为高斯分布,![]() .如下图所示:
.如下图所示:

则有:
![]() ,
,
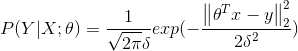
MAP:![]()


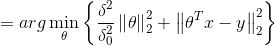
MAP: 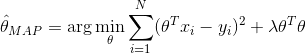 ,
, 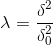
综上可知,最小二乘估计LSE 等价于 极大似然估计MLE(noise 为Gaussian Distribution)
L2正则化最小二乘估计Regularized LSE 等价于 最大后验概率估计MAP (priod 和 noise均为Gaussian Distribution)
同理,带L1正则化的线性回归:
这里假设权重系数的先验分布为拉普拉斯分布,.
则有:
![]() ,
,
MAP:![]()
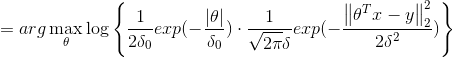


![]()
MAP: 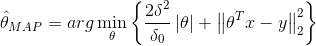 ,
, 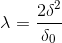
综上可知,最小二乘估计LSE 等价于 极大似然估计MLE(noise 为Gaussian Distribution)
L1正则化最小二乘估计Regularized LSE 等价于 最大后验概率估计MAP (priod 为Laplace Distribution,noise为Gaussian Distribution)
完,
【参考资料】
1. https://github.com/shuhuai007/Machine-Learning-Session
2. https://github.com/ws13685555932/machine_learning_derivation