Elasticsearch笔记(八):客户端连接
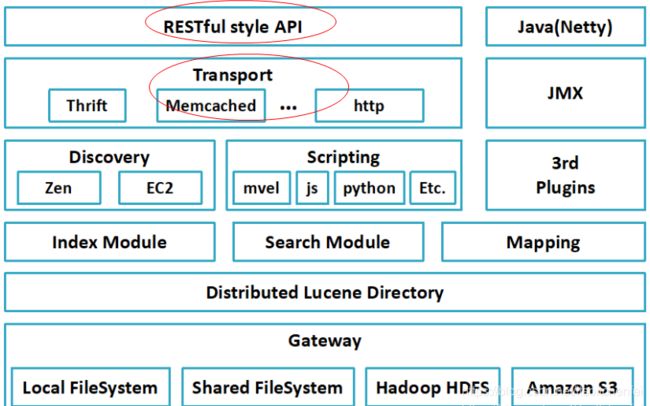
本节将讲解Elasticsearch提供的Client API,而重点讲解Java API。在之前的章节中讲过《es的架构》,在这个架构图中包含了两个很重要的ES交互客户端模块:RESTful style API(HTTP REST API ,端口 9200)和Transport(TCP方式,端口 9300)。
目录
1. 多语言支持
2. Java API
2.1 Node Client
2.2 Transport client
2.3 Document API
2.4 Search API
2.5 Aggregation
2.6 Query DSL
2.6 Java API Administration
2.7 spring-data-elasticsearch
3. Java REST Client
3.1 Java Low Level REST Client
3.2 Java High Level REST Client
3.2 API
1. 多语言支持
es的client支持很多语言,它们有:
- Java API
- Java REST Client
- JavaScript API
- Groovy API [2.4] — other versions
- .NET API [6.x] — other versions
- PHP API [6.0] — other versions
- Perl API
- Python API
- Ruby API
- Community Contributed Clients
2. Java API
它提供的功能:
- 在现有群集上执行标准 index, get, delete 和 search 操作
- 在正在运行的群集上执行管理任务
获取ES Client很简单,获取客户机的最常见方法是创建连接到集群的TransportClient。另外,它也有一个很可怕的缺点:client版本必须和ES有相同的主要版本(这都让很多开发者深受其害)。
警告
我们计划在Elasticsearch 7.0中对TransportClient进行弃用,并在8.0中完全删除它,替而代之,你应该使用Java高级REST客户端,它执行HTTP请求而不是序列化的Java请求。迁移指南描述了迁移所需的所有步骤。Java高级REST客户端目前支持更常用的API,但还有很多东西需要补充,您可以通过告诉我们您的应用程序需要哪些缺失的API来帮助我们优化优先级,通过向这个issue添加注释:Java高级REST客户端完整性。
任何丢失的API都可以通过使用具有JSON请求和响应主体的低级Java REST客户端来实现。
2.1 Node Client
Node client,也叫节点客户端。它是官方ES发行版的一部分,需要客户端运行Java等,但也有一些显着的差异。它作为一个非数据节点加入到本地集群中。它本身不保存任何数据,但是它知道数据在集群中的哪个节点中,并且可以把请求转发到正确的节点。这意味着节点客户端的存在被存储在群集状态,并且群集中的所有其他节点将尝试建立到客户端的几个tcp连接。如果群集很大或使用多个客户端,这可能是一个显着的缺点。
2.2 Transport client
Transport client, 轻量级传输客户端。它可以将请求发送到远程集群,它本身不加入集群,但是它可以将请求转发到集群中的一个节点上。需要客户端用Java编写(或至少在JVM上运行)。 它非常快,在JVM上本机运行。序列化是有效的,发送到ES实例的消息和操作中几乎没有开销。在Elasticsearch 1.0之前,将需要完全相同的版本,但较新的版本(1.0和更高版本)支持版本之间的交互。由于异常序列化和更新之间的其他潜在细微差异,在客户端和服务器上运行相同的JVM更新版本也是有益的。 目前不支持加密或身份验证,但是宣布不久会满足这些需求。
首先,添加maven中添加6.2.4版本。它封装了比较好,支持同步和异步。
public class Client_test {
private TransportClient client;
@Before
public void setUp() throws UnknownHostException {
if(client == null) {
// 连接集群的设置
Settings settings = Settings.builder()
//.put("cluster.name", "myClusterName")
.put("client.transport.sniff", true)
.build();
//client = new PreBuiltTransportClient(Settings.EMPTY)
client = new PreBuiltTransportClient(settings)
//.addTransportAddress(new TransportAddress(InetAddress.getByName("localhost"), 9300));//访问默认端口9300,
.addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
/*
* 参数说明:
*
cluster.name 指定集群的名字,如果集群的名字不是默认的elasticsearch,需指定。
client.transport.sniff 设置为true,将自动嗅探整个集群,自动加入集群的节点到连接列表中。
client.transport.ignore_cluster_name 设置true,忽略连接节点集群名验证
client.transport.ping_timeout ping一个节点的响应时间 默认5秒.
client.transport.nodes_sampler_interval sample/ping 节点的时间间隔,默认是5s
*/
}
}
}2.3 Document API
单文档API
- Index API
- Get API
- Delete API
- Update API
多文档API
- Multi Get API
- Bulk API
- Reindex API
- Update By Query API
- Delete By Query API
@Test
public void opDoc() {
//这里和RESTful风格不同
try{
// 1、创建索引请求
IndexRequest request = new IndexRequest(
"mess", //索引
"_doc", // mapping type
"11"); //文档id
// 2、准备文档数据
// 方式一:直接给JSON串
String jsonString = "{" +
"\"user\":\"kimchy\"," +
"\"postDate\":\"2013-01-30\"," +
"\"message\":\"trying out Elasticsearch\"" +
"}";
request.source(jsonString, XContentType.JSON);
// 方式二:以map对象来表示文档
/*
Map jsonMap = new HashMap<>();
jsonMap.put("user", "kimchy");
jsonMap.put("postDate", new Date());
jsonMap.put("message", "trying out Elasticsearch");
request.source(jsonMap);
*/
// 方式三:用XContentBuilder来构建文档
/*
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject();
{
builder.field("user", "kimchy");
builder.field("postDate", new Date());
builder.field("message", "trying out Elasticsearch");
}
builder.endObject();
request.source(builder);
*/
// 方式四:直接用key-value对给出
/*
request.source("user", "kimchy",
"postDate", new Date(),
"message", "trying out Elasticsearch");
*/
//3、其他的一些可选设置
/*
request.routing("routing"); //设置routing值
request.timeout(TimeValue.timeValueSeconds(1)); //设置主分片等待时长
request.setRefreshPolicy("wait_for"); //设置重刷新策略
request.version(2); //设置版本号
request.opType(DocWriteRequest.OpType.CREATE); //操作类别
*/
//4、发送请求
IndexResponse indexResponse = null;
try {
//方式一: 用client.index 方法,返回是 ActionFuture,再调用get获取响应结果
indexResponse = client.index(request).get();
//方式二:client提供了一个 prepareIndex方法,内部为我们创建IndexRequest
/*IndexResponse indexResponse = client.prepareIndex("mess","_doc","11")
.setSource(jsonString, XContentType.JSON)
.get();*/
//方式三:request + listener
//client.index(request, listener);
} catch(ElasticsearchException e) {
// 捕获,并处理异常
//判断是否版本冲突、create但文档已存在冲突
if (e.status() == RestStatus.CONFLICT) {
logger.error("冲突了,请在此写冲突处理逻辑!\n" + e.getDetailedMessage());
}
logger.error("索引异常", e);
}catch (InterruptedException | ExecutionException e) {
logger.error("索引异常", e);
}
//5、处理响应
if(indexResponse != null) {
String index = indexResponse.getIndex();
String type = indexResponse.getType();
String id = indexResponse.getId();
long version = indexResponse.getVersion();
if (indexResponse.getResult() == DocWriteResponse.Result.CREATED) {
System.out.println("新增文档成功,处理逻辑代码写到这里。");
} else if (indexResponse.getResult() == DocWriteResponse.Result.UPDATED) {
System.out.println("修改文档成功,处理逻辑代码写到这里。");
}
// 分片处理信息
ReplicationResponse.ShardInfo shardInfo = indexResponse.getShardInfo();
if (shardInfo.getTotal() != shardInfo.getSuccessful()) {
}
// 如果有分片副本失败,可以获得失败原因信息
if (shardInfo.getFailed() > 0) {
for (ReplicationResponse.ShardInfo.Failure failure : shardInfo.getFailures()) {
String reason = failure.reason();
System.out.println("副本失败原因:" + reason);
}
}
}
//listener 方式
/*ActionListener listener = new ActionListener() {
@Override
public void onResponse(IndexResponse indexResponse) {
}
@Override
public void onFailure(Exception e) {
}
};
client.index(request, listener);
*/
} catch (IOException e) {
e.printStackTrace();
}
}
2.4 Search API
搜索API允许用户执行搜索查询并返回与查询匹配的搜索结果。它可以跨一个或多个索引执行,也可以跨一个或多个类型执行。可以使用query Java API提供查询。使用SearchSourceBuilder生成搜索请求的正文。它用法包含:
- Using scrolls in Java
- MultiSearch API
- Using Aggregations
- Terminate After
- Search Template
@Test
public void opSearch() {
try{
// 1、创建search请求
//SearchRequest searchRequest = new SearchRequest();
SearchRequest searchRequest = new SearchRequest("bank");
searchRequest.types("_doc");
// 2、用SearchSourceBuilder来构造查询请求体 ,请仔细查看它的方法,构造各种查询的方法都在这。
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//构造QueryBuilder
/*QueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("user", "kimchy")
.fuzziness(Fuzziness.AUTO)
.prefixLength(3)
.maxExpansions(10);
sourceBuilder.query(matchQueryBuilder);*/
sourceBuilder.query(QueryBuilders.termQuery("age", 24));
sourceBuilder.from(0);
sourceBuilder.size(10);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//是否返回_source字段
//sourceBuilder.fetchSource(false);
//设置返回哪些字段
/*String[] includeFields = new String[] {"title", "user", "innerObject.*"};
String[] excludeFields = new String[] {"_type"};
sourceBuilder.fetchSource(includeFields, excludeFields);*/
//指定排序
//sourceBuilder.sort(new ScoreSortBuilder().order(SortOrder.DESC));
//sourceBuilder.sort(new FieldSortBuilder("_uid").order(SortOrder.ASC));
// 设置返回 profile
//sourceBuilder.profile(true);
//将请求体加入到请求中
searchRequest.source(sourceBuilder);
// 可选的设置
//searchRequest.routing("routing");
// 高亮设置
/*
HighlightBuilder highlightBuilder = new HighlightBuilder();
HighlightBuilder.Field highlightTitle =
new HighlightBuilder.Field("title");
highlightTitle.highlighterType("unified");
highlightBuilder.field(highlightTitle);
HighlightBuilder.Field highlightUser = new HighlightBuilder.Field("user");
highlightBuilder.field(highlightUser);
sourceBuilder.highlighter(highlightBuilder);*/
//加入聚合
/*TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_company")
.field("company.keyword");
aggregation.subAggregation(AggregationBuilders.avg("average_age")
.field("age"));
sourceBuilder.aggregation(aggregation);*/
//做查询建议
/*SuggestionBuilder termSuggestionBuilder =
SuggestBuilders.termSuggestion("user").text("kmichy");
SuggestBuilder suggestBuilder = new SuggestBuilder();
suggestBuilder.addSuggestion("suggest_user", termSuggestionBuilder);
sourceBuilder.suggest(suggestBuilder);*/
//3、发送请求
SearchResponse searchResponse = client.search(searchRequest).get();
//4、处理响应
//搜索结果状态信息
RestStatus status = searchResponse.status();
TimeValue took = searchResponse.getTook();
Boolean terminatedEarly = searchResponse.isTerminatedEarly();
boolean timedOut = searchResponse.isTimedOut();
//分片搜索情况
int totalShards = searchResponse.getTotalShards();
int successfulShards = searchResponse.getSuccessfulShards();
int failedShards = searchResponse.getFailedShards();
for (ShardSearchFailure failure : searchResponse.getShardFailures()) {
// failures should be handled here
}
//处理搜索命中文档结果
SearchHits hits = searchResponse.getHits();
long totalHits = hits.getTotalHits();
float maxScore = hits.getMaxScore();
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
// do something with the SearchHit
String index = hit.getIndex();
String type = hit.getType();
String id = hit.getId();
float score = hit.getScore();
//取_source字段值
String sourceAsString = hit.getSourceAsString(); //取成json串
Map sourceAsMap = hit.getSourceAsMap(); // 取成map对象
//从map中取字段值
/*
String documentTitle = (String) sourceAsMap.get("title");
List 2.5 Aggregation
弹性搜索提供了一个完整的Java API来进行聚合。将工厂用于聚合生成器(AggregationBuilders),并添加查询时要计算的每个聚合,并将其添加到搜索请求中。它功能有:
- Structuring aggregations
- Metrics aggregations
- Bucket aggregations
@Test
public void opAggregation() {
try{
// 1、创建search请求
//SearchRequest searchRequest = new SearchRequest();
SearchRequest searchRequest = new SearchRequest("bank");
// 2、用SearchSourceBuilder来构造查询请求体 ,请仔细查看它的方法,构造各种查询的方法都在这。
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.size(0);
//加入聚合
//字段值项分组聚合
TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_age")
.field("age").order(BucketOrder.aggregation("average_balance", true));
//计算每组的平均balance指标
aggregation.subAggregation(AggregationBuilders.avg("average_balance")
.field("balance"));
sourceBuilder.aggregation(aggregation);
searchRequest.source(sourceBuilder);
//3、发送请求
SearchResponse searchResponse = client.search(searchRequest);
//4、处理响应
//搜索结果状态信息
if(RestStatus.OK.equals(searchResponse.status())) {
// 获取聚合结果
Aggregations aggregations = searchResponse.getAggregations();
Terms byAgeAggregation = aggregations.get("by_age");
logger.info("aggregation by_age 结果");
logger.info("docCountError: " + byAgeAggregation.getDocCountError());
logger.info("sumOfOtherDocCounts: " + byAgeAggregation.getSumOfOtherDocCounts());
logger.info("------------------------------------");
for(Bucket buck : byAgeAggregation.getBuckets()) {
logger.info("key: " + buck.getKeyAsNumber());
logger.info("docCount: " + buck.getDocCount());
logger.info("docCountError: " + buck.getDocCountError());
//取子聚合
Avg averageBalance = buck.getAggregations().get("average_balance");
logger.info("average_balance: " + averageBalance.getValue());
logger.info("------------------------------------");
}
//直接用key 来去分组
/*Bucket elasticBucket = byCompanyAggregation.getBucketByKey("24");
Avg averageAge = elasticBucket.getAggregations().get("average_age");
double avg = averageAge.getValue();*/
}
} catch (IOException e) {
e.printStackTrace();
}
}2.6 Query DSL
弹性搜索以类似于REST Query DSL的方式提供完整的Java查询DSL。查询生成器的工厂是QueryBuilders。一旦您的查询就绪,就可以使用Search API。它功能有:
- Match All Query
- Full text queries
- Term level queries
- Compound queries
- Joining queries
- Geo queries
- Specialized queries
- Span queries
@Test
public void opHighlight() {
try{
// 1、创建search请求
SearchRequest searchRequest = new SearchRequest("hl_test");
// 2、用SearchSourceBuilder来构造查询请求体 ,请仔细查看它的方法,构造各种查询的方法都在这。
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//构造QueryBuilder
QueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("title", "lucene solr");
sourceBuilder.query(matchQueryBuilder);
//分页设置
/*sourceBuilder.from(0);
sourceBuilder.size(5); ;*/
// 高亮设置
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.requireFieldMatch(false).field("title").field("content")
.preTags("").postTags("");
//不同字段可有不同设置,如不同标签
/*HighlightBuilder.Field highlightTitle = new HighlightBuilder.Field("title");
highlightTitle.preTags("").postTags("");
highlightBuilder.field(highlightTitle);
HighlightBuilder.Field highlightContent = new HighlightBuilder.Field("content");
highlightContent.preTags("").postTags("");
highlightBuilder.field(highlightContent).requireFieldMatch(false);*/
sourceBuilder.highlighter(highlightBuilder);
searchRequest.source(sourceBuilder);
//3、发送请求
SearchResponse searchResponse = client.search(searchRequest);
//4、处理响应
if(RestStatus.OK.equals(searchResponse.status())) {
//处理搜索命中文档结果
SearchHits hits = searchResponse.getHits();
long totalHits = hits.getTotalHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
String index = hit.getIndex();
String type = hit.getType();
String id = hit.getId();
float score = hit.getScore();
//取_source字段值
//String sourceAsString = hit.getSourceAsString(); //取成json串
Map sourceAsMap = hit.getSourceAsMap(); // 取成map对象
//从map中取字段值
/*String title = (String) sourceAsMap.get("title");
String content = (String) sourceAsMap.get("content"); */
logger.info("index:" + index + " type:" + type + " id:" + id);
logger.info("sourceMap : " + sourceAsMap);
//取高亮结果
Map highlightFields = hit.getHighlightFields();
HighlightField highlight = highlightFields.get("title");
if(highlight != null) {
Text[] fragments = highlight.fragments(); //多值的字段会有多个值
if(fragments != null) {
String fragmentString = fragments[0].string();
logger.info("title highlight : " + fragmentString);
//可用高亮字符串替换上面sourceAsMap中的对应字段返回到上一级调用
//sourceAsMap.put("title", fragmentString);
}
}
highlight = highlightFields.get("content");
if(highlight != null) {
Text[] fragments = highlight.fragments(); //多值的字段会有多个值
if(fragments != null) {
String fragmentString = fragments[0].string();
logger.info("content highlight : " + fragmentString);
//可用高亮字符串替换上面sourceAsMap中的对应字段返回到上一级调用
//sourceAsMap.put("content", fragmentString);
}
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
} 2.6 Java API Administration
ES提供了一个完整的Java API来处理管理任务。要访问它们,需要从client调用admin()方法以获取AdminClient。
- Indices Administration,IndicesAdminClient indicesAdminClient = client.admin().indices();
- Cluster Administration,ClusterAdminClient clusterAdminClient = client.admin().cluster();
2.7 spring-data-elasticsearch
spring-data-elasticsearch是基于Transport client实现的。
为何要专门讲这个呢?其实Spring Data Elasticsearch对es client对封装的想法是好的,只是不适用!什么不适用呢?由于es 版本更新太快了,导致Spring Data版本跟进比较慢。作为一个过路人的经验,如果你的es版本比较旧,可以使用,如果你的版本比较新,尽可能不要用,否则面临各种无穷无尽的API兼容问题。
3. Java REST Client
默认端口9200,JAVA REST client优点语言无关。由Elasticsearch编写和支持的官方(非Java)客户端都使用HTTP底层与Elasticsearch进行通信。但是,一些重要的事情需要由客户端实现:连接池(以避免必须支付每个请求的TCP连接建立成本)和保持活动。一般建议是使用封装HTTP API的正式客户端,因为他们负责处理所有这些细节。Elasticsearch的HTTP API被广泛使用,并且具有相当多的社区支持。
3.1 Java Low Level REST Client
Java Low Level REST Client,低级别的REST客户端,通过http与集群交互,用户需自己编组请求JSON串,及解析响应JSON串。兼容所有ES版本。最小Java版本要求为1.7。
org.elasticsearch.client
elasticsearch-rest-client
6.2.4
3.2 Java High Level REST Client
Java High Level REST Client, 高级别的REST客户端,基于低级别的REST客户端,增加了编组请求JSON串、解析响应JSON串等相关api。使用的版本需要保持和ES服务端的版本一致,否则会有版本问题。
从6.0.0开始加入的,目的是以java面向对象的方式来进行请求、响应处理。每个API 支持 同步/异步 两种方式,同步方法直接返回一个结果对象。异步的方法以async为后缀,通过listener参数来通知结果。
兼容性情况:
- 依赖 java1.8
- 请使用与服务端ES版本一致的客户端版本
org.elasticsearch.client
elasticsearch-rest-high-level-client
6.2.4
public class RestClient_test {
public RestHighLevelClient getClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http"),
new HttpHost("localhost", 9201, "http")));
return client;
}
}3.2 API
Java高级REST客户端依赖于提供不同类型的Java建设者对象的弹性搜索核心项目,包括:
Query Builders
查询生成器用于创建要在搜索请求中执行的查询。查询DSL支持的每种查询类型都有一个查询生成器。每个查询生成器实现QueryBuilder接口,并允许为给定类型的查询设置特定选项。创建后,可以将querybuilder对象设置为searchsourcebuilder的查询参数。 Search Request页面显示了如何使用SearchSourceBuilder和QueryBuilder对象生成完整搜索请求的示例。Building Search Queries页面提供所有可用搜索查询及其相应的QueryBuilder对象和QueryBuilder帮助器方法的列表。
Aggregation Builders
与查询生成器类似,聚合生成器用于创建要在搜索请求执行期间计算的聚合。ElasticSearch支持的每种聚合(或管道聚合)都有一个聚合生成器。所有生成器继承AggregationBuilder类,一旦创建,就可以将aggregationbuilder对象设置为searchsourcebuilder的聚合参数。 Building Aggregations 页提供所有可用聚合的列表及其相应的AggregationBuilder对象和AggregationBuilder帮助器方法。
提供的API包含:
- Create Index API
- Delete Index API
- Open Index API
- Close Index API
- Index API
- Get API
- Delete API
- Update API
- Bulk API
- Search API
- Search Scroll API
- Clear Scroll API
- Info API
public class RestClient_test {
@Test
public void createIndex() {
try (RestHighLevelClient client = getClient();) {
CreateIndexRequest request = new CreateIndexRequest("mess");
request.settings(Settings.builder().put("index.number_of_shards", 3) // 分片数
.put("index.number_of_replicas", 2) // 副本数
.put("analysis.analyzer.default.tokenizer", "ik_smart") // 默认分词器
);
//设置索引的mappings
request.mapping("_doc",
" {\n" +
" \"_doc\": {\n" +
" \"properties\": {\n" +
" \"message\": {\n" +
" \"type\": \"text\"\n" +
" }\n" +
" }\n" +
" }\n" +
" }",
XContentType.JSON);
// 设置索引的别名
request.alias(new Alias("mmm"));
// 发送请求
// 同步方式发送请求
CreateIndexResponse createIndexResponse = client.indices()
.create(request);
boolean acknowledged = createIndexResponse.isAcknowledged();
boolean shardsAcknowledged = createIndexResponse
.isShardsAcknowledged();
System.out.println("acknowledged = " + acknowledged);
System.out.println("shardsAcknowledged = " + shardsAcknowledged);
//异步方式发送请求
/*ActionListener listener = new ActionListener() {
@Override
public void onResponse(
CreateIndexResponse createIndexResponse) {
boolean acknowledged = createIndexResponse.isAcknowledged();
boolean shardsAcknowledged = createIndexResponse
.isShardsAcknowledged();
System.out.println("acknowledged = " + acknowledged);
System.out.println(
"shardsAcknowledged = " + shardsAcknowledged);
}
@Override
public void onFailure(Exception e) {
System.out.println("创建索引异常:" + e.getMessage());
}
};
client.indices().createAsync(request, listener);
*/
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void indexDocument() {
try (RestHighLevelClient client = getClient();) {
IndexRequest request = new IndexRequest(
"mess", //索引
"_doc", // mapping type
"1"); //文档id
// 方式一:直接给JSON串
String jsonString = "{" +
"\"user\":\"kimchy\"," +
"\"postDate\":\"2013-01-30\"," +
"\"message\":\"trying out Elasticsearch\"" +
"}";
request.source(jsonString, XContentType.JSON);
// 方式二:以map对象来表示文档
/*
Map jsonMap = new HashMap<>();
jsonMap.put("user", "kimchy");
jsonMap.put("postDate", new Date());
jsonMap.put("message", "trying out Elasticsearch");
request.source(jsonMap);
*/
// 方式三:用XContentBuilder来构建文档
/*
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject();
{
builder.field("user", "kimchy");
builder.field("postDate", new Date());
builder.field("message", "trying out Elasticsearch");
}
builder.endObject();
request.source(builder);
*/
// 方式四:直接用key-value对给出
/*
request.source("user", "kimchy",
"postDate", new Date(),
"message", "trying out Elasticsearch");
*/
//3、其他的一些可选设置
/*
request.routing("routing"); //设置routing值
request.timeout(TimeValue.timeValueSeconds(1)); //设置主分片等待时长
request.setRefreshPolicy("wait_for"); //设置重刷新策略
request.version(2); //设置版本号
request.opType(DocWriteRequest.OpType.CREATE); //操作类别
*/
//4、发送请求
IndexResponse indexResponse = null;
try {
// 同步方式
indexResponse = client.index(request);
} catch (ElasticsearchException e) {
// 捕获,并处理异常
//判断是否版本冲突、create但文档已存在冲突
if (e.status() == RestStatus.CONFLICT) {
logger.error("冲突了,请在此写冲突处理逻辑!\n" + e.getDetailedMessage());
}
logger.error("索引异常", e);
}
//5、处理响应
if (indexResponse != null) {
String index = indexResponse.getIndex();
String type = indexResponse.getType();
String id = indexResponse.getId();
long version = indexResponse.getVersion();
if (indexResponse.getResult() == DocWriteResponse.Result.CREATED) {
System.out.println("新增文档成功,处理逻辑代码写到这里。");
} else if (indexResponse.getResult() == DocWriteResponse.Result.UPDATED) {
System.out.println("修改文档成功,处理逻辑代码写到这里。");
}
// 分片处理信息
ReplicationResponse.ShardInfo shardInfo = indexResponse.getShardInfo();
if (shardInfo.getTotal() != shardInfo.getSuccessful()) {
}
// 如果有分片副本失败,可以获得失败原因信息
if (shardInfo.getFailed() > 0) {
for (ReplicationResponse.ShardInfo.Failure failure : shardInfo.getFailures()) {
String reason = failure.reason();
System.out.println("副本失败原因:" + reason);
}
}
}
//异步方式发送索引请求
/*ActionListener listener = new ActionListener() {
@Override
public void onResponse(IndexResponse indexResponse) {
}
@Override
public void onFailure(Exception e) {
}
};
client.indexAsync(request, listener);
*/
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void getDocument() {
try (RestHighLevelClient client = getClient();) {
GetRequest request = new GetRequest(
"mess", //索引
"_doc", // mapping type
"1"); //文档id
// 2、可选的设置
//request.routing("routing");
//request.version(2);
//request.fetchSourceContext(new FetchSourceContext(false)); //是否获取_source字段
//选择返回的字段
String[] includes = new String[]{"message", "*Date"};
String[] excludes = Strings.EMPTY_ARRAY;
FetchSourceContext fetchSourceContext = new FetchSourceContext(true, includes, excludes);
request.fetchSourceContext(fetchSourceContext);
//也可写成这样
/*String[] includes = Strings.EMPTY_ARRAY;
String[] excludes = new String[]{"message"};
FetchSourceContext fetchSourceContext = new FetchSourceContext(true, includes, excludes);
request.fetchSourceContext(fetchSourceContext);*/
// 取stored字段
/*request.storedFields("message");
GetResponse getResponse = client.get(request);
String message = getResponse.getField("message").getValue();*/
//3、发送请求
GetResponse getResponse = null;
try {
// 同步请求
getResponse = client.get(request);
} catch (ElasticsearchException e) {
if (e.status() == RestStatus.NOT_FOUND) {
logger.error("没有找到该id的文档");
}
if (e.status() == RestStatus.CONFLICT) {
logger.error("获取时版本冲突了,请在此写冲突处理逻辑!");
}
logger.error("获取文档异常", e);
}
//4、处理响应
if (getResponse != null) {
String index = getResponse.getIndex();
String type = getResponse.getType();
String id = getResponse.getId();
if (getResponse.isExists()) { // 文档存在
long version = getResponse.getVersion();
String sourceAsString = getResponse.getSourceAsString(); //结果取成 String
Map sourceAsMap = getResponse.getSourceAsMap(); // 结果取成Map
byte[] sourceAsBytes = getResponse.getSourceAsBytes(); //结果取成字节数组
logger.info("index:" + index + " type:" + type + " id:" + id);
logger.info(sourceAsString);
} else {
logger.error("没有找到该id的文档");
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void bulk() {
try (RestHighLevelClient client = getClient();) {
// 1、创建批量操作请求
BulkRequest request = new BulkRequest();
request.add(new IndexRequest("mess", "_doc", "1")
.source(XContentType.JSON, "field", "foo"));
request.add(new IndexRequest("mess", "_doc", "2")
.source(XContentType.JSON, "field", "bar"));
request.add(new IndexRequest("mess", "_doc", "3")
.source(XContentType.JSON, "field", "baz"));
/*
request.add(new DeleteRequest("mess", "_doc", "3"));
request.add(new UpdateRequest("mess", "_doc", "2")
.doc(XContentType.JSON,"other", "test"));
request.add(new IndexRequest("mess", "_doc", "4")
.source(XContentType.JSON,"field", "baz"));
*/
// 2、可选的设置
/*
request.timeout("2m");
request.setRefreshPolicy("wait_for");
request.waitForActiveShards(2);
*/
// 同步请求
BulkResponse bulkResponse = client.bulk(request);
if (bulkResponse != null) {
for (BulkItemResponse bulkItemResponse : bulkResponse) {
DocWriteResponse itemResponse = bulkItemResponse.getResponse();
if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.INDEX
|| bulkItemResponse.getOpType() == DocWriteRequest.OpType.CREATE) {
IndexResponse indexResponse = (IndexResponse) itemResponse;
//TODO 新增成功的处理
} else if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.UPDATE) {
UpdateResponse updateResponse = (UpdateResponse) itemResponse;
//TODO 修改成功的处理
} else if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.DELETE) {
DeleteResponse deleteResponse = (DeleteResponse) itemResponse;
//TODO 删除成功的处理
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void search() {
try (RestHighLevelClient client = getClient();) {
//SearchRequest searchRequest = new SearchRequest();
SearchRequest searchRequest = new SearchRequest("bank");
searchRequest.types("_doc");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//构造QueryBuilder
/*QueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("user", "kimchy")
.fuzziness(Fuzziness.AUTO)
.prefixLength(3)
.maxExpansions(10);
sourceBuilder.query(matchQueryBuilder);*/
sourceBuilder.query(QueryBuilders.termQuery("age", 24));
sourceBuilder.from(0);
sourceBuilder.size(10);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//是否返回_source字段
//sourceBuilder.fetchSource(false);
//设置返回哪些字段
/*String[] includeFields = new String[] {"title", "user", "innerObject.*"};
String[] excludeFields = new String[] {"_type"};
sourceBuilder.fetchSource(includeFields, excludeFields);*/
//指定排序
//sourceBuilder.sort(new ScoreSortBuilder().order(SortOrder.DESC));
//sourceBuilder.sort(new FieldSortBuilder("_uid").order(SortOrder.ASC));
// 设置返回 profile
//sourceBuilder.profile(true);
//将请求体加入到请求中
searchRequest.source(sourceBuilder);
// 可选的设置
//searchRequest.routing("routing");
// 高亮设置
/*
HighlightBuilder highlightBuilder = new HighlightBuilder();
HighlightBuilder.Field highlightTitle =
new HighlightBuilder.Field("title");
highlightTitle.highlighterType("unified");
highlightBuilder.field(highlightTitle);
HighlightBuilder.Field highlightUser = new HighlightBuilder.Field("user");
highlightBuilder.field(highlightUser);
sourceBuilder.highlighter(highlightBuilder);*/
//加入聚合
/*TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_company")
.field("company.keyword");
aggregation.subAggregation(AggregationBuilders.avg("average_age")
.field("age"));
sourceBuilder.aggregation(aggregation);*/
//做查询建议
/*SuggestionBuilder termSuggestionBuilder =
SuggestBuilders.termSuggestion("user").text("kmichy");
SuggestBuilder suggestBuilder = new SuggestBuilder();
suggestBuilder.addSuggestion("suggest_user", termSuggestionBuilder);
sourceBuilder.suggest(suggestBuilder);*/
//3、发送请求
SearchResponse searchResponse = client.search(searchRequest);
//4、处理响应
//搜索结果状态信息
RestStatus status = searchResponse.status();
TimeValue took = searchResponse.getTook();
Boolean terminatedEarly = searchResponse.isTerminatedEarly();
boolean timedOut = searchResponse.isTimedOut();
//分片搜索情况
int totalShards = searchResponse.getTotalShards();
int successfulShards = searchResponse.getSuccessfulShards();
int failedShards = searchResponse.getFailedShards();
for (ShardSearchFailure failure : searchResponse.getShardFailures()) {
// failures should be handled here
}
//处理搜索命中文档结果
SearchHits hits = searchResponse.getHits();
long totalHits = hits.getTotalHits();
float maxScore = hits.getMaxScore();
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
// do something with the SearchHit
String index = hit.getIndex();
String type = hit.getType();
String id = hit.getId();
float score = hit.getScore();
//取_source字段值
String sourceAsString = hit.getSourceAsString(); //取成json串
Map sourceAsMap = hit.getSourceAsMap(); // 取成map对象
//从map中取字段值
/*
String documentTitle = (String) sourceAsMap.get("title");
List 结论
使用一个高性能的HTTP客户端,很容易和官方语言绑定。使用Java,一般通过transport优于node,除非使用节点客户端的性能增益足够大,以保证额外的网络复杂性。使用基准来验证性能提升。