djang+vue+framework 第十一天,更改生鲜超市为图书超市
新人学习django 是按照这个大佬的教程学习的
链接: https://www.cnblogs.com/derek1184405959/p/8733194.html.
很多步骤都是按照上面的教程学习的,这里只是记录一下自己学习的过程和一些错误
如果有人想要系统的学习,建议去上面那位大佬处学习
1.首先去当当网爬数据

通过源代码发现可以通过这两个字段去爬取图书的分类
点开不是主分类的分类,例如侦探悬疑
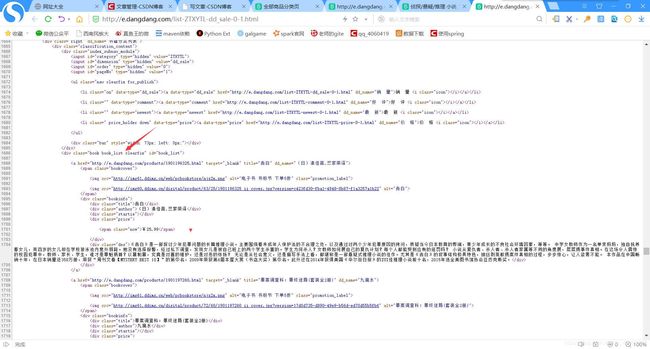
可以通过这个字段去爬取图书的信息
然后开始爬取数据
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import Select,WebDriverWait
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.remote.webelement import WebElement
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
import time
import random
import numpy as np
import json
import pandas as pd
#各种user_agent 防治反爬虫
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2226.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.4; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36",
"Opera/9.80 (X11; Linux i686; Ubuntu/14.10) Presto/2.12.388 Version/12.16",
"Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14",
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1",
"Mozilla/5.0 (Windows NT 6.3; rv:36.0) Gecko/20100101 Firefox/36.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10; rv:33.0) Gecko/20100101 Firefox/33.0",
"Mozilla/5.0 (X11; Linux i586; rv:31.0) Gecko/20100101 Firefox/31.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20130401 Firefox/31.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/7046A194A",
"Mozilla/5.0 (iPad; CPU OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5355d Safari/8536.25",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8) AppleWebKit/537.13+ (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/534.55.3 (KHTML, like Gecko) Version/5.1.3 Safari/534.53.10",
"Mozilla/5.0 (iPad; CPU OS 5_1 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko ) Version/5.1 Mobile/9B176 Safari/7534.48.3",
]
#谷歌浏览器的插件,控制浏览器进行点击等操作
drive_path=r"E:\spark和机器学习\机器学习\爬虫\chromedriver.exe"
#初始化对象进行使用
#浏览器的操作
options=webdriver.ChromeOptions()
#随机产生user_agent
def change_user_agent(options,USER_AGENTS):
user_agent=random.choice(USER_AGENTS)
options.add_argument('User-Agent=%s'%user_agent)
driver=webdriver.Chrome(chrome_options=options,executable_path=drive_path)
#爬取的网页路径
first_url="http://e.dangdang.com/classification_list_page.html?category=ZTXYTL&dimension=dd_sale&order=0"
driver.get(url=first_url)
#随便加载一个元素(class),之后开始获取页面
WebDriverWait(driver=driver,timeout=10).until(
EC.presence_of_all_elements_located((By.CLASS_NAME,'new_aside'))
)
#分析每一页的html,找到需要的元素,并保存
#获取到书本的分类,和该分类书的url
def get_books_categorys(resource,categorys_list,urls_list):
#解析数据
soup=BeautifulSoup(resource,'lxml')
#观察网页,提取元素
categorys=soup.find_all('dl',class_='new_title ')
for category in categorys:
category_list = []
url_list=[]
sub_categorys=category.find_all('a')
for category in sub_categorys[1:]:
category_list.append({'code':"wtt",'name':category.get_text()})
url_list.append({category.get_text():category.get("href")})
categorys_list.append({'sub_categorys':
[{'sub_categorys':
category_list,
'code':'wtt','name':sub_categorys[0].get_text()}]
,'code':"wtt",'name':sub_categorys[0].get_text()})
urls_list.append({sub_categorys[0].get_text(): url_list})
categorys = soup.find_all('dl', class_='new_title even')
for category in categorys:
url_list=[]
category_list = []
sub_categorys = category.find_all('a')
for category in sub_categorys[1:]:
category_list.append({'code': "wtt", 'name': category.get_text()})
url_list.append({category.get_text(): category.get("href")})
categorys_list.append({'sub_categorys': [{'sub_categorys': category_list, 'code': 'wtt',
'name': sub_categorys[0].get_text()}],
'code': "wtt", 'name': sub_categorys[0].get_text()})
url_list.append({category.get_text(): category.get("href")})
caterorys_list=[]
urls_list=[]
get_books_categorys(resource=driver.page_source,categorys_list=caterorys_list,urls_list=urls_list)
def get_books_url(urls_list):
book_data=[]
for url in urls_list:
#分类1
category1=list(url.keys())[0]
for category in url[category1]:
#分类2
category2=list(category.keys())[0]
categorys=['首页',category1,category2]
get_books(url=category[category2],categorys=categorys,book_data=book_data)
#以字典文件的格式将数据写入到文件中
data=open("./book_data.py",'w',encoding='utf-8')
jsonobj=json.dumps(book_data,ensure_ascii=False)
data.write(jsonobj)
print("over")
data.close()
def get_books(url,categorys,book_data):
driver.get(url=url)
# 随便加载一个元素(class),之后开始获取页面
WebDriverWait(driver=driver, timeout=10).until(
EC.presence_of_all_elements_located((By.CLASS_NAME, 'new_aside'))
)
soup = BeautifulSoup(driver.page_source, 'lxml')
books=soup.find_all('div',class_='book book_list clearfix')[0].find_all('a')
i =0
for book in books:
# 获取价格
try:
price = book.find_all('span', class_='now')[0].get_text()
except:
price=''
# 获取img_url
try:
img_url = book.find_all('img')[1].get("src")
except:
img_url=''
# 获取书名
try:
book_name = book.find_all('div', class_="title")[0].get_text()
except:
book_name=''
# 获取作者
try:
book_author = book.find_all('div', class_='author')[0].get_text()
except:
book_author=''
# 获取书的介绍
try:
book_desc = book.find_all('div', class_='des')[0].get_text()
except:
book_desc=''
book_categorys=[categorys]
# 保存到文本 pd.DataFrame(columns=['img_url','title','author','detail','bookClass','bookPrice','codeCount','pubtime'])
df.loc[img_url] = np.nan # none
df.loc[img_url]['img_url'] = img_url
df.loc[img_url]['name'] = book_name
df.loc[img_url]['author'] = book_author
df.loc[img_url]['book_category'] = categorys
df.loc[img_url]['bookPrice'] = price
df.loc[img_url]['desc'] = book_desc
# 刷新到文本 csv
df.to_csv('./dangdang_book.csv')
# 反反爬虫
change_user_agent(options, USER_AGENTS)
time.sleep(random.randint(0,5))
book = {'categorys': categorys, 'sale_price': price, 'name': book_name, 'desc': book_desc,
'author': book_author, 'images': img_url}
book_data.append(book)
if(i<2):
i=i+1
else:
break
#dataframe
df=pd.DataFrame(columns=['img_url','name','author','book_category','bookPrice','desc'])
get_books_url(urls_list=urls_list)
#将分类的信息写入数据文件
category_data=open('./category_data.py','w',encoding="utf-8")
jsonObj=json.dumps(caterorys_list,ensure_ascii=False)
category_data.write(jsonObj)
category_data.close()
为了方便和以前导入数据的代码不冲突,这里我把数据保存的格式和前面json数据格式一样
没有爬取太多的数据,每个具体分类大概只有一两本
分类的数据
[{"sub_categorys": [{"sub_categorys": [{"code": "wtt", "name": "侦探/悬疑/推理 "}, {"code": "wtt", "name": "情感/都市"}, {"code": "wtt", "name": "科幻/魔幻"}, {"code": "wtt", "name": "作品集"}, {"code": "wtt", "name": "外国小说"}], "code": "wtt", "name": "小说"}], "code": "wtt", "name": "小说"}, {"sub_categorys": [{"sub_categorys": [{"code": "wtt", "name": "哲学/宗教"}, {"code": "wtt", "name": "历史"}, {"code": "wtt", "name": "政治/军事"}, {"code": "wtt", "name": "文化"}, {"code": "wtt", "name": "社会科学"}, {"code": "wtt", "name": "古籍"}, {"code": "wtt", "name": "法律"}], "code": "wtt", "name": "历史文化"}], "code": "wtt", "name": "历史文化"}, {"sub_categorys": [{"sub_categorys": [{"code": "wtt", "name": "心理学"}, {"code": "wtt", "name": "女性心理学"}, {"code": "wtt", "name": "儿童心理学"}, {"code": "wtt", "name": "情绪管理"}, {"code": "wtt", "name": "职场/人际交往"}, {"code": "wtt", "name": "人生哲学"}], "code": "wtt", "name": "心理/励志"}], "code": "wtt", "name": "心理/励志"}, {"sub_categorys": [{"sub_categorys": [{"code": "wtt", "name": "儿童文学"}, {"code": "wtt", "name": "启蒙读物"}, {"code": "wtt", "name": "少儿英语"}, {"code": "wtt", "name": "动漫/图画书"}], "code": "wtt", "name": "童书"}], "code": "wtt", "name": "童书"}, {"sub_categorys": [{"sub_categorys": [{"code": "wtt", "name": "外文原版书"}, {"code": "wtt", "name": "港台圖書"}, {"code": "wtt", "name": "小语种"}], "code": "wtt", "name": "原版书"}], "code": "wtt", "name": "原版书"}, {"sub_categorys": [{"sub_categorys": [{"code": "wtt", "name": "文学"}, {"code": "wtt", "name": "青春文学"}, {"code": "wtt", "name": "传记"}, {"code": "wtt", "name": "艺术"}, {"code": "wtt", "name": "动漫/幽默"}], "code": "wtt", "name": "文艺"}], "code": "wtt", "name": "文艺"}, {"sub_categorys": [{"sub_categorys": [{"code": "wtt", "name": "管理"}, {"code": "wtt", "name": "经济"}, {"code": "wtt", "name": "投资理财"}, {"code": "wtt", "name": "市场/营销"}, {"code": "wtt", "name": "商务沟通"}, {"code": "wtt", "name": "中国经济"}, {"code": "wtt", "name": "国际经济"}], "code": "wtt", "name": "经济/管理"}], "code": "wtt", "name": "经济/管理"}, {"sub_categorys": [{"sub_categorys": [{"code": "wtt", "name": "两性关系"}, {"code": "wtt", "name": "亲子/家教"}, {"code": "wtt", "name": "旅游/地图"}, {"code": "wtt", "name": "烹饪/美食"}, {"code": "wtt", "name": "保健/养生"}], "code": "wtt", "name": "生活"}], "code": "wtt", "name": "生活"}, {"sub_categorys": [{"sub_categorys": [{"code": "wtt", "name": "科普读物"}, {"code": "wtt", "name": "计算机/网络"}, {"code": "wtt", "name": "自然科学"}, {"code": "wtt", "name": "中小学教辅"}, {"code": "wtt", "name": "考试"}, {"code": "wtt", "name": "外语"}, {"code": "wtt", "name": "工具书"}], "code": "wtt", "name": "科技/教育"}], "code": "wtt", "name": "科技/教育"}]
书本的数据,只取了第一本,观察格式
[{"categorys": ["首页", "小说", "侦探/悬疑/推理 "], "sale_price": "¥12.99", "name": "镇库狂沙", "desc": "胡八一陪Shirley杨回得州老家扫墓,竟发现祖父鹧鸪哨之墓神秘被盗,墓中尸体也神秘消失。惊怒之余,二人一路追查后惊奇发现,此事件并不是一件单纯的盗墓窃尸案,它的背后竟然与一尊古代彩陶和精绝古城有关,而随着故事的不断发展,胡八一也被牵扯进一个预谋已久的谜局,他们不得不重新上阵,再下龙穴……", "author": "天下霸唱", "images": "http://img60.ddimg.cn/digital/product/26/95/1901212695_ii_cover.jpg?version=3ecf3407-1327-4550-a01f-f414007e1614"}]
下载从网上获取的书本的图片,同时更改书本数据中的图片的url
from db_tools.data.book_data import row_data
import urllib.request
i=1
for book in row_data:
imageUrl=book["images"]
path="D:\\Project\\pycharm\\PycharmProjects\\MxShop\\media\\goods\\images\\" +str(i)+ ".jpg"
if imageUrl!='':
urllib.request.urlretrieve(imageUrl,path)
book["images"]="goods/images/"+str(i)+".jpg"
i=i+1
print(row_data)
清空以前的数据
添加goods的model的author字段
运行python manage.py makemigrations
python manage.py migrate
导入新的数据
书本数据
import sys
import os
pwd=os.path.dirname(os.path.realpath(__file__))
sys.path.append(pwd+"../")
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MxShop.settings')
import django
django.setup()
from apps.goods.models import Goods,GoodsCategory,GoodsImage
from db_tools.downloadsImages import row_data
for goods_detail in row_data:
goods=Goods()
goods.name=goods_detail["name"]
#前端中是¥232,数据库中是float类型,所以要替换掉
goods.author=goods_detail["author"]
goods.shop_price=float(float(goods_detail["sale_price"].replace("¥","").replace("元","")))
goods.market_price = goods.shop_price*1.2
goods.goods_brief=goods_detail["desc"] if goods_detail["desc"] is not None else ""
goods.goods_desc=goods_detail["desc"] if goods_detail["desc"] is not None else ""
#取第一张图片作为封面
goods.goods_front_image=goods_detail["images"] if goods_detail["images"] else ""
#取最后一个
category_name=goods_detail["categorys"][-1]
#取出当前子类对应的GoodsCateGory对象,filter没有匹配的会返回空数组,不会抛异常
category=GoodsCategory.objects.filter(name=category_name)
if category:
goods.category=category[0]
goods.save()
goods_image=goods_detail["images"] if goods_detail["images"] else ""
goods_image_instance=GoodsImage()
goods_image_instance.image=goods_image
goods_image_instance.goods=goods
goods_image_instance.save()
分类数据
#独立使用django的model,将数据导入到数据库中
import sys
import os
#获取当前的文件的路径,运行脚本
pwd=os.path.dirname(os.path.realpath(__file__))
#获取项目的根目录
sys.path.append(pwd+"../")
#要想使用django的model需要指定一个环境变量,会去settings配置找
#可以参照manage.py设置
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MxShop.settings')
import django
django.setup()
#这里要将路径写完整
from apps.goods.models import GoodsCategory
from db_tools.data.book_category_data import row_data
#一级类
for lev1_cat in row_data:
#这里处理相当于对json文件的处理
lev1_intance=GoodsCategory()
lev1_intance.code=lev1_cat["code"]
lev1_intance.name=lev1_cat["name"]
lev1_intance.category_type=1
#保存到数据库
lev1_intance.save()
#二级类
for lev2_cat in lev1_cat["sub_categorys"]:
lev2_intance=GoodsCategory()
lev2_intance.code=lev2_cat["code"]
lev2_intance.name=lev2_cat["name"]
lev2_intance.category_type=2
lev2_intance.parent_category=lev1_intance
lev2_intance.save()
#三级类
for lev3_cat in lev2_cat["sub_categorys"]:
lev3_intance=GoodsCategory()
lev3_intance.code=lev3_cat["code"]
lev3_intance.name=lev3_cat["name"]
lev3_intance.category_type=3
lev3_intance.parent_category=lev2_intance
lev3_intance.save()
数据导入成功

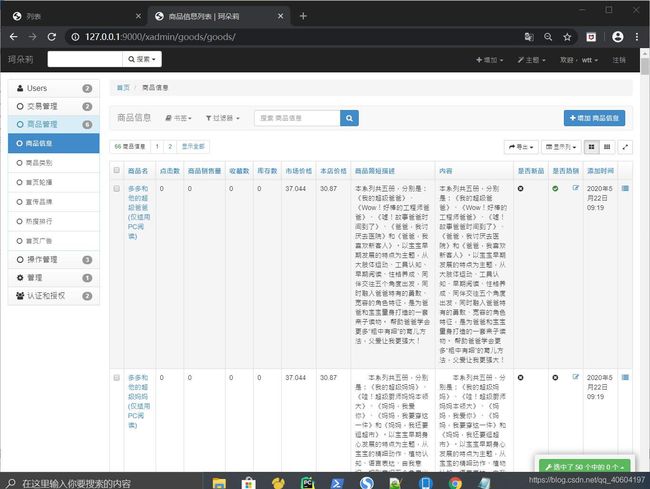
从新设置导航

从新设置轮播图

打开浏览器
修改成功
