【MYSQL】Linux环境下数据库的详细操作(DDL、DML、DQL、DCL语言)
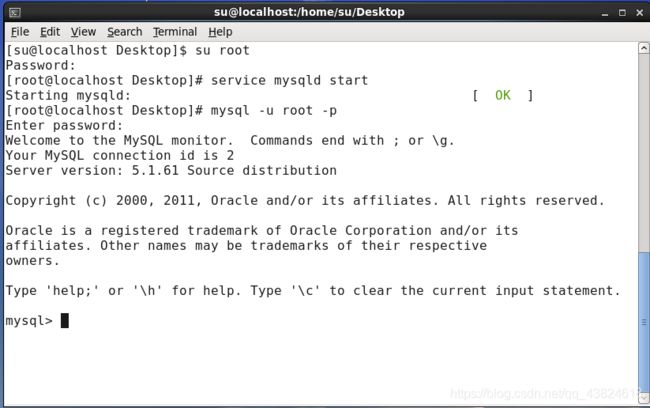
1.当我们已经在Linux下安装好了MySQL以后,第一步先切换到root用户,使用命令su root后输入密码;
2.开启服务器端,执行命令service mysqld start;
3.客户端连接服务器命令,执行命令mysql -u root -p;
三步操作如下图:
SQL语言
结构化查询语言(Structured Query Language)简称SQL,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
结构化查询语言包含6个部分:
1、数据查询语言(DQL:Data Query Language):其语句,也称为“数据检索语句”,用以从表中获得数据,确定数据怎样在应用程序给出。保留字SELECT是DQL(也是所有SQL)用得最多的动词,其他DQL常用的保留字有WHERE,ORDER BY,GROUP BY和HAVING。这些DQL保留字常与其它类型的SQL语句一起使用。
2、数据操作语言(DML:Data Manipulation Language):其语句包括动词INSERT、UPDATE和DELETE。它们分别用于添加、修改和删除。
3、事务控制语言(TCL):它的语句能确保被DML语句影响的表的所有行及时得以更新。包括COMMIT(提交)命令、SAVEPOINT(保存点)命令、ROLLBACK(回滚)命令。
4、数据控制语言(DCL):它的语句通过GRANT或REVOKE实现权限控制,确定单个用户和用户组对数据库对象的访问。某些RDBMS可用GRANT或REVOKE控制对表单个列的访问。
5、数据定义语言(DDL):其语句包括动词CREATE,ALTER和DROP。在数据库中创建新表或修改、删除表(CREAT TABLE 或 DROP TABLE);为表加入索引等。
6、指针控制语言(CCL):它的语句,像DECLARE CURSOR,FETCH INTO和UPDATE WHERE CURRENT用于对一个或多个表单独行的操作。
DDL:数据定义语言
1.对库结构的操作
(1)添加一个库:
①create database 库名;创建一个数据库;
②create database if not exists 库名;存在则创建,否则不创建;
(2)删除一个库:
①drop database 库名;删除一个数据库;
②drop database if exists 库名;存在则删除,否则不删除;
(3)查看一个库:
①show databases;查看整个库下所有的数据库;
②show create database 库名;查看一个库的创建信息;
③show tables;查看该库层面下的所有表;
(4)使用一个库:
①use 库名;选定一个库使用;
2.对表结构的操作
(1) 创建一个表:
1.create table 表名
(
字段名称 字段类型 字段约束 [注释],
字段名称 字段类型 字段约束 [注释],
…
);
例如:创建一个学生表
create table Stu
(
sid varchar(10) primary key COMMENT "学生学号",
name varchar(20) not null COMMENT "学生姓名",
sex enum("man","woman") COMMENT "学生性别",
age int default 18 COMMENT "学生年龄"
);
(2) 删除一个表:
1.drop table 表名;删除一个表
(3)修改一个表(演示对上表Stu的操作)
1.修改字段类型 modify
alter table Stu modify sid varchar(20);
2.修改字段名称 change
alter table Stu change sid id varchar(20);
alter table Stu change id id varchar(15);
3.添加一个字段 add after first
alter table Stu add score float default 0;
alter table Stu add score1 float default 0 after id;
alter table Stu add score2 float default 0 first;
4.删除字段 drop
alter table Stu drop score;
5.修改表名 rename
alter table Stu rename stu;
(4)查看一个表
1.查看当前库下有什么表
show tables;
2.查看表的创建信息
show create table 表名;
3.查看字段
desc 表名
DML:数据操作语言
1.添加数据(对上表Stu的操作)
insert into stu values("001",'zhangsan','man',20);
insert into stu(id,name,sex,age) values("001",'zhangsan','man',20);
insert into stu values("002","lisi","woman");
insert into stu(id,name,sex) values("002","lisi","woman");
小批量
insert into stu values("003","wangwu","man",22),
("004","zhaoliu","man",21),
("005","kaixin","woman",18),
("006","gaoxin","man",23);
2.删除数据
delete from stu; 1 所有数据都满足
delete from stu where id = "006"; 2where 过滤条件
3.修改数据 update
update stu set age = 19 where id = "002";
update stu set sex = "man";//所有满足
DQL:数据查询语言
1.查询数据 select
普通查询
select * from stu;//* 通匹 1 不建议
select id, name, sex, age from stu;//2
select * from stu where id = "001";
2.去重查询 distinct
select distinct age from table_name;
3.排序 order by 升序 asc 降序 desc
select distinct age from stu order by age;
4.分组查询 group by
select id,Sum(score) from result group by id;
表(result):
create table result
(
id varchar(15) comment "学生编号",
pid varchar(15) comment "课程编号",
score float comment "成绩"
);
insert into result values("001","p01",78),
("001","p02",56),
("002","p01",34),
("002","p02",89),
("003","p01",78),
("003","p02",57);
5.等值查询
select stu.id,score from stu,result where stu.id = result.id and age < 20 and score < 60;
6.连接查询
1.外连接查询
(1).左外连接查询
select a.id,score
from
(select id,age from stu where age < 20) a
left join
(select id, score from result where score < 60) b
on a.id = b.id
where b.score is not null;
(2).右外连接查询
select a.id,score
from
(select id,age from stu where age < 20) a
right join
(select id,score from result where score < 60) b
on a.id = b.id
where a.id is not null;
(3).全外连接查询
select a.id,score
from
(select id,age from stu where age < 20) a
full join
(select id,score from result where score < 60) b
on a.id = b.id
where a.id is not null;
2.内连接查询 只筛选匹配项
select a.id,score
from
(select id,age from stu where age < 20) a
inner join
(select id,score from result where score < 60) b
on a.id = b.id;
7.聚合查询
1.union(去重查询)
2.union all(不去重查询)
select * from 表1名 union select * from 表2名;
select * from 表1名 union all select * from 表2名;
DCL:数据控制语言
1.授权权限grant
grant select on CY1212.* to "cy1212"; 授予CY1212对cy1212的查询权限;
select 授予查询权限
updata 授予修改权限
insert 授予插入权限
delete 授予删除权限
create 授予创建表权限
drop 授予删除表权限
all 授予所有权限 grant all on *.* to "u1"with grant option;
谁赋予的权限只能由谁回收;
2.回收权限revoke
revoke select on CY1212.* from “cy1212";回收CY1212对cy1212的查询权限;
select 回收予查询权限
updata 回收修改权限
insert 回收插入权限
delete 回收删除权限
create 回收创建表权限
drop 回收删除表权限
all 回收所有权限
补充知识
一、字段约束几个概念:
主键:非空 ,唯一。主键是能确定一条记录的唯一标识,关系型数据库中的一条记录中有若干个属性,若其中某一个属性组(注意是组)能唯一标识一条记录,该属性组就可以成为一个主键;
学生一一表(学号,姓名,性别,班级) ,其中每个学生的学号是唯一的,学号就是一个主键 。
外键: 外键用于与另一张表的关联。是能确定另一张表记录的字段,用于保持数据的一致性。
成绩表中的学号不是成绩表的主键,但它和学生表中的学号相对应,并且学生表中的学号是学生表的主键,则称成绩表中的学号是学生表的外键 。
唯一键: 不能重复。
非空: 不能为空。
默认:若没有给数据用默认值代替。
二、varchar与char的区别:
1.首先明确的是,char的长度是不可变的,而varchar的长度是可变的。
2.定义一个char[10]和varchar[10],如果存进去的是‘abcd’,那么char所占的长度依然为10,除了字符‘abcd’外,后面跟六个空格,而varchar就立马把长度变为4了,取数据的时候,char类型的要用trim()去掉多余的空格,而varchar是不需要的。
3.char的存取数度还是要比varchar要快得多,因为其长度固定,方便程序的存储与查找;但是char也为此付出的是空间的代价,因为其长度固定,所以难免会有多余的空格占位符占据空间,可谓是以空间换取时间效率,而varchar是以空间效率为首位的。
4.char的存储方式是,对英文字符(ASCII)占用1个字节,对一个汉字占用两个字节;而varchar的存储方式是,对每个英文字符占用2个字节,汉字也占用2个字节,两者的存储数据都非unicode的字符数据。