Spring源码学习--获取Document
Spring在容器的基本实现流程中会涉及到关于xml文件操作,在这里跟踪一下源码,看一下spring在解析xml文件之前,对xml的Document是怎么获取的。
一、DefaultDocumentLoader
在Spring中XmlBeanFactoryReader类对于文档的读取并没有亲自去做加载,而是委托给DocumentLoader去执行,其中DocumentLoader只是个接口:
package org.springframework.beans.factory.xml;
import org.w3c.dom.Document;
import org.xml.sax.EntityResolver;
import org.xml.sax.ErrorHandler;
import org.xml.sax.InputSource;
public interface DocumentLoader {
Document loadDocument(
InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware)
throws Exception;
}
真正去做文档读取的实现类是DefaultDocumentLoader。
package org.springframework.beans.factory.xml;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.springframework.util.xml.XmlValidationModeDetector;
import org.w3c.dom.Document;
import org.xml.sax.EntityResolver;
import org.xml.sax.ErrorHandler;
import org.xml.sax.InputSource;
public class DefaultDocumentLoader implements DocumentLoader {
/**
* JAXP attribute used to configure the schema language for validation.
*/
private static final String SCHEMA_LANGUAGE_ATTRIBUTE = "http://java.sun.com/xml/jaxp/properties/schemaLanguage";
/**
* JAXP attribute value indicating the XSD schema language.
*/
private static final String XSD_SCHEMA_LANGUAGE = "http://www.w3.org/2001/XMLSchema";
private static final Log logger = LogFactory.getLog(DefaultDocumentLoader.class);
/**
* Load the {@link Document} at the supplied {@link InputSource} using the standard JAXP-configured
* XML parser.
*/
@Override
public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception {
DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware);
if (logger.isDebugEnabled()) {
logger.debug("Using JAXP provider [" + factory.getClass().getName() + "]");
}
DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler);
return builder.parse(inputSource);
}
protected DocumentBuilderFactory createDocumentBuilderFactory(int validationMode, boolean namespaceAware)
throws ParserConfigurationException {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
factory.setNamespaceAware(namespaceAware);
if (validationMode != XmlValidationModeDetector.VALIDATION_NONE) {
factory.setValidating(true);
if (validationMode == XmlValidationModeDetector.VALIDATION_XSD) {
// Enforce namespace aware for XSD...
factory.setNamespaceAware(true);
try {
factory.setAttribute(SCHEMA_LANGUAGE_ATTRIBUTE, XSD_SCHEMA_LANGUAGE);
}
catch (IllegalArgumentException ex) {
ParserConfigurationException pcex = new ParserConfigurationException(
"Unable to validate using XSD: Your JAXP provider [" + factory +
"] does not support XML Schema. Are you running on Java 1.4 with Apache Crimson? " +
"Upgrade to Apache Xerces (or Java 1.5) for full XSD support.");
pcex.initCause(ex);
throw pcex;
}
}
}
return factory;
}
protected DocumentBuilder createDocumentBuilder(
DocumentBuilderFactory factory, EntityResolver entityResolver, ErrorHandler errorHandler)
throws ParserConfigurationException {
DocumentBuilder docBuilder = factory.newDocumentBuilder();
if (entityResolver != null) {
docBuilder.setEntityResolver(entityResolver);
}
if (errorHandler != null) {
docBuilder.setErrorHandler(errorHandler);
}
return docBuilder;
}
}
在DefaultDocumentLoader中loadDocument方法同样并没有做别的操作,只是通过调用别的方法来控制文档读取的实现。写过解析XML文档内容的开发都知道通过SAX解析XML文档的实现流程都是一样的,Spring在这里也没有做特殊的处理,loadDocument流程如下:
- 创建DocumentBuilderFactory实例
- 通过DocumentBuilderFactory实例创建DocumentBuilder实例
- 解析InputSource
- 返回Document实例
在实际开发中基本不会涉及到DocumentBuilderFactory以及DocumentBuilder,通常的业务代码一般如下所示:
/**
* 依据文件路径和文件名称获取文件的Document流
*
* @param compressionPath
* 文件绝对路径(未解压文件)
* @param filename
* 文件名称
* @return 文件Document实例
*/
private Document getDocumentFromXML(String compressionPath, String filename) {
FileInputStream file = null;
String filepath = null;
try {
filepath = ZipUtil.getUnzipPath(compressionPath) + File.separator + DataManagerConstant.MODEL_META_INF + File.separator + filename;
file = new FileInputStream(filepath);
} catch (Exception e) {
logger.info(HikLog.toLog(HikLog.message("wrong file path is:{} load {} file has a exception:{}")), filepath, filename, e);
throw new ProgramException(DataManagerErrorCode.PACKAGE_COMPRESSES_PATH_ERROR, "xml is not find and wrong file path is:" + filepath);
}
SAXReader saxReader = new SAXReader();
Document document = null;
try {
document = saxReader.read(file);
} catch (Exception e) {
logger.info(HikLog.toLog(HikLog.message("SAXReader read FileInputStream has a exception:{}")), e);
throw new ProgramException(DataManagerErrorCode.FILE_CONTENT_ERROR, "xml format is error", e);
}
return document;
}感兴趣的读者可以跟一下SAXReader 中read()方法的实现。
二、EntityResolver
在上面的DefaultDocumentLoader类中loadDocument()方法
Document loadDocument(
InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware)
throws Exception;EntityResolver 接口API说明:https://blog.fondme.cn/apidoc/jdk-1.8-google/ ,接口中只有一个方法如下所示:
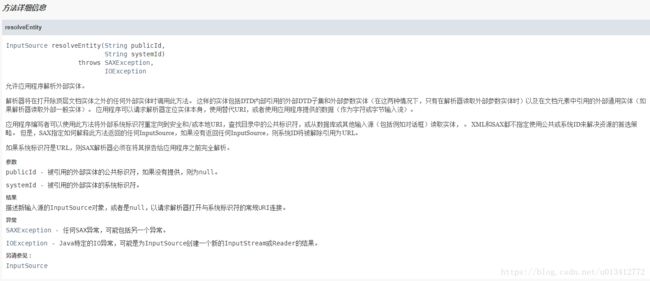
EntityResolver接口API机器翻译如下描述:EntityResolver是解决实体的基本界面,如果SAX应用程序需要为外部实体实现定制处理,则必须实现该接口,并且使用setEntityResolver方法项SAX驱动程序注册一个实例。然后,XML读取器将允许应用程序在包含他们之前拦截任何外部实体(包括外部DTD子集和外部参数实体(如果有的话))。需要SAX应用程序不需要实现此接口,但是对于从数据库或其他专门的输入源构建XML文档的应用程序,或者使用URL以外的URI类型的应用程序,这将非常有用。
一下解析器将为应用程序提供具有系统标识符 “http://www.myhost.com/today” 的实体的特殊字符流:
import org.xml.sax.EntityResolver;
import org.xml.sax.InputSource;
public class MyResolver implements EntityResolver {
public InputSource resolveEntity (String publicId, String systemId)
{
if (systemId.equals("http://www.myhost.com/today")) {
// return a special input source
MyReader reader = new MyReader();
return new InputSource(reader);
} else {
// use the default behaviour
return null;
}
}
} 该应用程序还可以使用此接口将系统标识符重定向到本地URI来查找目录中的替换(可能通过使用公共标识符)。
EntityResolver作用(官网给出的解释是):SAX应用程序需要实现自定义处理外部实体,则必须实现此接口并使用setEntityResolver方法项SAX驱动器注册一个实例。也就是说,对于解析一个XML,SAX首先读取该XML文件上的声明,根据声明去寻找响应的DTD定义,以便对文档进行一个验证。默认的寻找规则,即通过网络(首先上就是声明的DTD的URL地址)来下载响应的DTD声明,并进行认证。下载是一个比较慢的过程,并且当网络中断或不可用时,还会报错,就是因为相应的DTD声明被找到的原因。EntityResolver 的作用是项目本身就可以提供一个如何寻找DTD声明的方法,即由程序来实现DTD声明的过程,比如我们将DTD文件放在项目中某处,在实现时直接将此文档读取并返回给SAX即可。这样就避免了通过网络来寻找相应的声明。
其中setEntityResolver()方法如下所示:
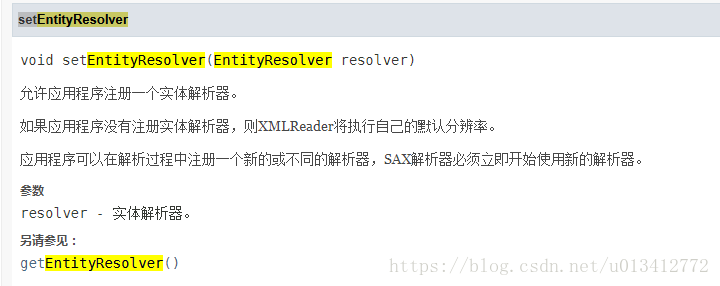
接下来来说明一下EntityResolver接口中resolveEntity方法:有两个参数publicId,systemId,返回inputSource对象。如下特定配置文件:
(1)、当解析验证模式为XSD的配置文件,代码如下:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p"
xmlns:aop="http://www.springframework.org/schema/aop" xmlns:mvc="http://www.springframework.org/schema/mvc"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/mvc
http://www.springframework.org/schema/mvc/spring-mvc.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-4.2.xsd
http://www.springframework.org/schema/mvc
http://www.springframework.org/schema/mvc/spring-mvc-4.0.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">读取到下面两个参数:
publicId:null
systemId:http://www.springframework.org/schema/aop/spring-aop-4.2.xsd
(2)、当解析模式为DTD的配置文件,代码如下:
"1.0" encoding="UTF-8"?>
"-//Spring//DTD BEAN 2.0//EN" "http://www.Springframework.org.dtd/Spring-beans-2.0dtd">
... ...
读取到下面两个参数:
publicId:-//Spring//DTD BEAN 2.0//EN
systemId:http://www.Springframework.org.dtd/Spring-beans-2.0dtd
在之前已经提到,验证文件默认的加载方式是通过URL进行网络下载获取,这样做会有延迟和网络中断等因素,一般的做法都是将验证文件防止在自己的工程里,那么怎么做才能将这个URL转换为自己工程里对应的地址文件呢?我们以加载DTD文件为例来看看Spring中是如果实现。根据之前Spring通过getEntityResolver()方法对EntityResolver的获取,在Spring中使用DelegatingEntityResolver类为EntityResolver的实现类,resolverEntity实现方法如下:
@Override
public InputSource resolveEntity(String publicId, String systemId)
throws SAXException, IOException {
if (systemId != null) {
// 验证模式为:dtd
if (systemId.endsWith(DTD_SUFFIX)) {
return this.dtdResolver.resolveEntity(publicId, systemId);
}
// 验证模式为:xsd
else if (systemId.endsWith(XSD_SUFFIX)) {
// 调用META-INF/Spring.schemas解析
InputSource inputSource = this.schemaResolver.resolveEntity(publicId, systemId);
return inputSource;
}
}
return null;
}从上面的代码可以看到,针对不同的验证模式,Spring使用了不同的解析器解析。这里简单描述一下原理:比如加载DTD类型的BeansDtdResolver的resolverEntity是直接截取systemId最后的xml.dtd然后去当前路径下寻找,而加载XSD类型的PluggableSchemaResolver类的resolverEntity是默认到META-INF/Spring.schemas文件中找到systemid所对应的XSD文件加载。
BeansDtdResolver中resolveEntity实现如下:
@Override
public InputSource resolveEntity(String publicId, String systemId) throws IOException {
if (logger.isTraceEnabled()) {
logger.trace("Trying to resolve XML entity with public ID [" + publicId +
"] and system ID [" + systemId + "]");
}
if (systemId != null && systemId.endsWith(DTD_EXTENSION)) {
int lastPathSeparator = systemId.lastIndexOf("/");
int dtdNameStart = systemId.indexOf(DTD_NAME, lastPathSeparator);
if (dtdNameStart != -1) {
String dtdFile = DTD_FILENAME + DTD_EXTENSION;
if (logger.isTraceEnabled()) {
logger.trace("Trying to locate [" + dtdFile + "] in Spring jar on classpath");
}
try {
Resource resource = new ClassPathResource(dtdFile, getClass());
InputSource source = new InputSource(resource.getInputStream());
source.setPublicId(publicId);
source.setSystemId(systemId);
if (logger.isDebugEnabled()) {
logger.debug("Found beans DTD [" + systemId + "] in classpath: " + dtdFile);
}
return source;
}
catch (IOException ex) {
if (logger.isDebugEnabled()) {
logger.debug("Could not resolve beans DTD [" + systemId + "]: not found in classpath", ex);
}
}
}
}
// Use the default behavior -> download from website or wherever.
return null;
}
PluggableSchemaResolver中resolveEntity实现如下:
@Override
public InputSource resolveEntity(String publicId, String systemId) throws IOException {
if (logger.isTraceEnabled()) {
logger.trace("Trying to resolve XML entity with public id [" + publicId +
"] and system id [" + systemId + "]");
}
if (systemId != null) {
String resourceLocation = getSchemaMappings().get(systemId);
if (resourceLocation != null) {
Resource resource = new ClassPathResource(resourceLocation, this.classLoader);
try {
InputSource source = new InputSource(resource.getInputStream());
source.setPublicId(publicId);
source.setSystemId(systemId);
if (logger.isDebugEnabled()) {
logger.debug("Found XML schema [" + systemId + "] in classpath: " + resourceLocation);
}
return source;
}
catch (FileNotFoundException ex) {
if (logger.isDebugEnabled()) {
logger.debug("Couldn't find XML schema [" + systemId + "]: " + resource, ex);
}
}
}
}
return null;
}