深度学习-目标检测
目标检测模型总结
内容来自 Object detection: an overview in the age of Deep Learning 以及 cs231n 。

第一张图为语义分割问题,只需要对每个像素点进行分类;第二张图为单目标检测问题,需要框出物体的位置并对其分类;第三张图为多目标检测问题,需要框出所有的物体,并对所有物体单独分类;第四张图是实例分割问题,需要标记出所有物体及其类别。这篇文章介绍后三种问题相关的模型。
单目标检测
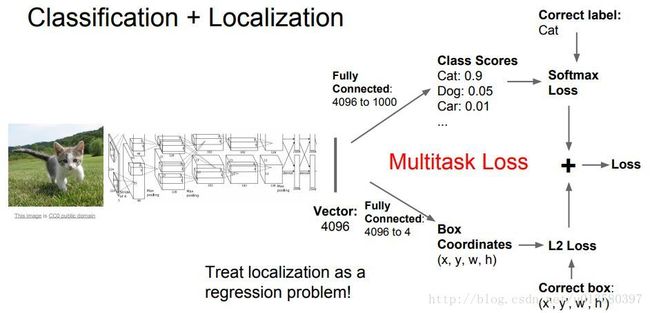
可以当作两个子问题进行训练,即分类 + 物体定位。将物体定位看做回归问题,预测方框的四个值,(x, y, w, h) 或 (x, y, x’, y’) 。整体流程是:使用分类卷积网对图片分类,并利用全连接后的高维特征预测方框的四个值。将回归以及分类的损失函数相加,得到总的损失函数,训练整个网络。
卷积网回归预测的其他应用:人体姿势检测。定义多个点 (x, y) 坐标,分别对应人体的不同关节。

多目标检测
相对于单目标检测复杂得多,因为目标数目不确定。
- 滑窗:确定一个窗口大小(即 CNN 输入),在原图上多次移动,得到多个选区,利用 CNN 对每个选区分类。选区很多,相对应的 CNN 的计算开销也很大。
- 建议选区 (Region Proposals) :能够快速的提取出可能的选区。常用的是 Selective Search 解读。
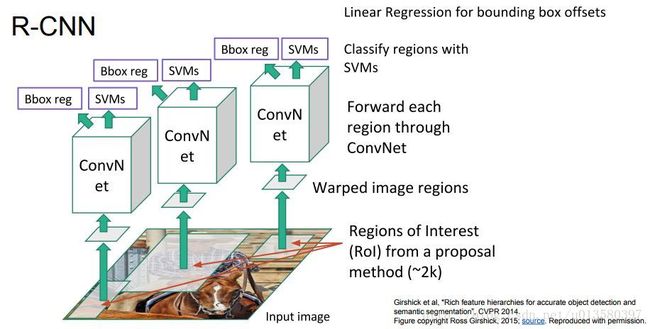
R-CNN
Regions with CNN features
大概分为以下几步:
- 利用 Region Proposals 提取出选区 ( RoI, Regions of Interest ) ,并将该选区伸缩至卷积网输入的尺寸
- 将每个伸缩后的选区输入卷积网,提取出特征
- 将提取的特征输入 SVM 模型进行分类,利用线性回归来逼近选区
缺点:
- 分别需要 fine-tune 网络,训练 SVM 以及 LR
- 训练时间长,并且需要存储中间结果
- 预测时间长
Fast R-CNN
步骤:
- 先将整张图片输入卷积网,得到特征映射 ( conv5 的输出)
- 还是利用 Region proposals 得到选区
- 对于每个选区,利用 RoI Pooling 作用于上述特征,并输入到后续的分类和回归网络
优点:运行速度更快,实现端到端的训练。
Fast RCNN方法解决了RCNN方法三个问题:
问题一:测试时速度慢
RCNN一张图像内候选框之间大量重叠,提取特征操作冗余。
本文将整张图像归一化后直接送入深度网络。在邻接时,才加入候选框信息,在末尾的少数几层处理每个候选框。问题二:训练时速度慢
原因同上。
在训练时,本文先将一张图像送入网络,紧接着送入从这幅图像上提取出的候选区域。这些候选区域的前几层特征不需要再重复计算。问题三:训练所需空间大
RCNN中独立的分类器和回归器需要大量特征作为训练样本。
本文把类别判断和位置精调统一用深度网络实现,不再需要额外存储。Link
缺点:仍然依赖 Region proposals ,预测麻烦。

Faster R-CNN
让 CNN 来提取选区,插入了 Region Proposal Network (RPN) ,用于从特征中预测选区。
总共有四个损失:
- RPN 分类是否有目标 根据 IOU 判断
- RPN 框坐标
- 最后的目标分类损失
- 最后的框坐标

YOLO
You Only Look Once ,知乎 知乎2
YOLO核心思想:从R-CNN到Fast R-CNN一直采用的思路是proposal+分类 (proposal 提供位置信息, 分类提供类别信息)精度已经很高,但是速度还不行。 YOLO提供了另一种更为直接的思路: 直接在输出层回归bounding box的位置和bounding box所属的类别(整张图作为网络的输入,把 Object Detection 的问题转化成一个 Regression 问题)。
YOLO首先将图像分为S×S的格子(grid cell)。如果一个目标的中心落入格子,该格子就负责检测该目标。每一个格子(grid cell)预测bounding boxes(B)和该boxes的置信值(confidence score)。置信值代表box包含一个目标的置信度。然后,我们定义置信值为Pr(Object) * IOU 。如果没有目标,置信值为零。另外,我们希望预测的置信值和ground truth的intersection over union (IOU)相同。

SSD
Single Shot MultiBox Detector ,知乎
SSD paper详解,CSDN
综合了 Faster R-CNN 的 anchor box 和 YOLO 的单个神经网络检测思路。SSD 关键点有两个:模型结构和训练方法。模型结构包括:多尺度特征图检测网络结构和anchor boxes生成;训练方法包括:ground truth预处理和损失函数。
SSD和Yolo一样都是采用一个CNN网络来进行检测,但是却采用了多尺度的特征图,其基本架构如图3所示。下面将SSD核心设计理念总结为以下三点:
(1)采用多尺度特征图用于检测
所谓多尺度采用大小不同的特征图,CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2的卷积或者pool来降低特征图大小,一个比较大的特征图和一个比较小的特征图,它们都用来做检测。这样做的好处是比较大的特征图来用来检测相对较小的目标,而小的特征图负责检测大目标.
(2)采用卷积进行检测
与Yolo最后采用全连接层不同,SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为 m∗n∗p m ∗ n ∗ p 的特征图,只需要采用 3∗3∗p 3 ∗ 3 ∗ p 这样比较小的卷积核得到检测值。
(3)设置先验框
在Yolo中,每个单元预测多个边界框,但是其都是相对这个单元本身(正方块),但是真实目标的形状是多变的,Yolo需要在训练过程中自适应目标的形状。而SSD借鉴了Faster R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的先验框,预测的边界框(bounding boxes)是以这些先验框为基准的,在一定程度上减少训练难度。一般情况下,每个单元会设置多个先验框,其尺度和长宽比存在差异,
Link

实例分割
Mask R-CNN
扩展原有的 Faster R-CNN ,添加一个分支,在目标检测的基础上对目标进行像素级的预测。还可以很方便的应用到其他领域,如人体姿势检测等。
从上面可以知道,mask rcnn主要的贡献在于如下:
- 强化的基础网络
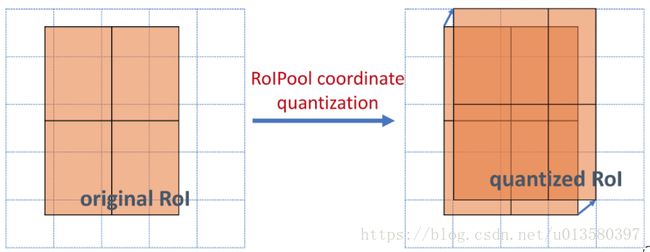
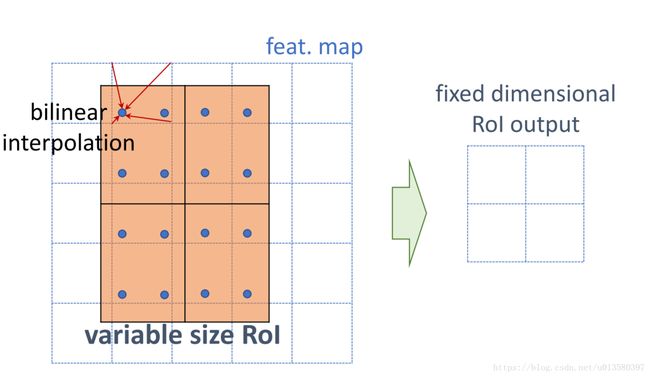
通过 ResNeXt-101+FPN 用作特征提取网络,达到 state-of-the-art 的效果。 - ROIAlign 解决Misalignment 的问题
- Loss Function
ROIPool首先将浮点数值的ROI量化成离散颗粒的特征图,然后将量化的ROI分成几个空间的小块(Spatial Bins),最后对每个小块进行Max Pooling操作生成最后的结果。这些量化引入了ROI与提取到的特征的不对准问题。作者提出ROIAlign层来解决这个问题,并且将提取到的特征与输入对齐。作者使用双线性插值(Bilinear Interpolation)在每个ROI块中4个采样位置上计算输入特征的精确值,并将结果聚合(使用Max或者Average)。
作者对于每个采样的ROI定义一个多任务损失函数L=Lcls+Lbox+Lmask,前两项不过多介绍。掩模分支对于每个ROI会有一个Km2维度的输出,它编码了K个分辨率为m×m的二值掩模,分别对应着KK个类别。因此作者利用了A Per-pixel Sigmoid,并且定义为平均二值交叉熵损失(The Average Binary Cross-entropy Loss)。对于一个属于第K个类别的ROI,仅仅考虑第K个Mask(其他的掩模输入不会贡献到损失函数中)。这样的定义会允许对每个类别都会生成掩模,并且不会存在类间竞争。
