pytorh实现inception多分支跟辅助分类、resnet里shortcut、densenet、 DepthWise深度可分离卷积、ShuffleNet的channel shuffle
参考博客:变形卷积核、可分离卷积?卷积神经网络中十大拍案叫绝的操作。
pytorch微调网络Inception3
CNN网络架构演进:从LeNet到DenseNet
1、inception的多分支卷积:
最初的Inception的卷积如下:
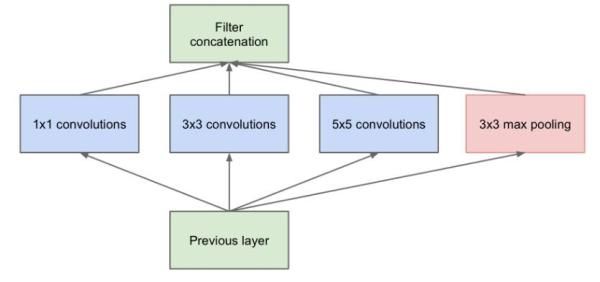
其是对输入进行多个卷积处理,往往比单一卷积核处理要好,然后再把处理后特征进行cat()操作。由于其计算量大,参数多。
后来进行改进了,添加了1x1卷积核来减少计算跟参数,其新结构为:

这个就是Inception3最新版本使用的网络结构bottleneck,其还有三四个其它的bottleneck。其中两个个使用pytorch实现如下:
class InceptionA(nn.Module):
def __init__(self, in_channels, pool_features):
super(InceptionA, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch5x5_1 = BasicConv2d(in_channels, 48, kernel_size=1)
self.branch5x5_2 = BasicConv2d(48, 64, kernel_size=5, padding=2)
self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = BasicConv2d(96, 96, kernel_size=3, padding=1)
self.branch_pool = BasicConv2d(in_channels, pool_features, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)使用非矩形卷积核实现卷积,如下:
class InceptionC(nn.Module):
def __init__(self, in_channels, channels_7x7):
super(InceptionC, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 192, kernel_size=1)
c7 = channels_7x7
self.branch7x7_1 = BasicConv2d(in_channels, c7, kernel_size=1)
self.branch7x7_2 = BasicConv2d(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7_3 = BasicConv2d(c7, 192, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_1 = BasicConv2d(in_channels, c7, kernel_size=1)
self.branch7x7dbl_2 = BasicConv2d(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_3 = BasicConv2d(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7dbl_4 = BasicConv2d(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_5 = BasicConv2d(c7, 192, kernel_size=(1, 7), padding=(0, 3))
self.branch_pool = BasicConv2d(in_channels, 192, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch7x7 = self.branch7x7_1(x)
branch7x7 = self.branch7x7_2(branch7x7)
branch7x7 = self.branch7x7_3(branch7x7)
branch7x7dbl = self.branch7x7dbl_1(x)
branch7x7dbl = self.branch7x7dbl_2(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_3(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_4(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_5(branch7x7dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch7x7, branch7x7dbl, branch_pool]
return torch.cat(outputs, 1)其中Inception3里有个辅助输出跟最终输出,其辅助输出的网络定义如下:
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.conv0 = BasicConv2d(in_channels, 128, kernel_size=1)
self.conv1 = BasicConv2d(128, 768, kernel_size=5)
self.conv1.stddev = 0.01
self.fc = nn.Linear(768, num_classes)
self.fc.stddev = 0.001
def forward(self, x):
# 17 x 17 x 768
x = F.avg_pool2d(x, kernel_size=5, stride=3)
# 5 x 5 x 768
x = self.conv0(x)
# 5 x 5 x 128
x = self.conv1(x)
# 1 x 1 x 768
x = x.view(x.size(0), -1)
# 768
x = self.fc(x)
# 1000
return x其中整个网络的前向部分输出定义为:
x = self.Mixed_6e(x)
# 17 x 17 x 768
if self.training and self.aux_logits:
aux = self.AuxLogits(x)
# 17 x 17 x 768
x = self.Mixed_7a(x)
# 8 x 8 x 1280
x = self.Mixed_7b(x)
# 8 x 8 x 2048
x = self.Mixed_7c(x)
# 8 x 8 x 2048
x = F.avg_pool2d(x, kernel_size=8)
# 1 x 1 x 2048
x = F.dropout(x, training=self.training)
# 1 x 1 x 2048
x = x.view(x.size(0), -1)
# 2048
x = self.fc(x)
# 1000 (num_classes)
#其中self.training是nn.module里的成员变量,当训练网络使用model.train()时,
#会对self.training赋值为True,当为model.eval()会给他赋值为False。
if self.training and self.aux_logits:
return x, aux
return x如果微调网络需要用到辅助分类的话可以参考下面代码:
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25, is_inception=False):
since = time.time()
val_acc_history = []
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
# Get model outputs and calculate loss
# Special case for inception because in training it has an auxiliary output. In train
# mode we calculate the loss by summing the final output and the auxiliary output
# but in testing we only consider the final output.
if is_inception and phase == 'train':
# From https://discuss.pytorch.org/t/how-to-optimize-inception-model-with-auxiliary-classifiers/7958
outputs, aux_outputs = model(inputs)
loss1 = criterion(outputs, labels)
loss2 = criterion(aux_outputs, labels)
#辅助输出的损失比重降低点
loss = loss1 + 0.4*loss2
else:
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
if phase == 'val':
val_acc_history.append(epoch_acc)
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model, val_acc_history注意:这里的多分支跟后面的DepthWise是不同的,其中DepthWise的每个分支处理的只是输入的数据的一个通道,并且其卷积核也都是一样大小的。
2、resnet里的shutcut:
其中一个bottleneck的实现代码为:
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
#这里根据主支路是否有进行下采样操作来决定分支的操作,如果有则会对分支进行一
次下采样操作,不过其实现手法是使用stride=2卷积加BN的操作碗完成下采样。
residual = self.downsample(x)
#直接进行add操作,这个element-wise会消耗大量的Mac(内存访问操作消耗)增加计算量
out += residual
out = self.relu(out)
return out注意:其中depth-wise的网络是在residual基础上发展起来的,其不同点是:DW主支使用的是分组卷积,而residua是直接一条路下来的卷积操作。相同点:主支路跟分支都是使用element-wise的add操作。
3、densenet:
密集连接:缓解梯度消失问题,加强特征传播,鼓励特征复用,极大的减少了参数量,不过要占很多内存
其中最主要的block为:
class _DenseLayer(nn.Sequential):
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(_DenseLayer, self).__init__()
self.add_module('norm1', nn.BatchNorm2d(num_input_features)),
self.add_module('relu1', nn.ReLU(inplace=True)),
self.add_module('conv1', nn.Conv2d(num_input_features, bn_size *
growth_rate, kernel_size=1, stride=1, bias=False)),
self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate)),
self.add_module('relu2', nn.ReLU(inplace=True)),
self.add_module('conv2', nn.Conv2d(bn_size * growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False)),
self.drop_rate = drop_rate
def forward(self, x):
new_features = super(_DenseLayer, self).forward(x)
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return torch.cat([x, new_features], 1)其中在forward()里再使用forward()的作用,这里是执行_DenseLayer层里的通过add_module()添加的层:
new_features = super(_DenseLayer, self).forward(x)百思不得其解。
最后在官方论坛上得到结果,含义是将调用所有add_module方法添加到sequential的模块的forward函数。

3、ShuffleNet的channel shuffle
其中其是结合Group conv 跟depthwise+Pointwise、shuffle的功能。
其中其每一个stage的开始都使用一个下采样,其为了实现下采样进行通道增加的规则,使用了类型Inception的思想,进行多分支卷积,即多个支路对同一输入进行处理,代码如下:
class DownsampleUnit(nn.Module):
def __init__(self, inplanes, c_tag=0.5, activation=nn.ReLU, groups=2):
super(DownsampleUnit, self).__init__()
self.conv1r = nn.Conv2d(inplanes, inplanes, kernel_size=1, bias=False)
self.bn1r = nn.BatchNorm2d(inplanes)
self.conv2r = nn.Conv2d(inplanes, inplanes, kernel_size=3, stride=2, padding=1, bias=False, groups=inplanes)
self.bn2r = nn.BatchNorm2d(inplanes)
self.conv3r = nn.Conv2d(inplanes, inplanes, kernel_size=1, bias=False)
self.bn3r = nn.BatchNorm2d(inplanes)
self.conv1l = nn.Conv2d(inplanes, inplanes, kernel_size=3, stride=2, padding=1, bias=False, groups=inplanes)
self.bn1l = nn.BatchNorm2d(inplanes)
self.conv2l = nn.Conv2d(inplanes, inplanes, kernel_size=1, bias=False)
self.bn2l = nn.BatchNorm2d(inplanes)
self.activation = activation(inplace=True)
self.groups = groups
self.inplanes = inplanes
def forward(self, x):
out_r = self.conv1r(x)
out_r = self.bn1r(out_r)
out_r = self.activation(out_r)
out_r = self.conv2r(out_r)
out_r = self.bn2r(out_r)
out_r = self.conv3r(out_r)
out_r = self.bn3r(out_r)
out_r = self.activation(out_r)
out_l = self.conv1l(x)
out_l = self.bn1l(out_l)
out_l = self.conv2l(out_l)
out_l = self.bn2l(out_l)
out_l = self.activation(out_l)
#实现下采样后通道翻倍的效果。
return channel_shuffle(torch.cat((out_r, out_l), 1), self.groups)
接着就进行多个没有下采样并带有的channel_shuffle操作的基本卷积block,其中实现shuffle的代码为:
def channel_shuffle(x, groups):
batchsize, num_channels, height, width = x.data.size()
assert (num_channels % groups == 0)
channels_per_group = num_channels // groups
# reshape 其数据顺序不会被打乱,其相当于reshape作用
x = x.view(batchsize, groups, channels_per_group, height, width)
# transpose
# - contiguous() required if transpose() is used before view().
# See https://github.com/pytorch/pytorch/issues/764
#这里当通道数很多的时候是会对C的通道数据顺序进行打乱,相当于把多个特征图进行重新排序。只针对
#特征图,而且如果输入的数据维度每次都一样,则其打乱对调的顺序都是一样的。其不是随机打乱
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batchsize, -1, height, width)
return x注意:其中shuffle是比mobilenetV2更轻量、更准确的网络。其主要做到了:尽可能少使用Group conv(只是在每个stage下采样处使用了对相同输入数据使用不同滤波核处理);在Group Conv里的分支使用depth-wise;由于Group conv最后的合并是使用cat操作,这使得在进行卷积下采样的时候不用增加输出通道,从而符合输入等于输出的通道的规则,起到最大的加速跟减小模型。
4、depthwise卷积与pointwise卷积
Depthwise(DW)卷积与Pointwise(PW)卷积,合起来被称作Depthwise Separable Convolution(参见Google的Xception),该结构和常规卷积操作类似,可用来提取特征,但相比于常规卷积操作,其参数量和运算成本较低。所以在一些轻量级网络中会碰到这种结构如MobileNet。
常规卷积操作
对于一张5×5像素、三通道彩色输入图片(shape为5×5×3)。经过3×3卷积核的卷积层(假设输出通道数为4,则卷积核shape为3×3×3×4),最终输出4个Feature Map,如果有same padding则尺寸与输入层相同(5×5),如果没有则为尺寸变为3×3。
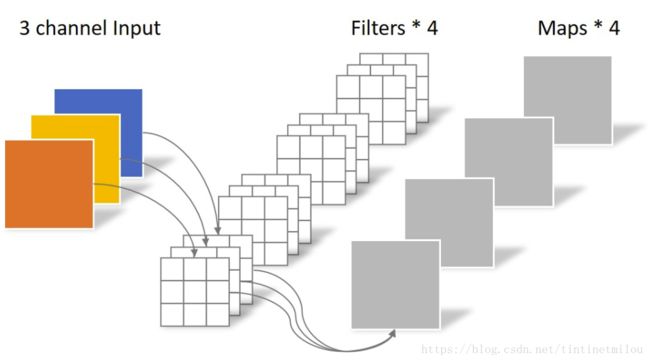
Depthwise Separable Convolution
Depthwise Separable Convolution是将一个完整的卷积运算分解为两步进行,即Depthwise Convolution与Pointwise Convolution。
Depthwise Convolution
不同于常规卷积操作,Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。上面所提到的常规卷积每个卷积核是同时操作输入图片的每个通道。
同样是对于一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,不同于上面的常规卷积,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的 图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5),如下图所示。
图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5),如下图所示。
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
Pointwise Convolution
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。如下图所示。
