【文献阅读】在VQA的答案空间中引入相似性测度(Corentin Kervadec等人,ArXiv,2020)
一、背景
文章题目:《Estimating sementic structure for the VQA answer space》
和前面的那篇文章是同一个团队:【文献阅读】GQA-OOD——测试低频样本问答的数据集和评估方法(Corentin Kervadec等人,ArXiv,2020,有代码),这篇文章的思路其实也比较好理解,就是因为一般答案环节都是用分类来做的, 无法度量相似类别,因此作者在答案空间进行了修改。
文献下载地址:https://arxiv.org/pdf/2006.05726.pdf
文章引用格式:Corentin Kervadec, Grigory Antipov, Moez Baccouche and Christian Wolf. "Estimating sementic structure for the VQA answer space". arXiv preprint, arXiv: 2006.05726, 2020.
项目地址:https://github.com/MILVLG/openvqa
二、文章摘要
Since its appearance, Visual Question Answering (VQA, i.e. answering a question posed over an image), has always been treated as a classification problem over a set of predefined answers. Despite its convenience, this classification approach poorly reflects the semantics of the problem limiting the answering to a choice between independent proposals, without taking into account the similarity between them (e.g. equally penalizing for answering “cat” or “German shepherd” instead of “dog”). We address this issue by proposing (1) two measures of proximity between VQA classes, and (2) a corresponding loss which takes into account the estimated proximity. This significantly improves the generalization of VQA models by reducing their language bias. In particular, we show that our approach is completely model-agnostic since it allows consistent improvements with three different VQA models. Finally, by combining our method with a language bias reduction approach, we report SOTA-level performance on the challenging VQAv2-CP dataset.
一般我们是将VQA视作一个分类问题,尽管这样处理比较方便,但是问题也很明显,即在受限于每个独立的答案,无法考虑答案之间的相似度,导致模型不能反映问题的语义。作者通过两种方法来解决这个问题,(1)是在VQA的累呗之间引入相似性测度,(2)loss函数考虑相似估计。这样就能够提高VQA模型的泛化性,减少语言偏见。
三、文章介绍
传统VQA就是将生成答案处理为一个分类问题,这样做的好处就是易于应用,loss函数可以直接定义。但是这么做的问题也很明显(1)破坏模型的泛化性,对于测试集,如果出现训练集没有出现的内容,那么模型就会失效,(2)每个答案之间都是独立的,而没有考虑他们之间的语义关系。这就使得模型高度依赖于语言偏见。
本文作者主要解决第二个问题,作者新建了一个semantic loss,它能计算预测答案和真实答案之间的语义距离。其模型结构如下所示:

本文的主要贡献如下:
1. We design a semantic loss for VQA, which helps the model to better structure its answer space and to learn the semantic relations between the answers. 设计了一个semantic loss
2. We propose two different methods for estimating semantic proximity between answer classes based on word embeddings and annotation statistics, respectively. 提出了两种不同的方法,分别基于单词嵌入和标注统计来估算答案之间的语义近似度
3. We demonstrate the effectiveness of our method on the VQAv2-CP [4] and VQAv2 [2] datasets with three different neural models, showing consistency of the improvement over datasets and models.该方法在两个数据集上都很有效。
4. When combined with other efforts in addressing language bias, our performance improvements add up and achieve performance on-par with the State-Of-The-Art (SOTA) on VQAv2-CP with reasonably complex mode architectures. 与其他方法相比,该方法能够比较好的解决语言偏见。
1. 相关工作:
将VQA作为分类(VQA as a classification task):VQA的方法,包括基于注意力的方法attention-based networks,基于目标的注意力object-based attention mechanisms,双线性融合模型bilinear fusion methods,基于Transformer的模型Transformer-based models都是将VQA视作分类问题来处理的。
VQA数据集的偏见(VQA as a classification task):最明显的就是VQAv1,后来VQAv2改进了很多。
VQA的泛化性(The generalization curse of VQA):早期工作,比如只看一半的图片或者问题,后期还有针对数据集改进的工作。
VQA减少语言偏见(Reducing language biases on VQA):一些工作的思路都能减少语言偏见,比如使用question-only,RUBi,HINT,SRC,DLR等。
2. 答案空间的结构
对于现有的一些数据集,比如VQAv1,给出的正确答案都不止一个,因此一般做分类的时候,都是使用的软交叉熵作为loss函数。但是这类交叉熵无法反应近似答案之间的相似性。
为了解决这个问题,作者提出了一个新的loss 函数,即semantic loss,定义这个loss函数需要(1)建立嵌入答案的语义空间(2)定义距离函数来测量答案之间的相似性。
(1)投影到语义空间(Projection to a semantic space)
语义空间需要满足的条件有两个,一个是结构化,二是能够被连续的自然神经网络处理。这里作者提出了两个不同的语义空间:
Glove:该空间常用于将离散的字符嵌入到连续的向量,它是通过自监督的方式训练的。Glove能够捕捉语义和语法规则。作者直接利用Glove将答案类别投影到向量化的表示。
Co-oc:主要使用统计规则来估计语义近似程度。
(2)两个语义空间的差异(Differences of the spaces Glove and Co-oc)
两个稍有不同,Glove用语料库中出现的单词,Co-co则是利用人类的标注数据。这里作者举了一些例子:

(3)语义空间中的距离(Distances in the semantic space)
这个才是算法的核心,作者使用了余弦相似度来定义两个变量的接近程度:
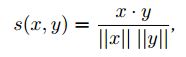
然后可以定义semantic loss:
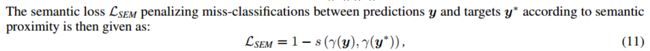
两种loss的差异可以如下图所示:

最后模型的loss可以表示为:
![]()
其中CE表示交叉熵,BCE表示二值交叉熵。λ是一个超参数。
4. 实验
数据集:VQAv2和VQAv2-CP。
对比的算法:
Bottom-Up-Top-Down (UpDn);
Bilinear Attention Network (BAN);
Deep Modular Co-Attention Networks (MCAN);
实验结果如下表所示:
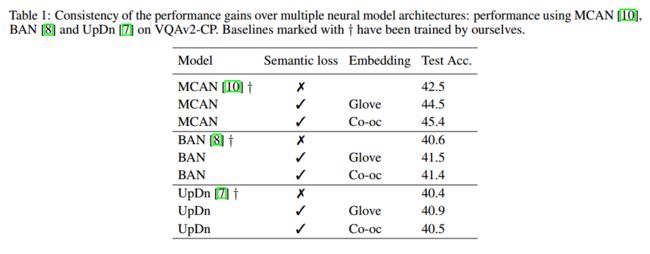
semantic loss能够一定程度上提高模型效果:

在VQA2.0上的结果:
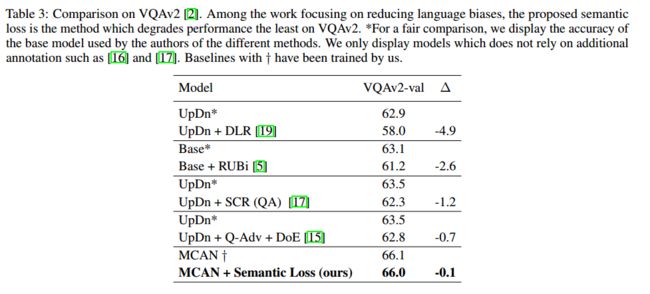
再加上RUBi与其他模型的比较结果: