SugarRecord的使用和源码分析
SugarRecord的使用和源码分析
SugarRecord是用来操作本地数据库的ORM框架,ORM(Object-Relational-Map)即对象映射模式,我们在操作数据库的时候,不需要和复杂的sql语句打交道,只需要调用对象的属性和方法来实现数据库的增删改查。
下面来看sugarRecord的基本使用
首先再gradle文件中添加依赖
compile 'com.github.satyan:sugar:1.5'同时在AndroidManifest.xml中添加键值对,在Application标签目录下
"@string/app_name"android:icon="@drawable/icon"
android:name="com.orm.MyApp">
.
.
"DATABASE"android:value="sugar_example.db"/>
"VERSION"android:value="2"/>
"QUERY_LOG"android:value="true"/>
"DOMAIN_PACKAGE_NAME"android:value="com.example.sugarrecord"/>
.
.
确定数据库的数据库的名字,版本、sql查询语句Log是否开启,和主包名,在初始化数据库时会用到上面的信息。
在App类初始化数据库
public class App extends Application {
@Override
public void onCreate() {
super.onCreate();
SugarContext.init(this);
}
@Override
public void onTerminate() {
super.onTerminate();
//退出关闭数据库
SugarContext.terminate();
}
}创建SugarContext单例对象,

创建数据库SugarDb,SugarDb继承SQLiteOpenHelper,还记得吗?这是一个原生的操作数据库的类,通过获得操作数据库对象,SQLiteOpenHelper中onCreate()方法是在第一次创建数据库的调用,onUpgrade是判断当前版本号发生变化时执行,升级数据库。

schemaGenerator是生成表的工具类,在创建表时会遍历在DOMAIN_PACKAGE_NAME包名下的类,如果某个类的父类是SugarRecord或者有@Table注解的类,则会创建以该类名大写作为表名的数据库表。
在初始化SugarContext时也创建了一个synchronizeMap,它是支持线程同步的Map,它 的每一个方法都加了同步锁,每次操作数据库时只能允许一个线程操作,synchronizeMap在性能上稍微会差一点,那么这个map有什么作用呢,他是用来储存以键ID,值是实体类,这样我们可以直接通过findById找到对应的对象。在update某一条数据时可以直接先通过map找到对应的对象,优化性能。
创建一个OrderBean文件,继承SugarRecord,
public class OrderBean extends SugarRecord {
private String orderNumber;
private String orderTime;
private String orderSum;
private String commodityCategory;
public String getOrderNumber() {
return orderNumber;
}
public void setOrderNumber(String orderNumber) {
this.orderNumber = orderNumber;
}
public String getOrderTime() {
return orderTime;
}
public void setOrderTime(String orderTime) {
this.orderTime = orderTime;
}
public String getOrderSum() {
return orderSum;
}
public void setOrderSum(String orderSum) {
this.orderSum = orderSum;
}
public String getCommodityCategory() {
return commodityCategory;
}
public void setCommodityCategory(String commodityCategory) {
this.commodityCategory = commodityCategory;
}或者在类对象前加一个@Table注解,表示这是一个表
@Table
public class OrderBean {
private String orderNumber;
private String orderTime;
...
... 一、添加
OrderBean bean=new OrderBean();
bean.setOrderNumber("123");
bean.setOrderTime("2017/09/14");
save();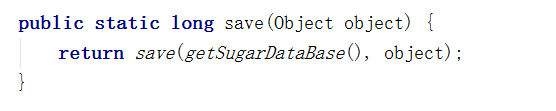
getSugarDataBase()是获取操作数据库的getWriteableDataBase()对象
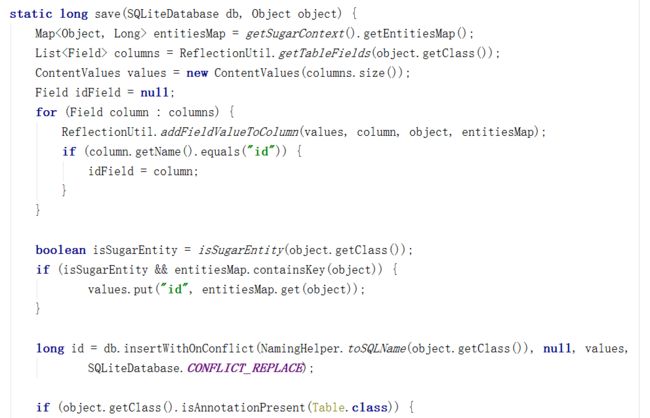
ReflectionUtil反射工具类是操作获取类的所有属性字段作为column,

这里要强调一点,如果你不想把某个字段存入数据库,可以用@Ingore注解该字段,在创建类时会忽略。
ContentValues是一个HashMap,用来存储每一列的值,遍历每一列,取出每一个字段的值,储存到ContentValues,如果这个类是的私有字段引用类型,且是数据库表,则会将这个字段存到Id属性中。因此Id属性列中存的是该对象,也在entitiesMap中,db.insert…执行的是真正的插入数据库操作,插入成功后会返回一个id,将这个id设置给id属性。
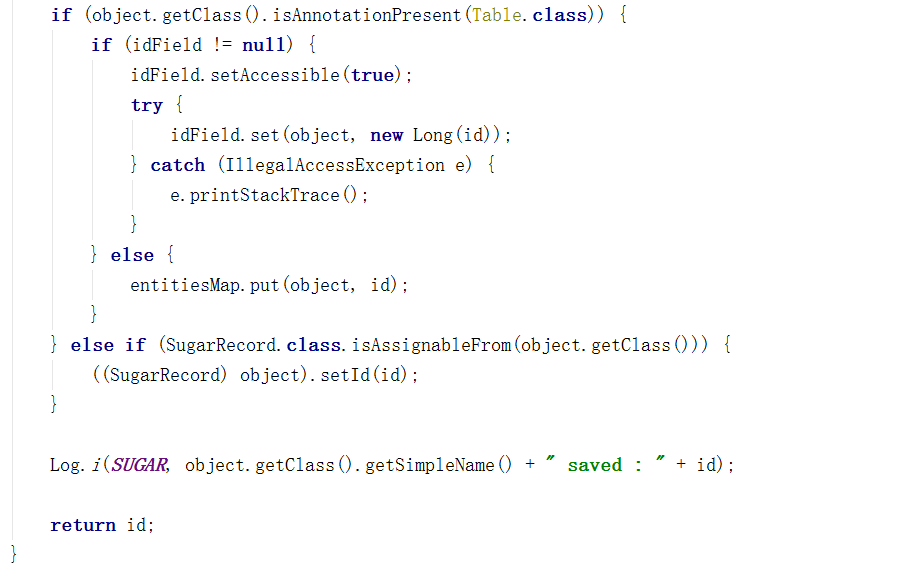
二、更新
public class TestBean extends SugarRecord {
@Unique
private String name;
private int age;
private String gender;
...
...
}
TestBean bean=new TestBean();
bean.setName("小明");
bean.setAge(18);
bean.setGender("男");
bean.setProfessional("IT狗");
long id=bean.save();
TestBean bean2=new TestBean();
bean2.setName("小明");
bean2.setAge(22);
bean2.setGender("男");
bean2.setProfessional("老师");
long id2=SugarRecord.update(bean2);
要更新某一条数据,需要先确定某一个属性是唯一的,用@Unique标记,更新前后这个字段值是不变的,根据这个字段更新同一条数据。


遍历每一列的字段,如果有@Unique注解,取出值保存在where语句集合中,执行db.update语句更新数据,如果没有@Unquie注解则save()新增数据。
三、查询
TestBean.listAll(Class type);
TestBean.listAll(Class type,String orderBy); 查询表中的所有数据,返回一个List 集合,默认是按ID升序排列的,如果想按降序排列可以
List listBean=TestBean.listAll(TestBean.class,"ID DESC"); TestBean.findById(Class type,id);
TestBean.findById(Class type,String[] ids); 根据id查询数据,或者根据id数组查询数据
TestBean first=TestBean.first(TestBean.class); //取出升序的第一条数据
TestBean last=TestBean.last(TestBean.class); //取出降序的第一条数据,即最后一条数据TestBean.findAll(TestBean.class);//返回Iterator迭代器
while(iterator.hasNext()){
TestBean bean=iterator.next();
} TestBean.find(TestBean.class,"NAME","小明");//根据条件查询数据,返回List集合 TestBean.count(TestBean.class)//查询表中一共有多少条数据
TestBean.count(TestBean.class,"NAME","小明");//根据条件查询数据条数四、删除
bean.delete();
//或者
SugarRecord.delete(bean);根据id删除这条数据
TestBean.deleteAll(TestBean.class);删除表中的全部数据
java
TestBean.deleteAll(TestBean.class,"AGE",18)//删除表中年龄为18的全部数据
根据条件删除数据
五、一对多的情况
很多情况下,一个类关联另一个类,一个对象包含另一个对象的引用,比如
public class TestBean extends SugarRecord {
@Unique
private String name;
private int age;
private String gender;
private String professional;
private OrderBean orderBean;
...
}
//
public class OrderBean extends SugarRecord{
private String orderNumber;
private String orderTime;
private String orderSum;
...添加数据
TestBean bean=new TestBean("小明",18,"老师");
OrderBean order=new OrderBean("11","上午","13");
order.save();
bean.setOrderBean(order);
long id=bean.save();
查询数据
TestBean bean=TestBean.findById(TestBean.class,id);
OrderBean order=bean.getOrderBean();还有一种一对多的情况,是一个对象里面包含另一个对象的集合,比如
public class TestBean extends SugarRecord {
@Unique
private String name;
private int age;
private String gender;
private List orderList;
...
}
//
public class OrderBean extends SugarRecord{
private String orderNumber;
private String orderTime;
private String orderSum;
...
} 如果直接和前面一种一样处理,你会发现orderList=null;从源码中可以看到,没有对list集合的判断,那应该怎么处理呢,可以将TestBean的一个唯一属性赋给OrderBean,那么在OrderBean中的这个属性的值是相同的,在通过
OrderBean,find查询返回list集合。
public class TestBean extends SugarRecord {
@Unique
private String name;
private int age;
private String gender;
...
}
//
public class OrderBean extends SugarRecord{
private String orderNumber;
private String orderTime;
private String orderSum;
//这个是自己手动添加的,目的是建立两个表的联系
private String name;
...
}
//添加到数据库
TestBean bean=new TestBean();
for(OrderBean order: orderList ){
order.setName(bean.getName());
order.save();
}
long id=bean.save();
//查询
TestBean bean1=TestBean.findById(TestBean.class,id);
List list=OrderBean.find(OrderBean.class,"NAME= ?",bean1.getName());
记住:在每次有添加数据库表,或者更新字段时都要升级数据库版本,更改Manifest.xml中value的值,否则会报错。