线程池与Android的日日夜夜
线程池与Android的日日夜夜
假如你Java中研究到了线程池的话,一般来说,你已经对线程的原理颇有研究了,或者说,你意识到了线程的某些瓶颈或者缺点。你说,要有光,所以,天降线程池。

正儿八经的说,如果你为每一个请求创建一个新的线程,这在性能上影响是巨大的,因为线程对象的创建销毁需要Java虚拟机频繁的GC,假如说,一个请求所用的时间比创建销毁线程对象时间还短的话,那么时间将会大程度浪费在虚拟机的GC上,系统性能降低。

所以啊,线程池主要就是复用线程对象,就跟上面所说,解决线程对象频繁创建和销毁的问题,内部可以抽象成一个“池”,线程对象放在里头,需要用的时候就拿出来用,不用了就泡着,泡坏了或者不要了就清掉。也正因为如此,线程池可以用来处理高并发的访问请求。
目录
- 先从最基本的线程的3种用法说起
- 一个最基本的线程池用例
- 分析各种参数:线程池创建的ThreadPoolExecutor类
- 常见阻塞队列及使用场景
- 比较Executors中3种线程池的区别和使用情景
- 对比线程和线程池的优缺点,各种使用场景及其区别
- 其他:并发集合框架
- 默认Executors生成线程池和自传参数进构造方法ThreadPoolExecutor创建线程池的利弊
- 分析实际应用,如OkHttp中的线程池,如AsyncTask中的线程池,RxJava中的线程池
一 先从最基本的线程开始
先重新了解一下,创建线程的三种方法:
- 继承Thread类创建线程
- 实现Runnable创建线程
- 实现Callable接口 、使用Future类接收返回值
(1)继承Thread类,重写父类run方法
public class MyThread extends Thread {
@Override
public void run() {
super.run();
System.out.println("biubiubiu");
}
public static void main(String[] arg){
MyThread myThread = new MyThread();
myThread.start();
}
}(2)实现Runnable接口,实现接口的run方法
public class MyRunnable implements Runnable {
public static void main(String[] arg) {
MyRunnable myRunnable = new MyRunnable();
Thread thread = new Thread(myRunnable);
thread.start();
}
@Override
public void run() {
System.out.println("光头强和熊大熊二");
}
}当然,我们最常用的是匿名的内部Runnable类
public class MyRunnable {
public static void main(String[] arg) {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("光头强的斧头");
}
});
thread.start();
}
}(3)实现Callable接口,使用Future来接收返回值(接收可选)
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class MyCallable implements Callable<String> {
public static void main(String[] arg) {
MyCallable myCallable = new MyCallable();
FutureTask futureTask = new FutureTask<>(myCallable);
new Thread(futureTask).start();
try {
System.out.println(futureTask.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
@Override
public String call() throws Exception {
return "猪猪侠";
}
}
二、一个最基本的线程池用例
先放一个基本的线程池,这里构造的是核心线程为2,最大线程数为5,有界阻塞数列为5的线程池
import java.util.concurrent.*;
public class MyDemo {
public static void main(String[] arg) {
ExecutorService executorService = new ThreadPoolExecutor(2, 5, 60, TimeUnit.MILLISECONDS, new ArrayBlockingQueue(5));
for (int i = 0; i < 13; i++) {
int finalI = i;
executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println("当前顺序是:" + finalI + ",线程名字" + Thread.currentThread().getName());
}
});
}
}
}
console如下
Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task MyDemo$1@135fbaa4 rejected from java.util.concurrent.ThreadPoolExecutor@45ee12a7[Running, pool size = 5, active threads = 5, queued tasks = 5, completed tasks = 0]
at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063)
at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379)
at MyDemo.main(MyDemo.java:10)
当前顺序是:0,线程名字pool-1-thread-1
当前顺序是:2,线程名字pool-1-thread-1
当前顺序是:3,线程名字pool-1-thread-1
当前顺序是:4,线程名字pool-1-thread-1
当前顺序是:5,线程名字pool-1-thread-1
当前顺序是:6,线程名字pool-1-thread-1
当前顺序是:1,线程名字pool-1-thread-2
当前顺序是:7,线程名字pool-1-thread-3
当前顺序是:8,线程名字pool-1-thread-4
当前顺序是:9,线程名字pool-1-thread-5
先看这里的console,这里打印了RejectedExecutionException异常,还有打印了10个线程执行方法体里头的信息。后面的线程名字有6个1。其他的都是单独的2,3,4,5号,这里说明线程在线程池中得到了复用。
三、线程池创建的ThreadPoolExecutor类
ThreadPoolExecutor类有4个构造方法,其中的三个构造方法最终会调用参数最多的(7个)的构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
.. 构造方法各个参数:
1. corePoolSize:线程池中的核心线程数,一般情况设置为CPU核心数
2. maximumPoolSize:线程池的线程数量最大值,非核心线程数=最大值-核心线程数
3. keepAliveTime:非核心线程闲置时候的超时回收时间,要是想多任务(该任务轻量执行内容/块)下线程的利用率,可以增大这个超时时间
4. unit:上面这个参数的单位,有分秒毫秒等等
5. workQueue:线程池的任务队列。新建的线程数超过核心线程时,线程加入任务队列进 行等待或者分发。常用的有ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue
6. threadFactory:线程池的线程工厂。常用来设置每个线程的名字。默认名字是 pool-1-thread-1,一般默认为Executors.defaultThreadFactory()即可,当然,ThreadPoolExecutor类的构造方法最终都是传入DefaultThreadFactory
7. RejectedExecutionHandler:饱和策略。当任务队列和线程池都达到最大值时的处理策略。默认是无法处理新的任务的AbortPolicy。比如上面第二节console输出的是AbortPolicy策略。那是因为创建的最大线程数是5,任务队列是5,那么线程池中会存在10个线程,而我创建了13个线程的同时超过了10个线程,接着就会抛出这个RejectedExecutionHandler异常
1. 线程池的处理过程
拿第二节创建的线程池来举例,核心线程是2,最大线程数是5(说明非核心线程数为3)。任务队列是ArrayBlockingQueue(特点是它用数组实现,元素排序规则是先进先出,默认不保证线程池按照阻塞的先后顺序访问队列),数量为5个,超时为6秒,其他都为默认。
那么,其实内部是这样的——–>看图:
- 核心线程未饱和

当只有1核心线程时,这时新建的任务会直接添加为核心线程
- 核心线程饱和队列未饱和

当核心线程已满,任务队列未饱和时,这时新建的任务会添加到工作队列
- 核心线程饱和队列饱和非核心线程未饱和

当核心线程已满,任务队列已饱和,非核心线程未饱和时,新建的任务会添加为非核心线程。
- 核心线程饱和队列饱和非核心线程饱和
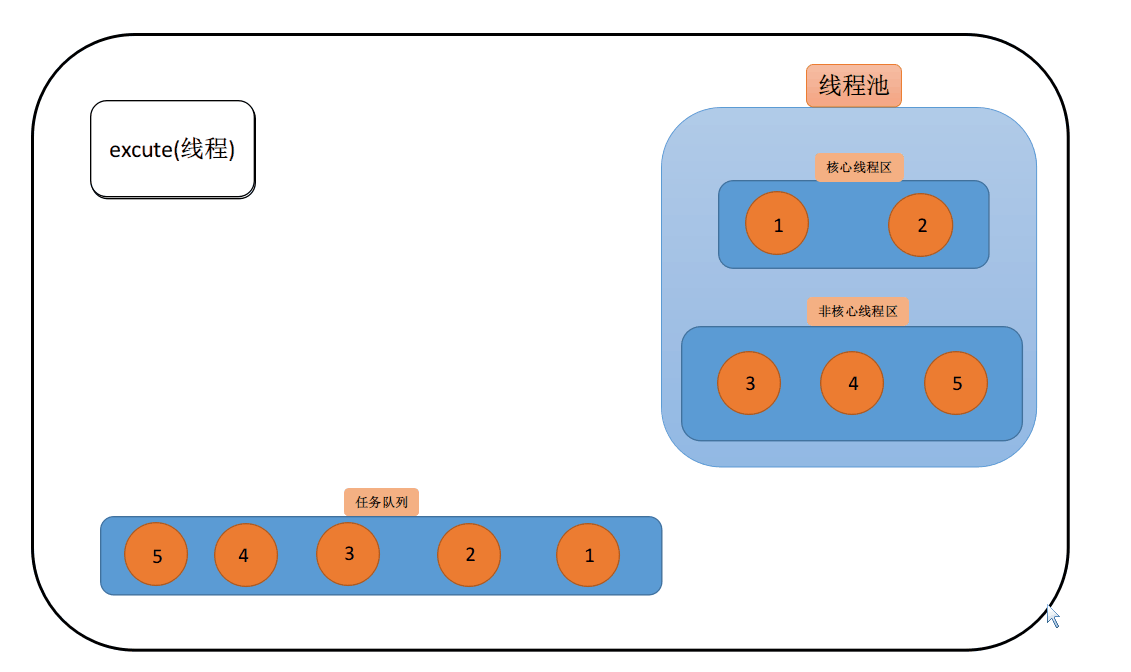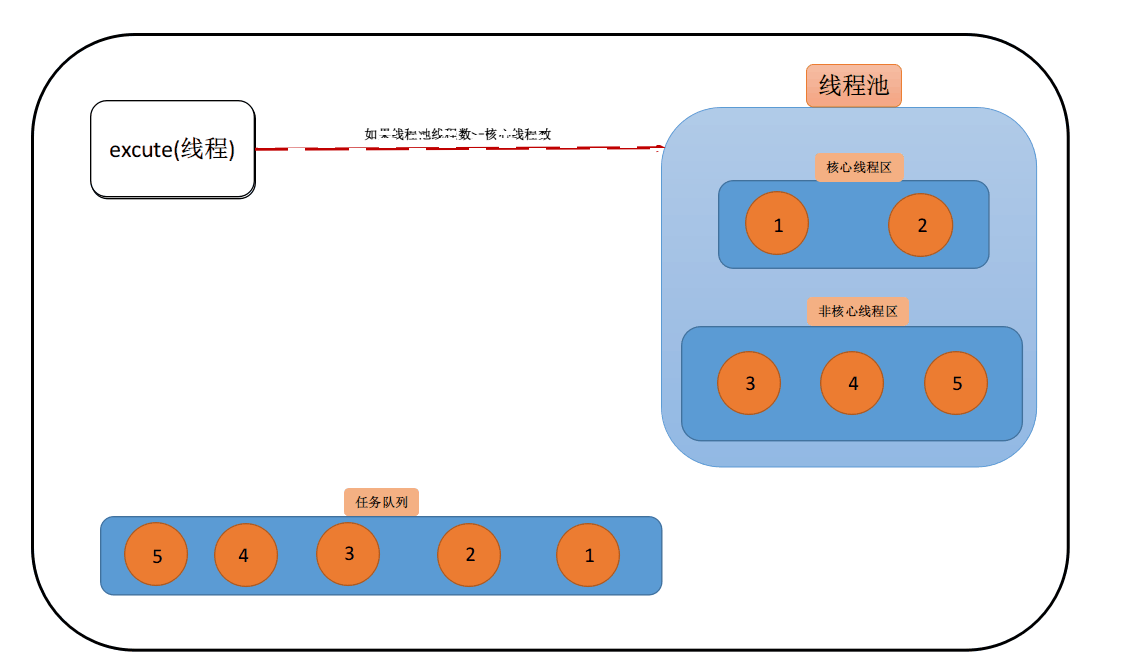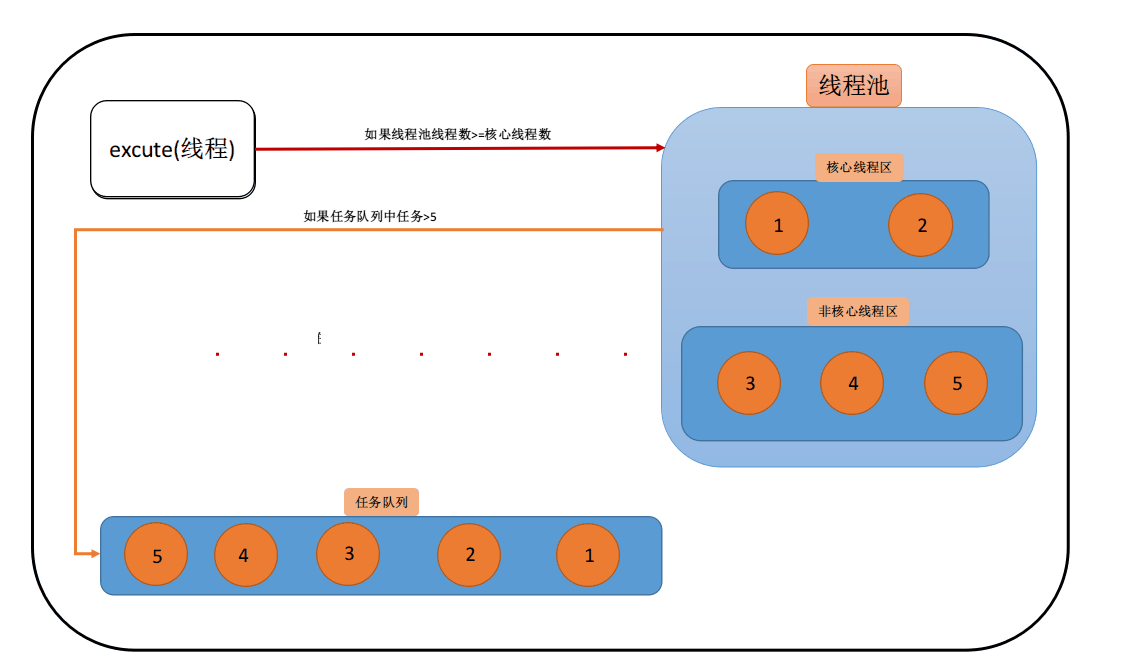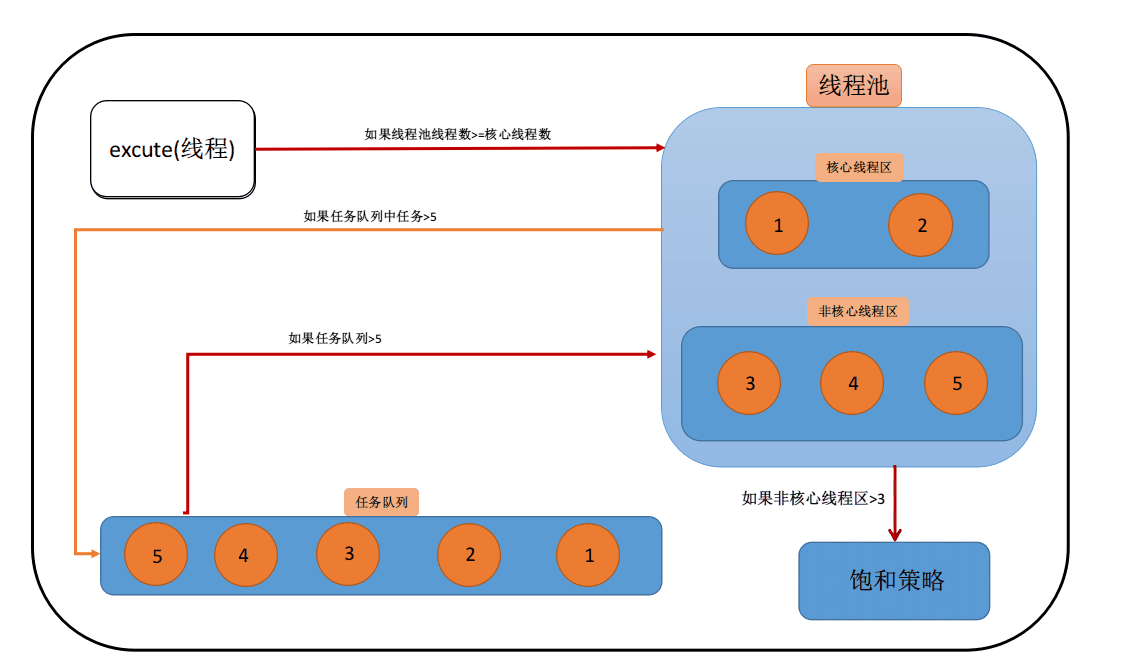
当线程池线程已达最大值,队列也已饱和,这时新建任务会执行饱和策略
总结起来,其实就是:

这里很懵逼的是阻塞队列,事实上不是每个阻塞队列都像ArrayBlockingQueue如此,下节将分析常用的阻塞队列
四、常见阻塞队列及使用场景
阻塞队列使用方法大同小异,只要了解他的内部结构构成,以及由其结构影响的各种特性即可,具体测试及用法可看
BlockingQueue(阻塞队列)详解、
深入理解阻塞队列(二)——ArrayBlockingQueue源码分析、
深入理解阻塞队列(三)——LinkedBlockingQueue源码分析
常用的几种阻塞队列如下:
- ArrayBlockingQueue:有界阻塞队列,它用数组实现,元素排序规则是先进先出,默认不保证线程池按照阻塞的先后顺序访问队列,一般构造方法会指定元素数量,和是否公平顺序按照阻塞顺序访问队列,通常用在需要生产者和消费者顺序的操作队列中的数据,以降低吞吐量的时候,比如
- LinkedBlockingQueue:有界阻塞队列,链表实现,与ArrayBlockingQueue区别不同,它是并行的操作队列中的数据,这也决定了它能用于高并发,巨大吞吐量的情况,需要注意的是,LinkedBlockingQueue的容量记得要指定哦,不然太大了加入生产者的速度大于消费者,那么队列阻塞可能不会阻塞,因为内存会炸。
- SyschronousQueue:不存储元素的异步队列,有个特点,插入操作的完成要等待另一个线程的对应移除操作,适合那种立即处理且耗时较少的任务。
五、比较Executors中3种线程池的区别和使用情景
其实不止3种(有6种),这里只分析其中常用的4种,其他的大同小异
FixedThreadPool:固定线程数的线程池,特点在核心线程和线程最大数量相等,意味着只有核心线程,keepAliveTime时间为0说明多余线程马上停止,队列它用的是new LinkedBlockingQueue,这里源码点进去看发现指定队列容量为无穷大。总结的说,就是线程池大小固定,任务队列无界()
/**
* Creates a thread pool that reuses a fixed number of threads
* operating off a shared unbounded queue. At any point, at most
* {@code nThreads} threads will be active processing tasks.
* If additional tasks are submitted when all threads are active,
* they will wait in the queue until a thread is available.
* If any thread terminates due to a failure during execution
* prior to shutdown, a new one will take its place if needed to
* execute subsequent tasks. The threads in the pool will exist
* until it is explicitly {@link ExecutorService#shutdown shutdown}.
*
* @param nThreads the number of threads in the pool
* @return the newly created thread pool
* @throws IllegalArgumentException if {@code nThreads <= 0}
*/
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
} - 应用场景:保证所有任务都会被执行,永远不拒绝新任务。但是假如任务时间无限长的时候会出现由于队列数量过大引起的内存问题。
CacheThreadPool:核心线程为0,线程最大值为无穷大,说明
非核心线程数是无穷大的,空闲线程等待新任务的时间是60s。这里阻塞队列用的是new SynchronousQueue说明每个插入和移除操作要同步进行。总结的说,就是线程池无心大,等待长度为1(因为阻塞队列的原因)()
/**
* Creates a thread pool that creates new threads as needed, but
* will reuse previously constructed threads when they are
* available. These pools will typically improve the performance
* of programs that execute many short-lived asynchronous tasks.
* Calls to {@code execute} will reuse previously constructed
* threads if available. If no existing thread is available, a new
* thread will be created and added to the pool. Threads that have
* not been used for sixty seconds are terminated and removed from
* the cache. Thus, a pool that remains idle for long enough will
* not consume any resources. Note that pools with similar
* properties but different details (for example, timeout parameters)
* may be created using {@link ThreadPoolExecutor} constructors.
*
* @return the newly created thread pool
*/
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
} - 应用场景:适合大量的需要立即处理并且耗时较少的的任务
SingleThreadPool:核心线程和最大线程数都为0,也就是说SingleThreadPool只有一个核心线程,后面的等待时间队列都和FixedThreadPool一样。总结的说,就是线程池大小固定为1,任务队列无界。
/**
* Creates an Executor that uses a single worker thread operating
* off an unbounded queue. (Note however that if this single
* thread terminates due to a failure during execution prior to
* shutdown, a new one will take its place if needed to execute
* subsequent tasks.) Tasks are guaranteed to execute
* sequentially, and no more than one task will be active at any
* given time. Unlike the otherwise equivalent
* {@code newFixedThreadPool(1)} the returned executor is
* guaranteed not to be reconfigurable to use additional threads.
*
* @return the newly created single-threaded Executor
*/
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
} - 应用场景:它的特性保证所有了所有的任务在一个线程中按顺序运行。所以它适用于在逻辑上需要单线程处理任务的场景。由于阻塞队列无限大,同样可能会出现FixedThreadPool的耗时过长时产生的内存问题。
六、对比线程和线程池的优缺点,各种使用场景及其区别
我们知道使用线程池可以大大的提高系统的性能,提高程序任务的执行效率,在线程池中,每一个工作线程都能得到重复利用,执行多个任务,减少对象新建回收的次数。
线程缺点:
1、每次新建线程都需要新建对象
2、没有定时执行,定期执行,中断
3、不能统一管理,有些时候会发生线程之间对资源的竞争,一定情况下就会内存泄漏。
线程池缺点:
1、一旦加入到线程池中就没有办法让它停止,除非任务执行完毕自动停止;
2、一个进程共享一个线程池;
3、要执行的任务不能有返回值(当然,线程中要执行的方法也是不能有返回值,如果确实需要返回值必须采用其它技巧来解决);
4、在线程池中所有任务的优先级都是一样的,无法设置任务的优先级;
5、不太适合需要长期执行的任务(比如在Windows服务中执行),也不适合大的任务;
6、不能为线程设置稳定的关联标识,比如为线程池中执行某个特定任务的线程指定名称或者其它属性。
线程池优点:
1、重用已存在的线程,减少对象创建、回收次数,提高JVM性能
2、通过控制最大线程数,提高系统资源利用率
3、定时执行、定期执行、并发数控制。
线程池使用场景
实际情况下,Web 服务器、数据库服务器、文件服务器或邮件服务器之类的许多服务器应用程序都需要用线程池去处理远程传过来的任务。
当然,如果说,细化的话,上面已分析过3种线程池的使用情况,其他的和他们三大体上分析过程是一样的。具体线程池的参数如何分配,需要根据实际需求情况去确定,重要的当然是分析过程咯哦。
2018-05-10 11:30AM
更新中…
参考
用线程池和不用线程池的区别是什么?