作者|Kelvin Lee
编译|Flin
来源|towardsdatascience
获得对正则化的直观认识
在机器学习中,正则化是一种用来对抗高方差的方法——换句话说,就是模型学习再现数据的问题,而不是关于问题的潜在语义。与人类学习类似,我们的想法是构建家庭作业问题来测试和构建知识,而不是简单的死记硬背:例如,学习乘法表,而不是学习如何乘。
这种现象在神经网络学习中尤为普遍——学习能力越强,记忆的可能性就越大,这取决于我们这些实践者如何引导深度学习模型来吸收我们的问题,而不是我们的数据。你们中的许多人在过去都曾遇到过这些方法,并且可能已经对不同的正则化方法如何影响结果形成了自己的直观认识。为你们中那些不知道的人(甚至为那些知道的人!)本文为正则化神经网络参数的形成提供了直观的指导。将这些方面可视化是很重要的,因为人们很容易将许多概念视为理所当然;本文中的图形和它们的解释将帮助你直观地了解,当你增加正则化时,模型参数的实际情况。
在本文中,我将把 L2 和 dropouts 作为正则化的标准形式。我不会讨论其他方法(例如收集更多数据)如何改变模型的工作方式。
所有的图形和模型都是用标准的科学Python堆栈制作的:numpy、matplotlib、scipy、sklearn,而神经网络模型则是用PyTorch构建的。
开发复杂函数
深度学习的核心原则之一是深度神经网络作为通用函数逼近的能力。无论你感兴趣的是什么,疾病传播,自动驾驶汽车,天文学等,都可以通过一个自学习模型来压缩和表达,这种想法绝对是令人惊奇的!尽管你感兴趣的问题实际上是是否可以用解析函数f来表示这些问题,但当你通过训练来调整机器学习模型时,该模型采用的参数θ允许模型近似地学习 f*。
出于演示的目的,我们将查看一些相对简单的数据:理想情况下,一维中的某些数据足够复杂,足以使老式曲线拟合变得痛苦,但还不足以使抽象和理解变得困难。我要创建一个复杂的函数来模拟周期信号,但是要加入一些有趣的东西。下面的函数实现如下方程:

其中A,B,C是从不同高斯分布中采样的随机数。这些值的作用是在非常相似的函数之间加上滞后,使得它们随机地加在一起产生非常不同的f值。我们还将在数据中添加白色(高斯)噪声,以模拟所收集数据的效果。
让我们将随机生成的数据样本可视化:在本文的其余部分中,我们将使用一个小的神经网络来重现这条曲线。
为了进行我们的模型训练,我们将把它分成训练/验证集。为此,我将在sklearn.model_selection中使用极其方便的train_test_split功能。让我们设计训练和验证集:
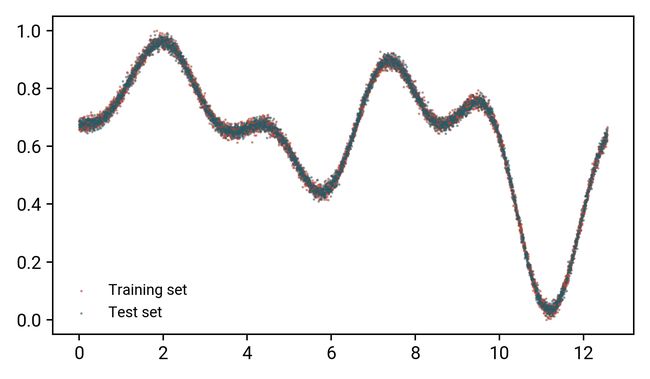
正如我们在图中看到的,这两个集合在表示整个曲线方面都做得相当好:如果我们删除其中一个,我们可以或多或少地收集到数据表示的相同图片。这是交叉验证的一个非常重要的方面!
开发我们的模型
现在我们有了一个数据集,我们需要一个相对简单的模型来尝试复制它。为了达到这个目的,我们将要处理一个四层的神经网络,它包含三个隐藏层的单个输入和输出值,每个隐藏层64个神经元。
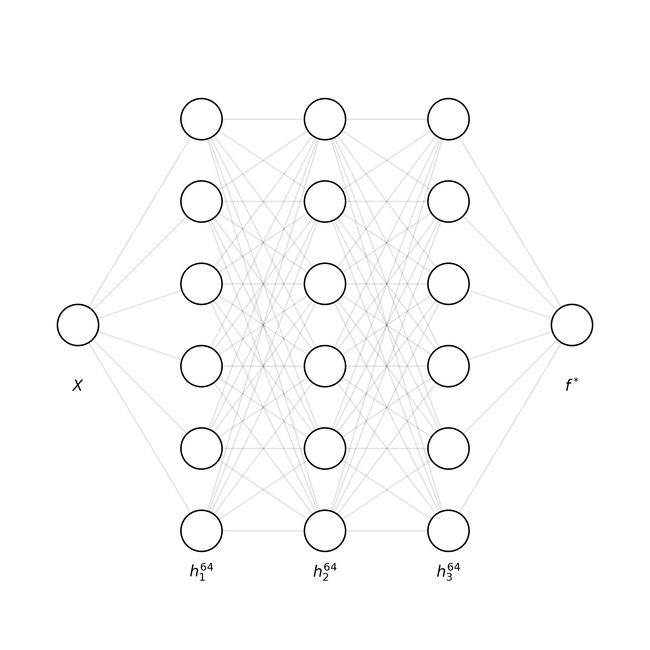
为了方便起见,每个隐藏层都有一个LeakyReLU激活,输出上有ReLU激活。原则上,这些应该不那么重要,但是在测试过程中,模型有时无法学习一些“复杂”的功能,特别是当使用像tanh和sigmoid这样容易饱和的激活函数时。在本文中,这个模型的细节并不重要:重要的是它是一个完全连接的神经网络,它有能力学习逼近某些函数。
为了证明模型的有效性,我使用均方误差(MSE)损失和ADAM优化器执行了通常的训练/验证周期,没有任何形式的正则化,最后得到了以下结果:
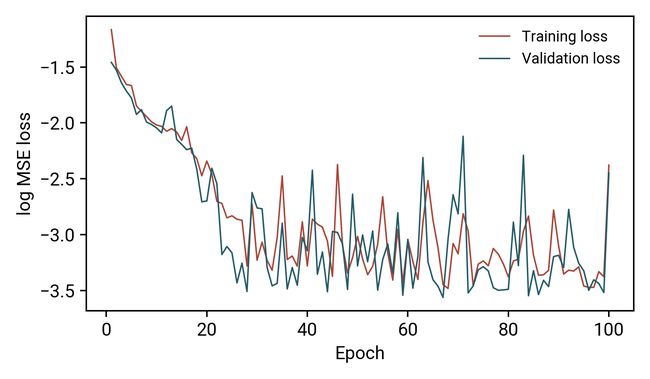
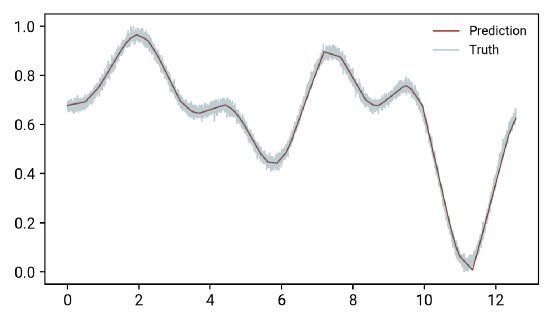
当我们使用此模型来预测:
除了曲率变化很快的区域(接近x=11)之外,这个模型很好地再现了我们的“复杂”函数!
现在,我可以听到你在问:如果模型运行良好,我为什么要做任何正则化?在本演示中,我们的模型是否过拟合并不重要:我想要理解的是正则化如何影响一个模型;在我们的例子中,它甚至会对一个完美的工作模型产生不利影响。在某种意义上,你可以把这理解为一个警告:当你遇到过度拟合时要处理它,但在此之前不要处理。用Donald Knuth的话说,“不成熟的优化是万恶之源”。
正则化如何影响参数
现在我们已经完成了所有的样板文件,我们可以进入文章的核心了!我们的重点是建立对正则化的直观认识,即不同的正则化方法如何从三个角度影响我们的简单模型:
-
训练/验证的损失会怎样?
-
我们的模型性能会发生什么变化?
-
实际的参数会怎样呢?
虽然前两点很简单,但是很多人可能不熟悉如何量化第三点。在这个演示中,我将使用核密度评估来测量参数值的变化:对于那些熟悉Tensorboard的人来说,你将看到这些图;对于那些不知道的人,可以把这些图看作是复杂的直方图。目标是可视化我们的模型参数如何随正则化而变化,下图显示了训练前后θ分布的差异:
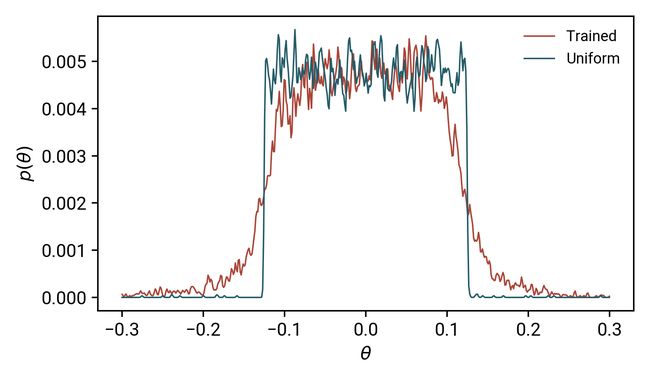
蓝色曲线被标记为“均匀的”,因为它代表了我们用均匀分布初始化的模型参数:你可以看到这基本上是一个顶帽函数,在中心具有相等的概率。这与训练后的模型参数形成了鲜明的对比:经过训练,模型需要不均匀的θ值才能表达我们的功能。
L2正则化
正则化最直接的方法之一是所谓的L2正则化:L2指的是使用参数矩阵的L2范数。由线性代数可知,矩阵的范数为:

在前神经网络机器学习中,参数通常用向量而不是矩阵/张量来表示,这就是欧几里得范数。在深度学习中,我们通常处理的是矩阵/高维张量,而欧几里德范数并不能很好地扩展(超越欧几里德几何)。L2范数实际上是上述方程的一个特例,其中p=q=2被称为Frobenius或Hilbert-schmidt范数,它可以推广到无限维度(即Hilbert空间)。

在深度学习应用中,应用这种L2正则化的一般形式是在代价函数J的末尾附加一个“惩罚”项:

很简单,这个方程定义了代价函数J为MSE损失,以及L2范数。L2范数的影响代价乘以这个前因子λ;这在许多实现中被称为“权值衰减”超参数,通常在0到1之间。因为它控制了正则化的数量,所以我们需要了解这对我们的模型有什么影响!
在一系列的实验中,我们将重复与之前相同的训练/验证/可视化周期,但是这是在一系列的λ值上。首先,它是如何影响我们的训练的?
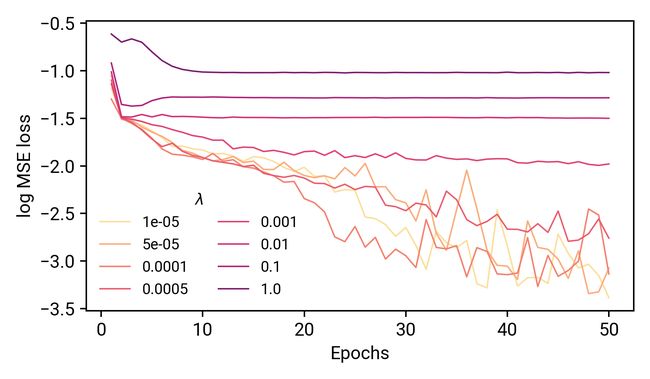
让我们来分析一下。更深的红色对应于更大的λ值(尽管这不是一个线性映射!),将训练损失的痕迹显示为MSE损失的日志。记住,在我们的非正则化模型中,这些曲线是单调递减的。在这里,当我们增加λ的值,最终训练误差大大增加,并且早期损失的减少也没有那么显著。当我们试图使用这些模型来预测我们的功能时,会发生什么?
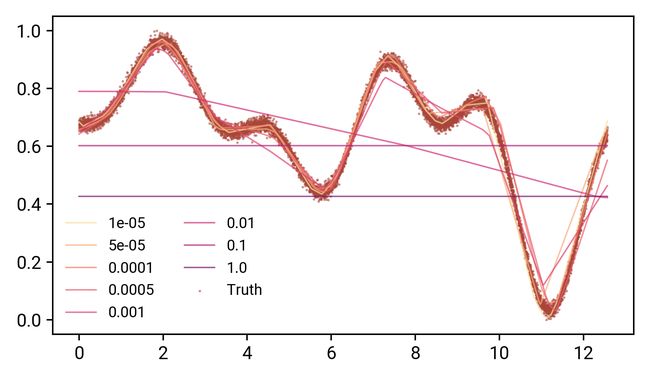
我们可以看到,当λ值很小时,函数仍然可以很好地表达。转折点似乎在λ=0.01附近,在这里,曲线的定性形状被再现,但不是实际的数据点。从λ>0.01,模型只是预测整个数据集的平均值。如果我们把这些解释为我们在训练上的损失,那么损失就会停止,这也就不足为奇了。
那么参数的分布呢?
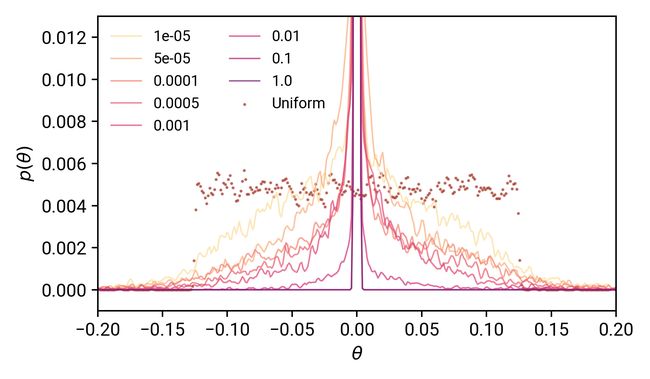
我们看到,参数值的传播大大受阻,正如我们的 λ 从低到高。与均匀分布相比,参数值的扩展越来越接近于零,λ=1.0时,θ的分布看起来就像一个在0处的狄拉克δ函数。由此,我们可以消除L2正则化作用于约束参数空间——强制θ非常稀疏并且接近零。
dropouts呢?
另一种流行且成本高效的正则化方法是在模型中包含dropouts。这个想法是,每次模型通过时,一些神经元通过根据概率p将它们的权值设置为0来失活。换句话说,我们对参数应用一个布尔掩码,每次数据通过不同的单元时都被激活。这背后的基本原理是将模型学习分布在整个网络中,而不是特定的一层或两层/神经元。
在我们的实验中,我们将在每个隐藏层之间加入dropout层,并将dropout概率p从0调整为1。在前一种情况下,我们应该有一个非正则化的模型,而在后一种情况下,我们各自的学习能力应该有所下降,因为每一个隐藏层都被停用了。
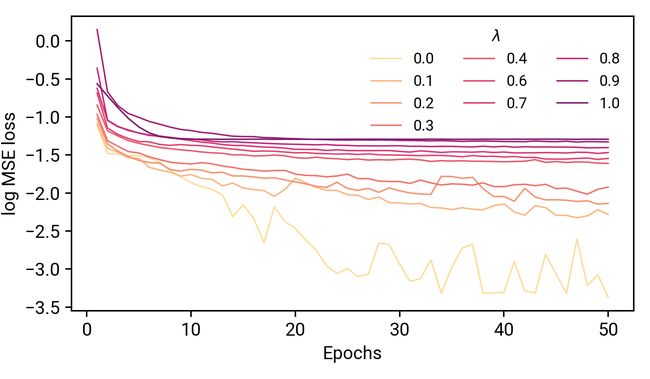
我们看到了与L2正则化非常相似的效果:总体而言,模型的学习能力下降,并且随着dropout概率值的增大,最终损失的比例也增大。
当我们试图使用这些模型来预测我们的功能时:
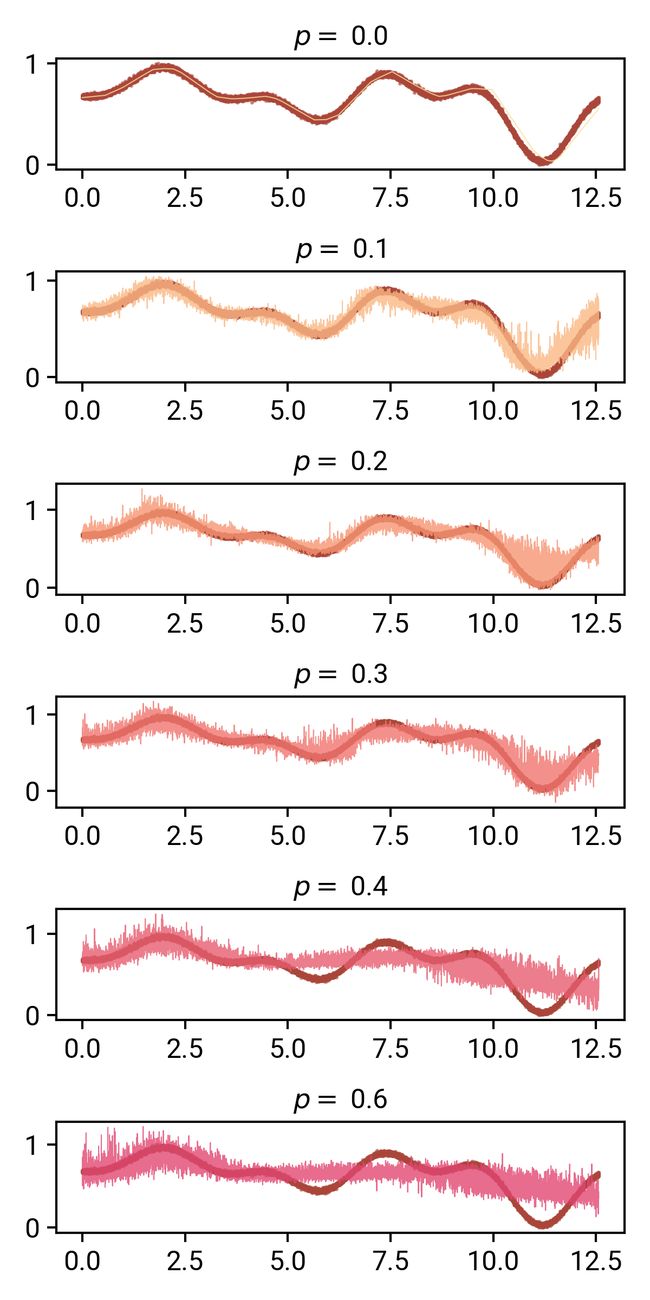
如图,我们逐步增加了dropout概率。从p=0.1开始,我们可以看到我们的模型对于它的预测开始变得相当不可靠:最有趣的是,它似乎近似地跟踪了我们的数据,包括噪音!
在p=0.2和0.3时,这一点在x=11时更加明显——回想一下,我们的非正则化模型很难得到正确的函数区域。我们看到,带dropout的预测实际上使这一区域难以置信的模糊,这几乎就像模型告诉我们,它是不确定的!(后面会详细介绍)。
从p=0.4开始,模型的能力似乎受到了极大的限制,除了第一部分之外,它几乎无法再现曲线的其他部分。在p=0.6时,预测结果似乎接近数据集的平均值,这似乎也发生在L2正则化的大值上。
我们的模型参数呢?
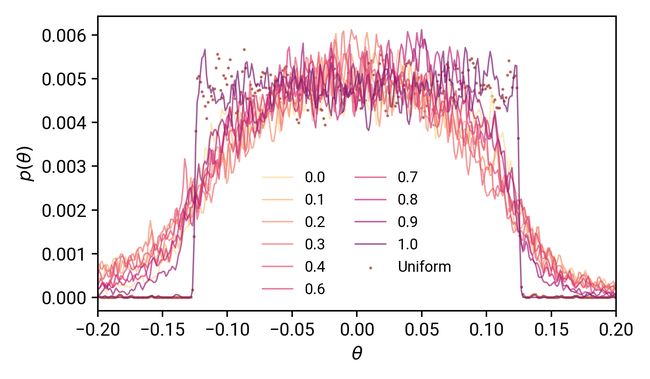
将此结果与我们的L2范数结果进行比较:对于dropout,我们的参数分布更广,这增加了我们的模型表达的能力。除p=1.0外,dropout概率的实际值对参数的分布影响不大,如果有影响的话。在p=1.0时,我们的模型没有学到任何东西,只是类似于均匀分布。在p值降低时,尽管速度降低了,模型仍然能够学习。
最后
从我们简单的实验中,我希望你已经从我们探索的三个角度,对这两种正则化方法如何影响神经网络模型形成了一些直观认识。
L2正则化非常简单,只需要调整一个超参数。当我们增加L2惩罚的权重时,因为参数空间的变化,对于大的值(0.01-1),模型容量下降得非常快。对于较小的值,你甚至可能不会看到模型预测有什么变化。
Dropouts是一种更复杂的正则化方法,因为现在必须处理另一层超参数复杂性(p可以为不同的层提供不同的值)。尽管如此,这实际上可以提供模型表达的另一个维度:模型不确定性的形式。
在这两种方法中,我们看到正则化增加了最终的训练损失。这些人工形式的正则化(与获取更多的训练数据相反)的代价是它们会降低模型的容量: 除非你确定你的模型需要正则化,否则在这样的结果下,你不会希望正则化。但是,通过本指南,你现在应该知道这两种形式如何影响你的模型!
如果你感兴趣,可以在Binder上(https://mybinder.org/v2/gh/laserkelvin/understanding-ml/master) 运行一些代码。我不需要运行torch模型(这会耗尽它们的资源),但是你可以使用它在notebook中查看代码。
原文链接:https://towardsdatascience.com/a-visual-intuition-for-regularization-in-deep-learning-fe904987abbb
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/