Android缓存源码分析(DiskLruCache,LruCache)
Android的常见的缓存有三种:网络缓存、文件缓存、内存缓存。这里网络缓存我不考虑,我们看下文件缓存(DiskLruCache)、内存缓存(LruCache)的源码是咋实现的。
一,LRU算法
文件缓存(DiskLruCache)和内存缓存(LruCache)用到的都是LRU缓存算法,LRU算法(Least Recently Used 最近最少使用)简单来说就是最近使用的会被留下来,最少使用的会被淘汰出去。
为了能够更好的理解LRU算法举个例子:比如我们缓存里面只能保留三个数据,缓存队列为: 4,3,4,2,3 ,1,4,2。
第一次数据进入: 4 进入,缓存:4
第二次数据进入: 3 进入,缓存:3,4
第三次数据进入: 4 进入,缓存:4,3
第四次数据进入: 2 进入,缓存:2,4,3
第五次数据进入: 3 进入,缓存:3,2,4
第六次数据进入: 1 进入,缓存:1,3,2 (4被淘汰了)
第七次数据进入: 4 进入,缓存:4,1,3 (2被淘汰了)
第八次数据进入: 2 进入,缓存:2,4,1 (3被淘汰了)
二,Android内部存储、外部存储
内部存储:/data 文件夹下的所有内容就是我们常说的内部存储。在内部存储文件中我们关注 /data/data/包名 这个文件夹下的内容,这个文件对每个应用来说是私有的别的应用访问不到。
/data/data/包名 常规文件结构如下:
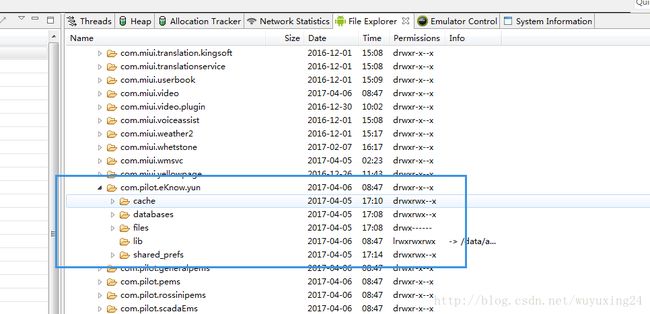
/data/data/包名 下有四个主要的文件cache,files,databases,shared_prefs。
- /data/data/包名/cache:context.getCacheDir()来获取该路径,用来保存缓存信息,但是我们自己开发应用的时候,一般也是尽量避免把缓存数据放这个目录下,优先考虑放到外部存储的缓存目录下,因为内部存储空间有限,要是内存存储耗尽了装不了其他的应用。
- /data/data/包名/files:context.getFilesDir()来获取路径,用来保存一些额外的信息到内部存储。
- /data/data/包名/databases:存放的是应用中用到的一些数据库。
- /data/data/包名/shared_prefs:存放的是应用中SharedPreferences保存的一些数据。
PS:当应用卸载的同时内部文件 /data/data/包名 这个文件会被删除掉。
外部存储:storage文件夹所有的内容,外部存储里面有一个文件我们经常接触到 /storage/Android/data/包名 文件。
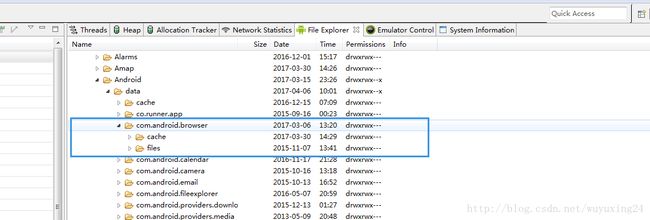
- /storage/Android/data/包名/cache:context.getExternalCacheDir()来获取该路径,用来保存缓存信息。
- /storage/Android/data/包名/files:context.getExternalFilesDir()来获取路径,用来保存一些额外的信息到外部存储。
PS:当应用卸载的同时内部文件 /storage/Android/data/包名 这个文件会被删除掉
Android中每个应用都有清除数据和清除缓存两个功能。这两个功能呢的作用分别是;
清除数据:清除的是 /data/data/包名 下面除lib文件夹之外的所有文件。
清除缓存:清除的是 /sdcard/Android/data/包名/cache 文件会被删除。
三,DiskLruCache源码分析
在分析DiskLruCache代码之前,先了解下LinkedHashMap双向循环链表,这是LRU算法的关键点,LinkedHashMap有一个三个函数的构造函数(DiskLruCache,LruCache里面用的都是这个)这里LinkedHashMap构造函数的第三个参数还有意思啊;true:基于访问顺序,false:基于插入顺序。基于访问顺序就是当访问了LinkedHashMap某个结点的时候内部都会将这个结点移动到链表的尾部,没有访问的就一直在链表的头部放着。稍微做一个简单的处理在特定饿情况下把表头节点删除正好体现了LRU算法。很有意思的一个点。
- DiskLruCache源码下载地址
- DiskLruCache简单介绍
DiskLruCache是市面上文件缓存使用最多的一个类,可以把想缓存的数据缓存都文件中去。DiskLruCache缓存又两部分组成一个是日志文件journal,一个是具体的缓存内容(所有的缓存内容都是以文件的形式保存)如下图所示。

journal是DiskLruCache缓存的日志文件。journal文件包含两部分内容;前五行是文件头信息、之后记录了每个缓存内容读取存储的情况。
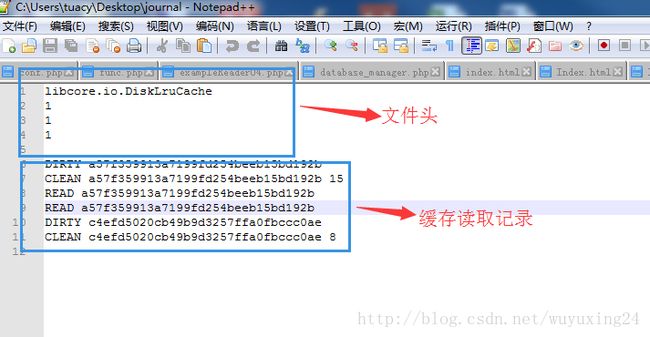
journal文件头第一行;标记固定为libcore.io.DiskLruCache、第二行DiskLruCache版本、第三行应用版本、第四行每个key对应缓存文件个数、第五行预留。
journal缓存记录信息,每一行都是一次记录信息,有四种情况:
a. CLEAN(空格)【 key】(空格) 【缓存文件大小】(空格)【缓存文件大小】….:表示指定key的缓存记录写入成功。(缓存文件大小循环次数和文件头第四行对应,如果是1就是CLEAN(空格)【 key】(空格) 【缓存文件大小】形式)
b. DIRTY(空格)【 key】:表示指定key的缓存正在被写入。(但是还没有Editor.commit()函数)
c. REMOVE(空格)【 key】:表示指定key的缓存写入失败。
d. READ(空格)【 key】:表示读取了指定key缓存信息。
3. DiskLruCache代码分析
使用DiskLruCache来实现文件缓存,用的最多的几个函数就是DiskLruCache对象初始化(open()),保存缓存记录(edit(),Editor.commit(),flush()),读取缓存记录(get())。代码的分析就从这三个方面入手。
- DiskLruCache对象初始化:

入口在open()函数。DiskLruCache对象初始化初始化的时候做的事情就两件事:第一通过日志文件头信息去判断之前缓存是否可用、第二解析之前缓存信息到LinkedHashMap
/**
* 初始化DiskLruCache对象
*
* @param directory 缓存日志文件,和缓存文件保存的目录。
* @param appVersion 应用版本号,如果版本号升级了,之前的缓存信息不在使用。
* @param valueCount 每个key可以对应多少个缓存文件,一般都是1
* @param maxSize 所有缓存文件的限制大小。
* @throws IOException 失败
*/
public static DiskLruCache open(File directory, int appVersion, int valueCount, long maxSize) throws IOException {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
if (valueCount <= 0) {
throw new IllegalArgumentException("valueCount <= 0");
}
// prefer to pick up where we left off
DiskLruCache cache = new DiskLruCache(directory, appVersion, valueCount, maxSize);
/**
* 判断日志文件是否存在
*/
if (cache.journalFile.exists()) {
/**
* 日志文件存在
*/
try {
/**
* 读缓存日志文件,同时会去判断标记,版本,应用版本信息如果不一致,会抛出异常,并且会把上次的缓存信息读到之前缓存信息到LinkedHashMap lruEntries中去
*/
cache.readJournal();
/**
* 对上一次的缓存信息做处理(根据lruEntries),计算所有缓存文件的大小,把正在被编辑的缓存删除掉。
*/
cache.processJournal();
cache.journalWriter = new BufferedWriter(new FileWriter(cache.journalFile, true), IO_BUFFER_SIZE);
return cache;
} catch (IOException journalIsCorrupt) {
// System.logW("DiskLruCache " + directory + " is corrupt: "
// + journalIsCorrupt.getMessage() + ", removing");
/**
* 操作失败,删除文件(这里会删除缓存目录下面所有的文件包括日志文件和日志临时文件和缓存文件)
*/
cache.delete();
}
}
/**
* 日志文件不存在,或者之前的缓存信息不可用了
*/
// create a new empty cache
directory.mkdirs();
cache = new DiskLruCache(directory, appVersion, valueCount, maxSize);
/**
* 重新构建一个日志文件
*/
cache.rebuildJournal();
return cache;
}23行,如果有日志文件说明之前有缓存过信息,这里对上次的缓存信息做处理,关键的东西在journal文件里面,从journal文件解析到之前的缓存信息。
31行,去读journal文件里面之前的缓存信息。判断缓存是否过期,同时把之前的缓存信息记录保存到lruEntries,Map里面去。
35行,对读到的上次缓存信息做处理,计算size,把没有调用Edit.commit()的缓存剔除掉。
readJournal()函数具体实现:
/**
* 读取缓存日志文件信息,主要做两件事
* 1. 读日志文件的头部信息,标记,缓存版本,应用版本,进而判断日志文件是否过期
* 2. 把日志文件的缓存记录读取到lruEntries,Map里面去。
*/
private void readJournal() throws IOException {
InputStream in = new BufferedInputStream(new FileInputStream(journalFile), IO_BUFFER_SIZE);
try {
/**
* 缓存日志文件第一行,标记
*/
String magic = readAsciiLine(in);
/**
* 缓存日志文件第二行,版本
*/
String version = readAsciiLine(in);
/**
* 缓存日志文件第三行,应用版本
*/
String appVersionString = readAsciiLine(in);
/**
* 缓存日志文件第四行,表示同一个key可以对应多少个缓存文件
*/
String valueCountString = readAsciiLine(in);
/**
* 缓存日志文件第五行,预留
*/
String blank = readAsciiLine(in);
/**
* 对日志文件头做判断
*/
if (!MAGIC.equals(magic) || !VERSION_1.equals(version) || !Integer.toString(appVersion).equals(appVersionString) ||
!Integer.toString(valueCount).equals(valueCountString) || !"".equals(blank)) {
throw new IOException(
"unexpected journal header: [" + magic + ", " + version + ", " + valueCountString + ", " + blank + "]");
}
while (true) {
try {
/**
* 读取日志信息(从第六行开始才是真正的日志信息)
*/
readJournalLine(readAsciiLine(in));
} catch (EOFException endOfJournal) {
break;
}
}
} finally {
/**
* 关闭InputStream
*/
closeQuietly(in);
}
}processJournal()函数具体实现:
/**
* 处理日志文件,
* 1. 会去计算整个缓存文件的大小size
* 2. 把正在被编辑的key(上次保存缓存的时候没有调用Edit.commit()),可以认为是没有写成功的缓存,重置掉(相应的缓存文件删除, 并且从lruEntries中删除掉)
*/
private void processJournal() throws IOException {
/**
* 删除日志临时文件
*/
deleteIfExists(journalFileTmp);
/**
* 遍历lruEntries(缓存map)
*/
for (Iterator i = lruEntries.values().iterator(); i.hasNext(); ) {
Entry entry = i.next();
if (entry.currentEditor == null) {
/**
* 有缓存文件
*/
for (int t = 0; t < valueCount; t++) {
size += entry.lengths[t];
}
} else {
/**
* 保存缓存的时候没有调用Edit.commit()
*/
entry.currentEditor = null;
for (int t = 0; t < valueCount; t++) {
deleteIfExists(entry.getCleanFile(t));
deleteIfExists(entry.getDirtyFile(t));
}
i.remove();
}
}
} - 保存缓存记录

要保存缓存的时候,要做两件事一时保存缓存文件,二是写缓存日志文件。为了保存缓存文件我们写的得到Edit对象,然后通过Edit对象得到OutputStream对象然后才可以写入文件,最后commit()提交保存。
总得来说五个步骤;调用edit()得到Edit对象,调用Editt.newOutputStream()得到OutputStream,调用OutputStream.write()把缓存写入文件,Edit.commit()确定缓存写入【commit不用每次都调用,可以挑个合适的时间调用】,最后调用flush()。
edit()函数得到Edit对象,拿到Edit对象之后就可以做一系列操作了。
/**
* 编辑key对应的缓存,获取到Editor然后可以做一些列的操作
*/
private synchronized Editor edit(String key, long expectedSequenceNumber) throws IOException {
checkNotClosed();
validateKey(key);
Entry entry = lruEntries.get(key);
if (expectedSequenceNumber != ANY_SEQUENCE_NUMBER && (entry == null || entry.sequenceNumber != expectedSequenceNumber)) {
return null; // snapshot is stale
}
if (entry == null) {
/**
* 新加入的缓存
*/
entry = new Entry(key);
lruEntries.put(key, entry);
} else if (entry.currentEditor != null) {
/**
* 之前加入过的缓存,并且这个缓存正在被编辑(没有调用Edit.commit())
*/
return null; // another edit is in progress
}
Editor editor = new Editor(entry);
entry.currentEditor = editor;
// flush the journal before creating files to prevent file leaks
/**
* key对应的缓存正在被写入,正在被编辑
*/
journalWriter.write(DIRTY + ' ' + key + '\n');
journalWriter.flush();
return editor;
}Edit.newOutputStream()得到OutputStream文件输出流。
/**
* 创建key对应的缓存文件的输出流,用来写入缓存到缓存文件
*/
public OutputStream newOutputStream(int index) throws IOException {
synchronized (DiskLruCache.this) {
if (entry.currentEditor != this) {
throw new IllegalStateException();
}
return new FaultHidingOutputStream(new FileOutputStream(entry.getDirtyFile(index)));
}
}Edit.commit()调用到completeEdit()函数,提交保存缓存完成。
/**
* 完成key对应缓存文件的写入之后,调用该函数(调用了newOutputStream(),set() 函数之后调用该函数)
*/
private synchronized void completeEdit(Editor editor, boolean success) throws IOException {
Entry entry = editor.entry;
/**
* 一一对应判断
*/
if (entry.currentEditor != editor) {
throw new IllegalStateException();
}
/**
* entry.readable = true 说明我们之前保存了该key对应的缓存文件
* entry.readable = false 说明我们之前没有保存该key对应的缓存文件(那肯定是准备些入缓存文件了)
*/
// if this edit is creating the entry for the first time, every index must have a value
if (success && !entry.readable) {
/**
* 之前没有保存key对应的缓存文件
*/
for (int i = 0; i < valueCount; i++) {
/**
* 调用了newOutputStream()之后entry.getDirtyFile(i).exists就是真的了
*/
if (!entry.getDirtyFile(i).exists()) {
editor.abort();
throw new IllegalStateException("edit didn't create file " + i);
}
}
}
for (int i = 0; i < valueCount; i++) {
File dirty = entry.getDirtyFile(i);
if (success) {
if (dirty.exists()) {
/**
* 缓存临时文件,重命名为缓存文件
*/
File clean = entry.getCleanFile(i);
dirty.renameTo(clean);
long oldLength = entry.lengths[i];
long newLength = clean.length();
entry.lengths[i] = newLength;
/**
* 缓存大小
*/
size = size - oldLength + newLength;
}
} else {
deleteIfExists(dirty);
}
}
redundantOpCount++;
/**
* 一次缓存文件的操作结束了,置为null
*/
entry.currentEditor = null;
if (entry.readable | success) {
entry.readable = true;
/**
* 标记一条entry写入成功
*/
journalWriter.write(CLEAN + ' ' + entry.key + entry.getLengths() + '\n');
if (success) {
entry.sequenceNumber = nextSequenceNumber++;
}
} else {
/**
* 如果是失败的情况,则移除
*/
lruEntries.remove(entry.key);
journalWriter.write(REMOVE + ' ' + entry.key + '\n');
}
/**
* 又来一次缓存大小的限制
*/
if (size > maxSize || journalRebuildRequired()) {
executorService.submit(cleanupCallable);
}
}- 读取缓存记录

读缓存记录这个就简单了得到Snapshot,然后通过Snapshot去得到InputStream或者直接得到具体的缓存内容。都会从缓存文件中去读取信息。
通过get()函数去得到Snapshot
/**
* 根据key取出缓存得到缓存key对应的Snapshot
*/
public synchronized Snapshot get(String key) throws IOException {
/**
* 日志文件是否关闭
*/
checkNotClosed();
/**
* key是否有效
*/
validateKey(key);
/**
* 每次open的时候会把日志文件里面的信息读到lruEntries里面去
*/
Entry entry = lruEntries.get(key);
/**
* 是否有该key对应的日志文件
*/
if (entry == null) {
return null;
}
/**
* 是否可读(是否有缓存文件)
*/
if (!entry.readable) {
return null;
}
/**
* 打开该key对应的所有的缓存文件,用来读取缓存文件
*/
InputStream[] ins = new InputStream[valueCount];
try {
for (int i = 0; i < valueCount; i++) {
ins[i] = new FileInputStream(entry.getCleanFile(i));
}
} catch (FileNotFoundException e) {
/**
* 文件被手动删除了
*/
// a file must have been deleted manually!
return null;
}
redundantOpCount++;
/**
* 日志文件记录一天read的记录
*/
journalWriter.append(READ + ' ' + key + '\n');
if (journalRebuildRequired()) {
/**
* 重新构建日志文件
*/
executorService.submit(cleanupCallable);
}
return new Snapshot(key, entry.sequenceNumber, ins);
}得到Snapshot之后通过Snapshot去读取缓存文件信息,这个就很容易了。
总结DiskLruCache。DiskLruCache的实现两个部分:日志文件和具体的缓存文件。每次对缓存存储的时候除了对缓存文件做相应的操作,还会在日志文件做相应的记录。每条日志文件有四种情况:CLEAN(调用了edit()之后,保存了缓存,并且调用了Edit.commit()了)、DIRTY(缓存正在编辑,调用edit()函数)、REMOVE(缓存写入失败)、READ(读缓存)。要想根据key从缓存文件中读取到具体的缓存信息,先得到Snapshot,然后根据Snapshot的一些方法做一些了的操作得到具体缓存信息。要保存一个缓存信息的时候写得到Editor,然后根据Editor对缓存文件做一些列的操作最后如果是保存了缓存信息记得commit下确认提交。
四,LruCache源码
有了上面DiskLruCache的分析,看LruCache就简单的多了,LruCache也是关键点在一个双向链表LinkedHashMap map上,同样这也是LRU算法的关键点。LruCache大部分都是在和这个LinkedHashMap打交道,不停的取出来,删除。当然在取出来或者存进去的时候得时时刻刻检查缓存的大小。LruCache里面每个缓存的大小都是要我们外部告诉LruCache的,因为LruCache不知道保存的是啥东西只能外部在构造LruCache的对象的时候通过重写sizeOf()函数来告诉LruCache每个缓存大小的计算方式。
- LruCache对象初始化:
在LruCache初始化的时候,主要做两件事情,一告诉LruCache总缓存限制大小,二告诉LruCache每个缓存的大小是怎么计算的。举个最简单的例子缓存string。
private static final int DISK_MAX_SIZE = (int) (Runtime.getRuntime().maxMemory() / 1024) / 10;
private LruCache mLruCache = null;
public MemoryCacheImp() {
mLruCache = new LruCache(DISK_MAX_SIZE) {
@Override
protected int sizeOf(String key, String value) {
return value == null ? 0 : value.length();
}
};
} - 读取缓存:
其实里面做的事情也蛮简单的,从LinkedHashMap里面根据key取出对应的value。
/**
* 获取key对应的缓存
*/
public final V get(K key) {
if (key == null) {
throw new NullPointerException("key == null");
}
V mapValue;
/**
* 线程安全
*/
synchronized (this) {
mapValue = map.get(key);
if (mapValue != null) {
/**
* 命中,返回
*/
hitCount++;
return mapValue;
}
/**
* 没有命中
*/
missCount++;
}
/*
* Attempt to create a value. This may take a long time, and the map
* may be different when create() returns. If a conflicting value was
* added to the map while create() was working, we leave that value in
* the map and release the created value.
* 下面感觉是对一些特殊的key做处理
*/
V createdValue = create(key);
if (createdValue == null) {
return null;
}
synchronized (this) {
createCount++;
mapValue = map.put(key, createdValue);
if (mapValue != null) {
// There was a conflict so undo that last put
map.put(key, mapValue);
} else {
size += safeSizeOf(key, createdValue);
}
}
if (mapValue != null) {
entryRemoved(false, key, createdValue, mapValue);
return mapValue;
} else {
trimToSize(maxSize);
return createdValue;
}
}- 保存缓存:
其实里面做的事情也是蛮简单的就是把key对应的value保存到LinkedHashMap里面去,同时对缓存的大小做限制,如果超过了最大大小从LinkedHashMap中剔除掉头部的节点。
/**
* 加入缓存 Caches {@code value} for {@code key}. The value is moved to the head of the queue.
*
* @return the previous value mapped by {@code key}.
*/
public final V put(K key, V value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
putCount++;
/**
* size大小增加
*/
size += safeSizeOf(key, value);
/**
* 放入缓存链表中
*/
previous = map.put(key, value);
if (previous != null) {
/**
* 说明之前缓存链表里面有这个key对应的结点缓存(size大小减掉之前的)
*/
size -= safeSizeOf(key, previous);
}
}
if (previous != null) {
/**
* 有结点移除调用该函数
*/
entryRemoved(false, key, previous, value);
}
/**
* 限制存储容量
*/
trimToSize(maxSize);
return previous;
}LruCache也就到这吧,也是一直在围绕LinkedHashMap这东西打转。
五,总结
DiskLruCache和LruCache一个是把缓存保存到文件中去,一个是把缓存直接保存在内存里面。DiskLruCache比LruCache要稍微复杂一点每个缓存保存一个文件并且还要做相应的日志记录,根据日志的信息方便应用下次进来的时候还能利用上之前保存的缓存信息。LruCache呢就完完全全是和LinkedHashMap打交道就行了。这里不管是DiskLruCache还是LruCache里面都是用到了LinkedHashMap的三个函数的构造函数。LinkedHashMap的第三个参数给的是true:基于访问顺序,换句话就是说当访问了LinkedHashMap中的某个结点的时候LinkedHashMap内部都会将这个结点移动到链表的尾部,这样就出现了一个结果,经常访问的节点会徘徊在LinkedHashMap尾部,没有被访问到的节点会徘徊在LinkedHashMap的头部,这样当缓存超过了限制大小的时候从LinkedHashMap的头部把节点删除就好了(DiskLruCache在删除的时候除了日志文件做记录,还会把缓存文件给删除)。
最后给一个写的没啥大用处的demo例子吧 下载链接地址