【Elasticsearch源码】查询源码分析(一)
1 前言
前面分析过ES的写入流程源码,详情见【Elasticsearch源码】写入源码分析。
Elasticsearch(ES)的查询接口具有分布式的数据检索、聚合分析能力,数据检索能力用于支持全文检索、日志分析等场景,如Github平台上的代码搜索、基于ES的各类日志分析服务等;聚合分析能力用于支持指标分析、APM等场景,如监控场景、应用的日活/留存分析等。
本文基于6.7.1版本,主要分析ES的分布式执行框架及查询主体流程,探究ES如何实现分布式查询、数据检索、聚合分析等能力。
2 查询基本流程
图片来自官网,源代码取自6.7.1版本:
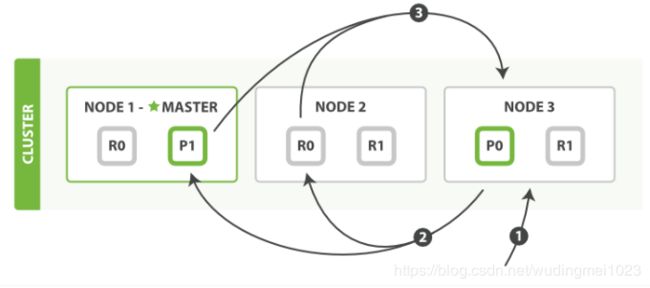
- 客户端可以将查询发送到任意节点,接收到查询的节点会作为该查询的协调节点;
- 协调节点解析查询语句,向对应数据分片分发查询子任务;
- 各个分片将本地的查询结果返回给协调节点,进过协调节点汇聚后返回给客户端。
如图所示:客户端将请求发送到Node3节点,Node3节点进行查询解析之后,将请求分发到0号和1号分片所在的Node2和Node1,两者再讲各地分片的查询数据返回至Node3,最终Node3进行汇聚,然后返回客户端。
从实际的实现来看,协调节点的处理逻辑远比上述流程复杂,不同类型的查询对应的协调节点的处理逻辑有一定的差别。
下面先来介绍下常见的2类查询,在之前的版本有3类查询:DFS_QUERY_THEN_FETCH、QUERY_AND_FETCH和QUERY_THEN_FETCH,5.3版本之后,QUERY_AND_FETCH已经被移除。
2.1 DFS_QUERY_THEN_FETCH
搜索里面有一种算分逻辑是根据TF(Term Frequency)和DF(Document Frequency)计算基础分,但是Elasticsearch中查询的时候,是在每个Shard中独立查询的,每个Shard中的TF和DF也是独立的,虽然在写入的时候通过_routing保证Doc分布均匀,但是没法保证TF和DF均匀,那么就有会导致局部的TF和DF不准的情况出现,这个时候基于TF、DF的算分就不准。
为了解决这个问题,Elasticsearch中引入了DFS查询,比如DFS_query_then_fetch,会先收集所有Shard中的TF和DF值,然后将这些值带入请求中,再次执行query_then_fetch,这样算分的时候TF和DF就是准确的。
2.2 QUERY_THEN_FETCH
ES默认的查询方式,在查询的过程中,分为query和fetch两个阶段:
Query Phase: 进行分片粒度的数据检索和聚合,注意此轮调度仅返回文档id集合,并不返回实际数据。
协调节点:解析查询后,向目标数据分片发送查询命令。
数据节点:在每个分片内,按照过滤、排序等条件进行分片粒度的文档id检索和数据聚合,返回结果。
Fetch Phase: 生成最终的检索、聚合结果。
协调节点:归并Query Phase的结果,得到最终的文档id集合和聚合结果,并向目标数据分片发送数据抓取命令。
数据节点:按需抓取实际需要的数据内容。
3 查询源码流程分析
这里以默认的QUERY_THEN_FETCH查询为例:
3.1 查询请求入口
这一块逻辑和所有的ES请求的处理是类似的,可以参考bulk请求的过程。以Rest请求为例:

Rest分发由RestController模块完成。在ES节点启动时,会加载所有内置请求的Rest Action,并把对应请求的Http路径和Rest Action作为
public RestSearchAction(Settings settings, RestController controller) {
super(settings);
controller.registerHandler(GET, "/_search", this);
controller.registerHandler(POST, "/_search", this);
controller.registerHandler(GET, "/{index}/_search", this);
controller.registerHandler(POST, "/{index}/_search", this);
controller.registerHandler(GET, "/{index}/{type}/_search", this);
controller.registerHandler(POST, "/{index}/{type}/_search", this);
}
Rest层用于解析Http请求参数,RestRequest解析并转化为SearchRequest,然后再对SearchRequest做处理,这块的逻辑在prepareRequest方法中,部分代码如下:
public RestChannelConsumer prepareRequest(final RestRequest request, final NodeClient client) throws IOException {
//根据RestRequest构建SearchRequest
SearchRequest searchRequest = new SearchRequest();
IntConsumer setSize = size -> searchRequest.source().size(size);
request.withContentOrSourceParamParserOrNull(parser ->
parseSearchRequest(searchRequest, request, parser, setSize));
//处理SearchRequest
return channel -> client.search(searchRequest, new RestStatusToXContentListener<>(channel));
}
NodeClient在处理SearchRequest请求时,会将请求的action转化为对应Transport层的action,然后再由Transport层的action来处理SearchRequest,action转化的代码如下:
public < Request extends ActionRequest,
Response extends ActionResponse
> Task executeLocally(GenericAction<Request, Response> action, Request request, TaskListener<Response> listener) {
return transportAction(action).execute(request, listener);
}
private < Request extends ActionRequest,
Response extends ActionResponse
> TransportAction<Request, Response> transportAction(GenericAction<Request, Response> action) {
.....
//actions是个action到transportAction的Map,这个映射关系是在节点启动时初始化的
TransportAction<Request, Response> transportAction = actions.get(action);
......
return transportAction;
}
然后进入TransportAction,TransportAction#execute(Request request, ActionListener listener) -> TransportAction#execute(Task task, Request request, ActionListener listener) -> TransportAction#proceed(Task task, String actionName, Request request, ActionListener listener)。TransportAction会调用一个请求过滤链来处理请求,如果相关的插件定义了对该action的过滤处理,则先会执行插件的处理逻辑,然后再进入TransportAction的处理逻辑,过滤链的处理逻辑如下:
public void proceed(Task task, String actionName, Request request, ActionListener<Response> listener) {
int i = index.getAndIncrement();
try {
if (i < this.action.filters.length) {
//应用插件的逻辑
this.action.filters[i].apply(task, actionName, request, listener, this);
} else if (i == this.action.filters.length) {
//执行TransportAction的逻辑
this.action.doExecute(task, request, listener);
} else {
......
}
} catch(Exception e) {
.....
}
}
对于Search请求,这里的TransportAction对应的具体对象是TransportSearchAction的实例,到此,Rest层转化为Transport层的流程完成,下节将详细介绍TransportSearchAction的处理逻辑。
3.1 查询请求分发
代码入口:TransportSearchAction#doExecute。
首先解析获取了查询涉及的具体索引列表,包括远程集群和本地集群(远程集群用于跨集群访问):
final ClusterState clusterState = clusterService.state();
//获取远程集群indices列表
final Map<String, OriginalIndices> remoteClusterIndices = remoteClusterService.groupIndices(searchRequest.indicesOptions(),
searchRequest.indices(), idx -> indexNameExpressionResolver.hasIndexOrAlias(idx, clusterState));
//获取本地集群indices列表
OriginalIndices localIndices = remoteClusterIndices.remove(RemoteClusterAware.LOCAL_CLUSTER_GROUP_KEY);
if (remoteClusterIndices.isEmpty()) {
executeSearch((SearchTask)task, timeProvider, searchRequest, localIndices, Collections.emptyList(),
(clusterName, nodeId) -> null, clusterState, Collections.emptyMap(), listener,
clusterState.getNodes().getDataNodes().size(), SearchResponse.Clusters.EMPTY);
} else {
//远程集群的处理逻辑
.....
}
然后进入executeSearch方法,构造目的shard列表,我们可以看到:
- red状态下可以查询;
- 默认需要查询目标索引的所有分片;
- 默认采用QUERY_THEN_FETCH查询方式;
- 并发查询分片数最大256;
- 默认是不开启请求缓存的。
private void executeSearch(....) {
// red状态也可以查询
clusterState.blocks().globalBlockedRaiseException(ClusterBlockLevel.READ);
......
// 结合routing信息、preference信息,构造目的shard列表
GroupShardsIterator<ShardIterator> localShardsIterator = clusterService.operationRouting().searchShards(clusterState,
concreteIndices, routingMap, searchRequest.preference(), searchService.getResponseCollectorService(), nodeSearchCounts);
GroupShardsIterator<SearchShardIterator> shardIterators = mergeShardsIterators(localShardsIterator, localIndices,
searchRequest.getLocalClusterAlias(), remoteShardIterators);
.....
if (shardIterators.size() == 1) {
// 只有一个分片的时候,默认就是QUERY_THEN_FETCH,不存在评分不一致的问题
searchRequest.searchType(QUERY_THEN_FETCH);
}
if (searchRequest.allowPartialSearchResults() == null) {
// 用户未定义首选项,采用默认方式
searchRequest.allowPartialSearchResults(searchService.defaultAllowPartialSearchResults());
}
if (searchRequest.isSuggestOnly()) {
// 默认是没有开启请求缓存的
searchRequest.requestCache(false);
switch (searchRequest.searchType()) {
case DFS_QUERY_THEN_FETCH:
// 默认情况下DFS_QUERY_THEN_FETCH会转化成QUERY_THEN_FETCH
searchRequest.searchType(QUERY_THEN_FETCH);
break;
}
}
.....
// 最大并发分片数,最大是256:Math.min(256, Math.max(nodeCount, 1)* IndexMetaData.INDEX_NUMBER_OF_SHARDS_SETTING.getDefault(Settings.EMPTY))
setMaxConcurrentShardRequests(searchRequest, nodeCount);
boolean preFilterSearchShards = shouldPreFilterSearchShards(searchRequest, shardIterators);
// 生成查询请求的调度类searchAsyncAction并启动调度执行
searchAsyncAction(task, searchRequest, shardIterators, timeProvider, connectionLookup, clusterState.version(),
Collections.unmodifiableMap(aliasFilter), concreteIndexBoosts, routingMap, listener, preFilterSearchShards, clusters).start();
}
然后进入了SearchPhase的实现类InitialSearchPhase的run方法:基于shard进行遍历,向shard所在节点发送查询请求,如果列表中有N个shard位于同一个节点,则向其发送N次请求,并不会把请求合并成一个。
public final void run() throws IOException {
.....
if (shardsIts.size() > 0) {
// 最大分片请求数可以通过max_concurrent_shard_requests参数配置,6.5之后版本新增参数
int maxConcurrentShardRequests = Math.min(this.maxConcurrentShardRequests, shardsIts.size());
....
for (int index = 0; index < maxConcurrentShardRequests; index++) {
final SearchShardIterator shardRoutings = shardsIts.get(index);
// 执行shard级请求
performPhaseOnShard(index, shardRoutings, shardRoutings.nextOrNull());
}
}
}
shardsIts是本次查询涉及的所有分片,shardRoutings.nextOrNull()从某个分片中主或者所有副本中选一个。
接下一篇:查询源码分析(二)。