信息论中熵 联合熵 条件熵 相对熵(KL散度)(交叉熵) 互信息 (信息增益)的定义 及关联
目录标题
- 熵(Entropy)的理论知识
- 定义
- 例子
- 1. 均匀分布
- 2. 非均匀分布
- 联合熵(joint entropy)
- 条件熵(conditional entropy)
- 相对熵(relative entropy)或(Kullback-Leibler)KL散度
- 交叉熵(cross entropy)
- 分类问题损失函数
- 互信息(mutual entropy)
- 信息增益(information gain)
- 熵之间的关系
- 链式法则
- 熵的性质
- 多变量分布熵
- 条件互信息(conditional mutual information)
- 条件相对熵(conditional relative entropy)
- 多变量链式法则
- 熵的链式法则
- 互信息的链式法则
- 相对熵的链式法则
- 参考
传送门:信息熵在tensorflow2.*中实现参考博文
熵(Entropy)的理论知识
定义
在信息论中,熵被定义为随机变量的平均不确定度的度量。也是平均意义上描述随机变量所需的信息量的度量。
设 X X X是一个离散型随机变量,其字母表(即概率论中的取值空间)为 χ \chi χ。概率密度函数 p ( x ) = P r ( X = x ) , x ∈ χ p(x)=Pr(X=x), x\in\chi p(x)=Pr(X=x),x∈χ, 则一个离散随机变量 X X X的熵 H ( X ) H(X) H(X)定义为
H ( X ) = − ∑ p ( x ) log 2 p ( x ) H(X)=-\sum p(x)\log_{2} p(x) H(X)=−∑p(x)log2p(x)
表达式中对数函数以2为底,熵的量纲为比特。在平均意义下,熵是为了描述随机变量 X X X所需的比特数。
数学期望表达式
如果 X ∼ p ( x ) X \sim p(x) X∼p(x),随机变量 g ( x ) g(x) g(x)的期望值可记作:
E p g ( x ) = ∑ x ∈ χ g ( x ) p ( x ) E_{p} g(x) =\sum_{x\in\chi}g(x)p(x) Epg(x)=x∈χ∑g(x)p(x)
当 g ( x ) = l o g 1 p ( X ) g(x)=log \frac{1}{p(X)} g(x)=logp(X)1时, H ( X ) H(X) H(X)可以表示位随机变量 l o g 1 p ( X ) log \frac{1}{p(X)} logp(X)1的期望值,即
H ( X ) = E p l o g 1 p ( X ) H(X)=E_{p} log \frac{1}{p(X)} H(X)=Eplogp(X)1
例子
1. 均匀分布
一个服从均匀分布且有32种可能结果的随机变量,需要用多长的字符串描述这个随机变量?
首先易得使用二进制需要 2 5 = 32 2^5=32 25=32,即5字节的长度。
由熵公式可得, H ( X ) = − ∑ x = 1 32 p ( x ) l o g ( p x ) = − ∑ x = 1 32 1 32 l o g 1 32 = 5 H(X)=-\sum_{x=1}^{32} p(x)log(px)=-\sum_{x=1}^{32} \frac{1}{32}log\frac{1}{32}=5 H(X)=−∑x=132p(x)log(px)=−∑x=132321log321=5比特,恰好等于描述32的字节长度
2. 非均匀分布
书中举了一个实际的例子,假定一个有8匹马的比赛,8匹马的获胜概率分别位 ( 1 4 , 1 8 , 1 16 , 1 32 , 1 64 , 1 64 , 1 64 , 1 64 ) (\frac{1}{4}, \frac{1}{8}, \frac{1}{16}, \frac{1}{32}, \frac{1}{64}, \frac{1}{64}, \frac{1}{64},\frac{1}{64}) (41,81,161,321,641,641,641,641)。现在需要在马赛比赛结束的第一时刻把消息传播出去,并使用传播所需的信息最小。
有两种策略:
- 对所有参赛的马按照
相同策略进行编码
此时8匹马需要使用 2 3 = 8 2^3=8 23=8,即使用常规的二进制编码方式从000到111进行编码。因此,对任何一匹马都选哟3字节长度。 可能性较大的马使用较短的编码
这样对应8匹马分别使用:0,10,110,1110, 111100,111101,111110,111111的一组二元字符串进行表示的话。对每一匹马的编码长度乘以对应概率值求和,刚好等于2,小于方法一中的3字节长度。
- 策略一中为什么不使用一位和两位的字符?
同时,由求熵公式可得
H ( X ) = − 1 2 l o g 1 2 − 1 4 l o g 1 4 − 1 8 l o g 1 8 − 1 16 l o g 1 16 − 1 32 l o g 1 32 − 1 64 l o g 1 64 − 1 64 l o g 1 64 − 1 64 l o g 1 64 − 1 64 l o g 1 64 = 2 H(X)=- \frac{1}{2}log\frac{1}{2}- \frac{1}{4}log\frac{1}{4}- \frac{1}{8}log\frac{1}{8}- \frac{1}{16}log\frac{1}{16}- \frac{1}{32}log\frac{1}{32}- \\\frac{1}{64}log\frac{1}{64}- \frac{1}{64}log\frac{1}{64}- \frac{1}{64}log\frac{1}{64}- \frac{1}{64}log\frac{1}{64}=2 H(X)=−21log21−41log41−81log81−161log161−321log321−641log641−641log641−641log641−641log641=2
可见第二种方式得到的平均比特数正好等于熵
如果大家和我一样还不太理解可以参看信息熵和计算公式介绍视频
关键点需要理解信息和熵的定义
| 信息 | 熵 |
|---|---|
| 描述一个随机事件所需的字节数 | 随机事件不确定性的度量(单位字节) |
| 获取有效信息,消除随机事件熵减少 | 对随机事件进行描述所需要的编码长度 |
联合熵(joint entropy)
对于服从联合分布为 p ( x , y ) p(x,y) p(x,y)的一对离散随机变量 ( X , Y ) (X,Y) (X,Y),其联合熵 H ( X , Y ) H(X,Y) H(X,Y)定义为
H ( X , Y ) = − ∑ x ∈ χ ∑ y ∈ y p ( x , y ) l o g p ( x , y ) H(X,Y)=-\sum_{x\in\chi}\sum_{y\in y}p(x,y)logp(x,y) H(X,Y)=−x∈χ∑y∈y∑p(x,y)logp(x,y)
亦可以表示为
H ( X , Y ) = − E l o g p ( x , y ) H(X,Y)=-Elogp(x,y) H(X,Y)=−Elogp(x,y)
条件熵(conditional entropy)
已知随机变量X的条件下,随机变量 Y 的不确定性
H ( Y / X ) = ∑ x ∈ χ p ( x ) H ( Y ∣ X = x ) = − ∑ x ∈ χ p ( x ) ∑ y ∈ Y p ( y ∣ x ) l o g p ( y ∣ x ) = − ∑ x ∈ χ ∑ y ∈ Y p ( x , y ) l o g p ( y ∣ x ) = − E l o g p ( Y ∣ X ) \begin{aligned} H(Y/X)&=\sum_{x \in \chi}p(x)H(Y|X=x)\\&=-\sum_{x \in \chi}p(x)\sum_{y \in Y}p(y|x)logp(y|x)\\&=-\sum_{x \in \chi}\sum_{y \in Y}p(x,y)logp(y|x)\\&=-Elogp(Y|X) \end{aligned} H(Y/X)=x∈χ∑p(x)H(Y∣X=x)=−x∈χ∑p(x)y∈Y∑p(y∣x)logp(y∣x)=−x∈χ∑y∈Y∑p(x,y)logp(y∣x)=−Elogp(Y∣X)
相对熵(relative entropy)或(Kullback-Leibler)KL散度
两个随机分布之间距离的度量。
例如,已知随机变量的真实分布为 p p p,可以构造平均描述长度为 H ( p ) H(p) H(p)的编码。但是,如果使用针对分布 q q q的编码,那么在平均意义上就需要 H ( p ) + D ( p ∣ ∣ q ) H(p)+D(p||q) H(p)+D(p∣∣q)比特的编码来描述这个随机变量
- q的熵一定大于p的意思?
D ( p ∣ ∣ q ) = ∑ x ∈ χ p ( x ) l o g p ( x ) q ( x ) = E p l o g p ( x ) q ( x ) D(p||q)=\sum_{x \in \chi}p(x)log \frac{p(x)}{q(x)}=E_{p}log \frac{p(x)}{q(x)} D(p∣∣q)=x∈χ∑p(x)logq(x)p(x)=Eplogq(x)p(x)
交叉熵(cross entropy)
两个概率分布间的差异性信息
在深度学习中最常使用 交叉熵作为损伤函数
H ( p , q ) = − ∑ x ∈ χ p ( x ) l o g ( q ( x ) ) H(p,q)=-\sum_{x \in \chi}p(x)log(q(x)) H(p,q)=−x∈χ∑p(x)log(q(x))
由相对熵的表达式
D ( p ∣ ∣ q ) = ∑ x ∈ χ p ( x ) l o g p ( x ) q ( x ) = ∑ x ∈ χ p ( x ) l o g ( p ( x ) ) − ∑ x ∈ χ p ( x ) l o g ( q ( x ) ) = − H ( p ( X ) ) + H ( p , q ) \begin{aligned} D(p||q)&=\sum_{x \in \chi}p(x)log \frac{p(x)}{q(x)}\\&=\sum_{x \in \chi}p(x)log(p(x))-\sum_{x \in \chi}p(x)log(q(x))\\&=-H(p(X))+H(p,q) \end{aligned} D(p∣∣q)=x∈χ∑p(x)logq(x)p(x)=x∈χ∑p(x)log(p(x))−x∈χ∑p(x)log(q(x))=−H(p(X))+H(p,q)
可得,交叉熵 H ( p , q ) H(p,q) H(p,q)恰好等于 H ( p ) + D ( p ∣ ∣ q ) H(p)+D(p||q) H(p)+D(p∣∣q)。当 H ( p ) = 0 H(p)=0 H(p)=0时,相对熵就等于相对熵。即两者都可以表示两个随机分布的差异性,交叉熵数值包含一个真实(参考)随机分布p的熵
分类问题损失函数
对于 Y t r u e Y_{true} Ytrue由于进行One-hot编码后是一个001000的分布,故 H ( p ( X ) ) H(p(X)) H(p(X))等于0,即 D ( p ∣ ∣ q ) = H ( p , q ) D(p||q)=H(p,q) D(p∣∣q)=H(p,q)。损失函数 H ( p , q ) H(p,q) H(p,q)减少的意义是 Y t r u e Y_{true} Ytrue与 Y p r e d Y_{pred} Ypred分布之间的差异性逐渐减少,或距离越来越小,或采用相同的编码方式不需要额外的信息量进行描述。
互信息(mutual entropy)
一个随机变量包含另一个随机变量信息量的度量
给定另一随机变量条件下,原随机变量不确定度的缩减量
互信息 I ( X ; Y ) I(X;Y) I(X;Y)等于联合概率密度函数 p ( x , y ) p(x,y) p(x,y)和边界概率密度函数 p ( x ) p ( y ) p(x)p(y) p(x)p(y)乘积之间的相对熵
I ( X ; Y ) = ∑ x ∈ χ ∑ y ∈ Y p ( x , y ) l o g p ( x , y ) p ( x ) p ( y ) = D ( ( p ( x , y ) ∣ ∣ p ( x ) p ( y ) ) ) = E p ( x , y ) l o g p ( X , Y ) p ( X ) p ( Y ) \begin{aligned} I(X;Y)&=\sum_{x \in \chi} \sum_{y \in Y}p(x,y)log\frac{p(x,y)}{p(x)p(y)}\\&=D((p(x,y)||p(x)p(y)))\\&=E_{p(x,y)}log\frac{p(X,Y)}{p(X)p(Y)} \end{aligned} I(X;Y)=x∈χ∑y∈Y∑p(x,y)logp(x)p(y)p(x,y)=D((p(x,y)∣∣p(x)p(y)))=Ep(x,y)logp(X)p(Y)p(X,Y)
信息增益(information gain)
表达式与互信息相同,熵减去条件熵。但实际表达意义存在一定差别。
I G ( X ; Y ) = H ( X ) − H ( X ∣ Y ) IG(X;Y)=H(X)-H(X|Y) IG(X;Y)=H(X)−H(X∣Y)
互信息中Y表示事件,信息增益Y表示分类方式
互信息里面的Y,用 H ( Y ) H(Y) H(Y)表示,可以通过统计测量概率,并用信息熵公式计算。
但是增益里面的Y,由于是一种分类方式,它的熵要是直接计算,信息论里面没有介绍。
信息增益是描述前后两种不同状态的信息熵变化,即确定性的增加量,分类(决策树)本质就是将一个系统中各种元素之间的分类关系(X,Y,Z,…)确定下来。H(X)表示分类前的熵,H(X|Y)表示分类后的熵
熵之间的关系
链式法则
H ( X , Y ) = H ( X ) + H ( Y ∣ X ) H(X,Y)=H(X)+H(Y|X) H(X,Y)=H(X)+H(Y∣X)
联合熵等于已知条件X的熵加已知X的条件熵。
联合熵与条件熵的差等于已知条件的熵值
I ( X ; Y ) = H ( X ) − H ( X ∣ Y ) = H ( Y ) − H ( Y ∣ X ) I(X;Y)=H(X)-H(X|Y)=H(Y)-H(Y|X) I(X;Y)=H(X)−H(X∣Y)=H(Y)−H(Y∣X)
I ( X ; Y ) = H ( X ) − H ( X ∣ Y ) I(X;Y)=H(X)-H(X|Y) I(X;Y)=H(X)−H(X∣Y)表示在给出Y信息的条件下,X的不确定度的缩减量
将链式法则 H ( X ∣ Y ) = H ( X , Y ) − H ( Y ) H(X|Y)=H(X,Y)-H(Y) H(X∣Y)=H(X,Y)−H(Y)代入可得
I ( X ; Y ) = H ( X ) + H ( Y ) − H ( Y , X ) I(X;Y)=H(X)+H(Y)-H(Y,X) I(X;Y)=H(X)+H(Y)−H(Y,X)
互信息等于各自熵的和减去联合熵
至此所有两个随机变量之间的熵的关系可由下图表示出来

熵的性质
- H ( X ) ≥ 0 H(X)\geq0 H(X)≥0
- H b ( x ) = ( l o g b a ) H a ( X ) H_{b}(x)=(log_{b}a)H_{a}(X) Hb(x)=(logba)Ha(X)
- H ( X ∣ Y ) ≤ H ( X ) H(X|Y)\le H(X) H(X∣Y)≤H(X)
条件作用使熵减少 - H ( X 1 , X 2 , . . . , X n ) ≤ ∑ i = 1 n H ( X i ) H(X_1,X_2,...,X_n)\le\sum_{i=1}^{n}H(X_i) H(X1,X2,...,Xn)≤∑i=1nH(Xi)
- H ( X ) ≤ l o g ∣ χ ∣ H(X)\le log|\chi| H(X)≤log∣χ∣
- H ( p ) H(p) H(p)关于p是凹函数
多变量分布熵
条件互信息(conditional mutual information)
随机变量X和Y在给定随机变量Z时的条件互信息(conditional mutual information)
I ( X ; Y ∣ Z ) = H ( X ∣ Z ) − H ( X ∣ Y , Z ) = E p ( x , y , z ) l o g p ( X , Y ∣ Z ) p ( X ∣ Z ) p ( Y ∣ Z ) \begin{aligned} I(X;Y|Z)&=H(X|Z)-H(X|Y,Z)\\&=E_{p(x,y,z)}log\frac{p(X,Y|Z)}{p(X|Z)p(Y|Z)} \end{aligned} I(X;Y∣Z)=H(X∣Z)−H(X∣Y,Z)=Ep(x,y,z)logp(X∣Z)p(Y∣Z)p(X,Y∣Z)
条件相对熵(conditional relative entropy)
D ( p ( y ∣ x ) ∣ ∣ q ( y ∣ x ) ) = ∑ x p ( x ) ∑ y p ( y ∣ x ) l o g p ( y ∣ x ) q ( y ∣ x ) = E p ( x , y ) l o g p ( Y ∣ X ) q ( Y ∣ X ) \begin{aligned} D(p(y|x)||q(y|x))&=\sum_{x}p(x)\sum_{y}p(y|x)log\frac{p(y|x)}{q(y|x)}\\&=E_{p(x,y)}log\frac{p(Y|X)}{q(Y|X)} \end{aligned} D(p(y∣x)∣∣q(y∣x))=x∑p(x)y∑p(y∣x)logq(y∣x)p(y∣x)=Ep(x,y)logq(Y∣X)p(Y∣X)
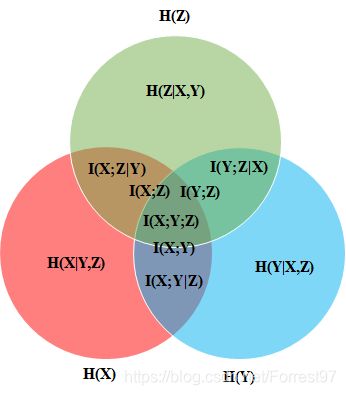
多变量链式法则
熵的链式法则
H ( X , Y ) = H ( X ) + H ( Y ∣ X ) H ( X , Y , Z ) = H ( X ) + H ( Y ∣ X ) + H ( Z ∣ X , Y ) = H ( X ) + H ( Y , Z ∣ X ) H(X,Y)=H(X)+H(Y|X)\\ H(X,Y,Z)=H(X)+H(Y|X)+H(Z|X,Y)=H(X)+H(Y,Z|X) H(X,Y)=H(X)+H(Y∣X)H(X,Y,Z)=H(X)+H(Y∣X)+H(Z∣X,Y)=H(X)+H(Y,Z∣X)
一般式:
H ( X 1 , X 2 , . . . , X n ) = ∑ i = 1 n H ( X i ∣ X i − 1 , . . . , X 1 ) H(X_1,X_2,...,X_n)=\sum_{i=1}^{n}H(X_i|X_{i-1},...,X_1) H(X1,X2,...,Xn)=i=1∑nH(Xi∣Xi−1,...,X1)
互信息的链式法则
I ( X 1 , X 2 , . . . , X n ; Y ) = ∑ i = 1 n I ( X i ; Y ∣ X i − 1 , . . . , X 1 ) I(X_1,X_2,...,X_n;Y)=\sum_{i=1}^{n}I(X_i;Y|X_{i-1},...,X_1) I(X1,X2,...,Xn;Y)=i=1∑nI(Xi;Y∣Xi−1,...,X1)
相对熵的链式法则
一对随机变量的两个联合分布之间的相对熵可以展开为相对熵和条件相对熵之和
D ( p ( x , y ) ∣ ∣ q ( x , y ) ) = D ( p ( x ) ∣ ∣ q ( x ) ) + D ( p ( y ∣ x ) ∣ ∣ q ( y ∣ x ) ) D(p(x,y)||q(x,y))=D(p(x)||q(x))+D(p(y|x)||q(y|x)) D(p(x,y)∣∣q(x,y))=D(p(x)∣∣q(x))+D(p(y∣x)∣∣q(y∣x))
参考
《Elements of information Theory》