OpenTSDB使用
一、OpenTSDB原理
随着互联网、尤其是物联网的发展,我们需要把各种类型的终端实时监测、检查与分析设备所采集、产生的数据记录下来,在有时间的坐标中将这些数据连点成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测和预警。
这些数据的典型特点是:产生频率快(每一个监测点一秒钟内可产生多条数据)、严重依赖于采集时间(每一条数据均要求对应唯一的时间)、测点多信息量大(实时监测系统均有成千上万的监测点,监测点每秒钟都产生数据,每天产生几十GB的数据量)。
基于时间序列数据的特点,关系型数据库无法满足对时间序列数据的有效存储与处理,因此迫切需要一种专门针对时间序列数据来做优化处理的数据库系统。
时序数据库就是存放时序数据的数据库,并且需要支持时序数据的快速写入、持久化、多纬度的聚合查询等基本功能。对比传统数据库仅仅记录了数据的当前值,时序数据库则记录了所有的历史数据。同时时序数据的查询也总是会带上时间作为过滤条件。
时序数据,股票的变化趋势、温度的变化趋势、系统某个指标的变化趋势……其实都是时序数据,就是每个时间点上纪录一条数据。 关于数据的存储,我们最熟悉的就是mysql了,但是想想看,每5分钟存储一个点,一天288个点,一年就10万+,这还是单个维度,往往在实际应用中维度会非常多,比如股票交易所,成千上万支股票,每天所有股票数据就可能超过百万条,如果还得支持历史数据查询,mysql是远远扛不住的,必然要考虑分布式存储,最好的选择就是Hbase了,事实上业内基本上也是这么做的。
Hbase可通过加机器的水平扩展迅速增加读写能力,非常适合存储海量的数据,但是它并不是关系数据库,无法进行类似mysql那种select、join等操作,取而代之的只有非常简单的Get和Scan两种数据查询方式。总之,你可以通过Get获取到hbase里的一行数据,通过Scan来查询其中RowKey在某个范围里的一批数据。如此简单的查询方式虽然让hbase变得简单易用, 但也限制了它的使用场景。针对时序数据,只有get和scan远远满足不了你的需求。
这个时候OpenTSDB就应运而生。 首先它做了数据存储的优化,可以大幅度提升数据查询的效率和减少存储空间的使用。其次它基于hbase做了常用时序数据查询的API,比如数据的聚合、过滤等。另外它也针对数据热度倾斜做了优化。
1、OpenTSDB相关介绍
参考:Opentsdb 官方文档
时间序列数据库:主要用来存储时间序列数据(数据格式里包含timestamp字段的数据),常常用来做监控预警数据的存储。
OpenTSDB是基于HBase存储时间序列数据的一个开源数据库,但只是一个HBase的应用而已。也即是在HBase之上加了一层外壳,用于更好的处理时序数据库,真实的数据存储还是在HBase。最新db-engines.com排行统计。
- 特点:
- 写多于读:95%-99%的操作都是写操作
- 顺序写:实时数据写入,多以追加的方式
- 很少更新:基本上不更新
- 区块删除:删除总是会删除一段时间的数据
- 毫无遗漏的接收并存储大量的时间序列数据。
- 主要用做监控系统;譬如收集大规模集群(包括网络设备、操作系统、应用程序)的监控数据并进行存储,查询。
-
存储
- 无需转换,写的是什么数据存的就是什么数据
- 时序数据以毫秒的精度保存
- 永久保留原始数据
-
扩展性
- 运行在Hadoop 和 HBase之上
- 可扩展到每秒数百万次写入
- 可以通过添加节点扩容
-
读能力
- 直接通过内置的GUI来生成图表
- 还可以通过HTTP API查询数据
- 另外还可以使用开源的前端与其交互
2、OpenTSDB架构原理
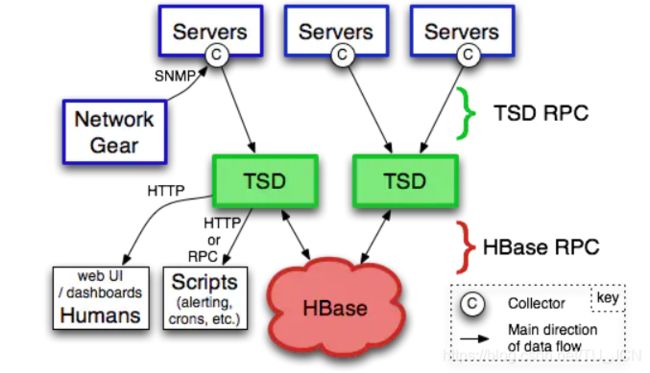
- Servers:就是服务器了,上面的C就是指Collector,可以理解为OpenTSDB的agent,通过Collector收集数据,推送数据;
- TSD:TSD是对外通信的无状态的服务器,Collector可以通过TSD简单的RPC协议推送监控数据;另外TSD还提供了一个web UI页面供数据查询;另外也可以通过脚本查询监控数据,对监控数据做报警
- HBase:TSD收到监控数据后,是通过AsyncHbase这个库来将数据写入到HBase;AsyncHbase是完全异步、非阻塞、线程安全的Hbase客户端,使用更少的线程、锁以及内存,可以提供更高的吞吐量,特别对于大量的写操作。
OpenTSDB是一个时间序列数据库,由一个 Time Series Daemon (TSD) 和一系列命令行实用程序组成。与OpenTSDB交互主要通过运行一个或者多个 TSD 来实现。每个 TSD 是独立的。没有master,没有共享状态,可以运行尽可能多的 TSD 来处理工作负载。
每个 TSD 使用开源数据库 HBase 或托管Google Bigtable服务来存储和检索时间序列数据。数据模式针对类似时间序列的快速聚合进行了高度优化,以最大限度的减少存储空间。
TSD 的用户不需要直接访问底层仓库。直接通过telnet协议,HTTP API 或者简单的内置 GUI 与 TSD 进行通信,所有的通信都发生在同一个端口上(TSD 通过查看接收到的前几个字节来计算出客户端的协议)
3、OpenTSDB存储原理
譬如,假设我们采集1个服务器(hostname=qatest)的CPU使用率,发现该服务器在21:00的时候,CPU使用率达到99%
- 1)Metric:即平时我们所说的监控项。譬如上面的CPU使用率
- 2)Tags:就是一些标签,在OpenTSDB里面,Tags由tagk和tagv组成,即tagk=takv。标签是用来描述Metric的,譬如上面为了标记是服务器A的CpuUsage,tags可为hostname=qatest
- 3)Value:一个Value表示一个metric的实际数值,譬如上面的99%
- 4)Timestamp:即时间戳,用来描述Value是什么时候的;譬如上面的21:00
Data Point:即某个Metric在某个时间点的数值。Data Point包括以下部分:Metric、Tags、Value、Timestamp。上面描述的服务器在21:00时候的cpu使用率,就是1个DataPoint,保存到OpenTSDB的,就是无数个DataPoint。
譬如,保存这样的1个DataPoint:
metric:proc.loadavg.1m
timestamp:1234567890
value:0.42
tags:host=web42,pool=static
Hbase去存,可能就是:RowKey=metric|timestamp|value|host=web42|pool=static,Column=v,Value=0.42
OpenTSDB使用HBase存储,核心的存储,是有两张表**,tsdb和tsdb-uid**,
tsdb表:保存数据;tsdb-uid表:保存的一些metric,tagk,tagv的映射关系。
(1) tsdb表

1)RowKey的设计
RowKey其实和上面的metric|timestamp|value|host=web42|pool=static类似;
但是区别是,OpenTSDB为了节省存储空间,将每个部分都做了映射。
在OpenTSDB里面有这样的映射,metric–>3字节整数、tagk–>3字节整数、tagv–>3字节整数
上图的映射关系为,proc.loadavg.1m–>052、host–>001、web42–>028、pool–>047、static–>001
若每秒存储一个数据点,每天就有86400个数据点,在hbase里就意味着86400行的数据,不仅浪费存储空间,而且还查起来慢,
OpenTSDB做了数据压缩上的优化,多行一列 转 一行多列,一行多列转一行一列。
数据开始写入时其实OpenTSDB还是一行一个数据点,如果用户开启了数据压缩的选项,OpenTSDB会在一个小时数据写完,或者查询某个小时数据时对其做多行转一行的数据压缩,压缩后那些独立的点数据就会被删除以节省存储空间。
多行一列 转 一行多列
原始数据可能长这样,一个小时总共有3600行的数据。
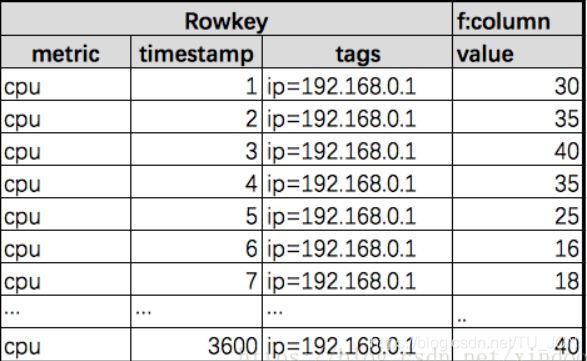
Opentsdb会将一个小时的数据合并到一个Rowkey里,相应的Rowkey里的timestamp也会归一化到哪个小时的时间戳。如下图。

通过这样转换后一个Rowkey就能查到一个小时的数据,一天24个Rowkey也就够了。在hbase中Qualifier是个两个Bytes的整数(如果是毫秒级数据是4个bytes),value是4-8 bytes的数值。
一行多列转一行一列
在2.2版本,opentsdb进一步对数据存储做了优化,把每个Row里的3600列合并成了一列,存储格式如下。
就是位移量+值拼接在一起,opentsdb在这里并不要求这里的offset有序,查询的时候才会被排序。
2)column的设计
为了方便后期更进一步的节省空间。OpenTSDB将一个小时的数据,保存在一行里面。
所以上面的timestamp1234567890,会先模一下小时,得出1234566000,然后得到的余数为1890,表示的是它是在这个小时里面的第1890秒;
然后将1890作为column name,而0.42即为column value
(2) tsdb-uid表
opentsdb在构建Rowkey的时候并不是直接用原始值的,而是将metric、timesta、tagk、tagv分别用了一个3字节的uid做了替代(3字节意味着最多1600多万uid,大多数情况下应该够用了),可以减少Rowkey的存储空间。
所以这里需要有个表来做uid和真实值之间的转换,这个表就是tsdb-uid表。

tsdb-uid表中有两个列族,分别是uid-name的映射(name famlily),name-uid的映射(uid famliy)。另外还有一行特殊的数据,就是uid已分配情况记录表。
name-uid (name family)
Rowkey: name
Qualifiers: metric, tagk, tagv
value: name实际对应的uid值。
uid-name(id family)
Rowkey: uid
Qualifiers: metric, tagk, tagv
value: uid对应的实际name值
UID 分配行
这是一行非常特殊的数据,Rowkey为0x00,里面保存了metric、tagk、tagv已分配uid的最大值,每次新分配一个uid就会对其中相应的值增加1,这里用了hbase的原子操作,就是为了确保uid不重复。
(3) 数据查询的封装
OpenTSDB对hbase的读做很多的封装,方便实现更复杂切灵活的查询功能,我们来看下读接口的查询参数就能一窥究竟。
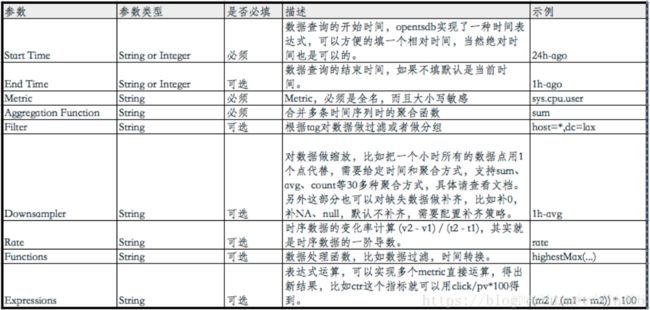
OpenTSDB在从底层hbase拿到数据后数据处理流程如下。
Filtering 过滤
Grouping 分组
Downsampling 数据缩放
Interpolation 数据改写
Aggregation 聚合
Rate Conversion 计算斜率
Functions 执行函数
Expressions 表达式运算
(4) 数据热点的解决
用hbase存过数据的人可能会知道,大多数时候数据分布是存在严重倾斜的,可能20%的metric会聚集80%的数据,甚至更严重。因为hbase把数据按照Rowkey增序存储在不同的机器上,所以这种数据切斜很可能会导致hbase集群某些机器读写压力非常大,但别的机器却没什么压力。
为了解决数据热点的问题,OpenTSDB在2.2版本增加了对数据做分桶的能力。其实就是对每行数据的tags做hash,然后把hash值拼接到Rowkey前面,这样就可以使同metric产生的rowkey分散开,减少数据热点发生的可能性。 可以通过以下两个参数开启salting功能。
tsd.storage.salt.width #桶宽度
tsd.storage.salt.buckets #设置最大多少个bucket
注意,不要突发奇想去开关这个功能,这个集群要么从始至终开这个功能要么不开。否则你中途开关,会导致操作前的数据无法查询。 另外还有一点,开启salting会影响查询性能,比如你想扫某个metric下所有数据,这个时候就得遍历所有的bucket。
二、OpenTSDB安装配置
1、安装环境
-
操作系统:CentOS Linux release 7.2.1511 (Core)
-
OpenTSDB版本:2.3.0
-
JDK版本:1.8.1_101
-
Apache HBase版本:1.2.2
2、安装部署
参考官方文档
(1)将opentsdb安装包下载到本地
wget https://github.com/OpenTSDB/opentsdb/releases/download/v2.3.0/opentsdb-2.3.0.rpm
执行以下命令进行安装:
yum localinstall opentsdb-2.3.0.rpm
OpenTSDB主要目录介绍:
- /etc/opentsdb —— 配置文件目录
- /usr/share/opentsdb —— 应用程序目录
- /usr/share/opentsdb/bin —— "tsdb"启动脚本目录
- /usr/share/opentsdb/lib —— Java JAR library
- /usr/share/opentsdb/plugins —— 插件和依赖
- /usr/share/opentsdb/static —— GUI 静态文件
- /usr/share/opentsdb/tools —— 脚本和其他工具
- /var/log/opentsdb —— 日志存放目录
安装包安装后包括一个init脚本 /etc/init.d/opentsdb ,此脚本可以 start,stop 和 restart OpenTSDB。简单地调用 service opentsdb start 启动和 service opentsdb stop 关闭。
注意,在安装之后,tsd 将不是运行状态,所以你能够编辑配置文件。编辑配置文件,然后启动 TSD。
(2)在hbase建表
如果你第一次用你的HBase实例运行OpenTSDB,你需要创建必要的HBase表。使用 /usr/share/opentsdb/tools/create_table.sh 脚本可以轻松建表。执行:
cd /usr/share/opentsdb/tools
env COMPRESSION=SNAPPY HBASE_HOME=/usr/hdp/2.6.1.0-129/hbase ./create_table.sh
COMPRESSION参数指定压缩方式,可选值是 NONE,LZO,GZIP,或者 SNAPPY 。这个命令将在指定的HBase中创建四张表:tsdb, tsdb-uid, tsdb-tree 和 tsdb-meta。如果你只是评估OpenTSDB,现在就不用关心压缩方式。在生产环境中,你要使用一个最合适的有效压缩库。
(3) 相关配置
编辑 /etc/opentsdb/opentsdb.conf 配置文件:
tsd.storage.hbase.zk_basedir = /hbase-unsecure
tsd.storage.hbase.zk_quorum = node2.bigdata:2181,master.bigdata:2181,node1.bigdata:2181
提示:tsd.storage.hbase.zk_basedir 属性值参考 HBase 属性 zookeeper.znode.parent 的值;tsd.storage.hbase.zk_quorum 属性值为以逗号分隔的要连接的zookeeper节点主机列表,格式如上。
其他配置信息请参考 配置说明
三、OpenTSDB使用说明
公司OpenTSDB:http://192.168.1.191:4242/
1、启动服务
当完成以上配置后,就可以启动 TSD 了:
servie opentsdb start
/usr/share/opentsdb/etc/init.d/opentsdb start
如果 service opentsdb start 命令报错,可以直接使用 /usr/share/opentsdb/etc/init.d/opentsdb start,其他命令亦同。
在成功启动之后,就可以通过node01:4242你的本地机器上)访问 TSD 的web界面。
2、数据输入
当前,有三种将数据获取到OpenTSDB的主要方法:Telnet API,HTTP API和从文件批量导入。
(1)Telnet API
tsd --port=PORT --staticroot=PATH --cachedir=PATH
先创建meric
tsdb mkmetric mymetric.data_1 mymetric.iot
[root@master opentsdb]# tsdb mkmetric mymetric.data_1 mymetric.iot
metrics mymetric.data_1: [0, 0, 3]
metrics mymetric.iot: [0, 0, 8]
创建metric:
两种方式,选择其一即可。不管何种导入方式都必须先设置metric。
- 事先在opentsdb中创建metric。如生成两个名为mymetric.data_1和mymetric.data_2的metric。如下:
tsdb mkmetric mymetric.data_1 mymetric.data_21 - 设置自动生成metric。修改opentsdb.conf设置:``
tsd.core.auto_create_metrics = true
数据写入:
1.put方式,单条插入
[root@master opentsdb]# telnet master.bigdata 4242
Trying 192.168.1.191...
Connected to master.bigdata.
Escape character is '^]'.
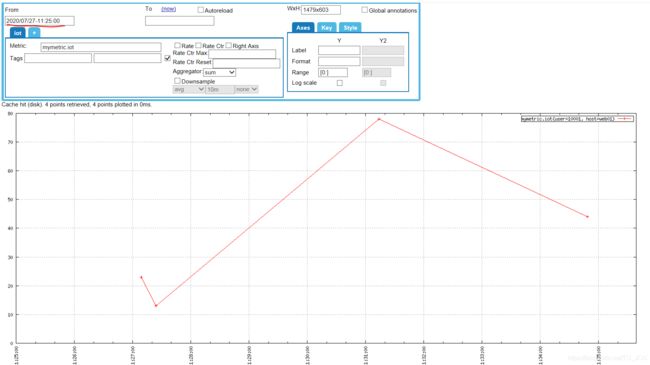
p
put mymetric.iot 1595820429 23 host=web01 user=10001
put mymetric.iot 1595820444 13 host=web01 user=10001
put mymetric.iot 1595820674 78 host=web01 user=10001
put mymetric.iot 1595820889 44 host=web01 user=10001
--只能一条数据put,不能一起put
2.import方式,批量导入
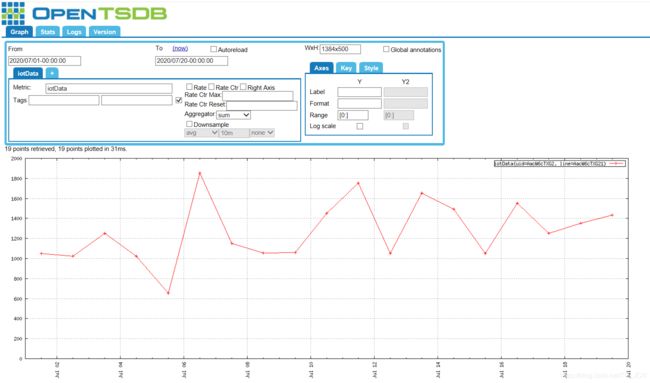
导入文件格式:import
[root@master ~]# cd /usr/share/opentsdb/bin/
[root@master bin]# tsdb import --config=/usr/share/opentsdb/etc/opentsdb/opentsdb.conf /mytest/testdata.txt
[root@master bin]# cat /mytest/testdata.txt
iotData 1593576000000 1052 uid=AacW6cTXG2 line=AacW6cTXG21
iotData 1593662400000 1022 uid=AacW6cTXG2 line=AacW6cTXG21
iotData 1593748800000 1252 uid=AacW6cTXG2 line=AacW6cTXG21
iotData 1593835200000 1022 uid=AacW6cTXG2 line=AacW6cTXG21
iotData 1593921600000 652 uid=AacW6cTXG2 line=AacW6cTXG21
iotData 1594008000000 1852 uid=AacW6cTXG2 line=AacW6cTXG21
iotData 1594094400000 1152 uid=AacW6cTXG2 line=AacW6cTXG21
iotData 1594180800000 1055 uid=AacW6cTXG2 line=AacW6cTXG21
iotData 1594267200000 1059 uid=AacW6cTXG2 line=AacW6cTXG21
iotData 1594353600000 1452 uid=AacW6cTXG2 line=AacW6cTXG21
iotData 1594440000000 1752 uid=AacW6cTXG2 line=AacW6cTXG21
iotData 1594526400000 1052 uid=AacW6cTXG2 line=AacW6cTXG21
iotData 1594612800000 1652 uid=AacW6cTXG2 line=AacW6cTXG21
iotData 1594699200000 1492 uid=AacW6cTXG2 line=AacW6cTXG21
iotData 1594785600000 1052 uid=AacW6cTXG2 line=AacW6cTXG21
iotData 1594872000000 1552 uid=AacW6cTXG2 line=AacW6cTXG21
iotData 1594958400000 1252 uid=AacW6cTXG2 line=AacW6cTXG21
iotData 1595044800000 1352 uid=AacW6cTXG2 line=AacW6cTXG21
iotData 1595131200000 1435 uid=AacW6cTXG2 line=AacW6cTXG21
[root@master bin]#
(2)Http API
从2.0版开始,数据可以以“序列化程序”插件支持的格式通过HTTP发送。多个不相关的数据点可以在一个HTTPPOST请求中发送,以节省带宽。见…/api_http/put关于细节。
curl -i -XPOST 'http://192.168.1.191:4242/api/put?summary' --data-binary @testdata(1).txt
URL:
http://116.196.114.194:4242/api/put?summary
参数:
[
{
"metric": "sys.cpu.nice",
"timestamp": 1502190111,
"value": 18,
"tags": {
"host": "web01",
"dc": "lga"
}
},
{
"metric": "sys.cpu.nice",
"timestamp": 1502190171,
"value": 26,
"tags": {
"host": "web02",
"dc": "lga"
}
}
]
返回:
{
"success": 2,
"failed": 0
}
参考文档:
http://opentsdb.net/docs/build/html/user_guide/index.html
https://blog.csdn.net/xsdxs/article/details/53882504
http://blog.51cto.com/1196740/2164968
create 'test','info1',SPLITS => ['01|','02|','03|','04|']
(3)Java API
插入数据
import org.junit.Test;
import org.opentsdb.client.PoolingHttpClient;
import org.opentsdb.client.builder.MetricBuilder;
import org.opentsdb.client.response.SimpleHttpResponse;
import java.io.IOException;
public class test2 {
@Test
public void test_postJson_DefaultRetries() throws InterruptedException {
String iotID = new String("AacW6cTXG8");
try {
for (int i = 0; i < 10000; i++) {
PoolingHttpClient client = new PoolingHttpClient();
MetricBuilder builder = MetricBuilder.getInstance();
int x=(int)(10*Math.random());
long time = System.currentTimeMillis();
int a0=(int)(1000*Math.random());
int a1=(int)(1000*Math.random());
int a2=(int)(1000*Math.random());
int a3=(int)(1000*Math.random());
int a4=(int)(1000*Math.random());
int a5=(int)(1000*Math.random());
builder.addMetric("Test_iot01").setDataPoint(time,a0).addTag("diviceID", iotID).addTag("partID", iotID+"0");
builder.addMetric("Test_iot01").setDataPoint(time,a1).addTag("diviceID", iotID).addTag("partID", iotID+"1");
builder.addMetric("Test_iot01").setDataPoint(time,a2).addTag("diviceID", iotID).addTag("partID", iotID+"2");
builder.addMetric("Test_iot01").setDataPoint(time,a3).addTag("diviceID", iotID).addTag("partID", iotID+"3");
builder.addMetric("Test_iot01").setDataPoint(time,a4).addTag("diviceID", iotID).addTag("partID", iotID+"4");
builder.addMetric("Test_iot01").setDataPoint(time,a5).addTag("diviceID", iotID).addTag("partID", iotID+"5");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
SimpleHttpResponse response = client.doPost(
"http://192.168.1.191:4242/api/put/?details",
builder.build());
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
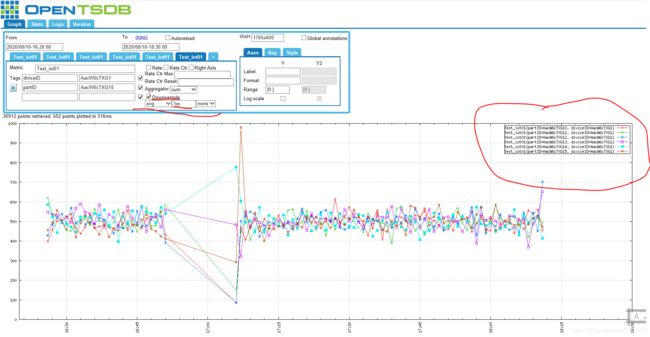
3、数据查询
CLI Tools
/usr/share/opentsdb/bin —— "tsdb"启动脚本目录·
usage: tsdb [args]
Valid commands: fsck, import, mkmetric, query, tsd, scan, search, uid, version
创建指标
(1)Web UI
GUI有三个主要部分:
- 作为菜单的通知区域和选项卡区域。
- 查询生成器,它允许您选择将显示什么以及如何显示
- 显示查询结果的图形区域。
1、菜单区域
该菜单是一组选项卡,可以单击不同的选项。
- 图-这是默认情况,允许您发出查询并生成图。
- Stats-此选项卡将显示关于运行中的TSD的统计信息列表。可以通过
/stats或/api/stats端点。 - Logs-如果配置了Logback,则此选项卡将显示TSD的最新1,024个日志条目的列表。
- 版本-显示有关tsd的版本信息。
(1)在构建图形时,如果出现错误,将在菜单上方显示一条消息。单击箭头展开消息并确定错误所在。
(2)Metric box
这个区域是您选择度量、可选标记、聚合函数和可能的下采样器的地方。顶部是一对蓝色标签。每个图可以显示多个度量,制表符组织不同的子查询。每个图至少需要一个度量,所以您将在第一个选项卡中选择该度量。若要向图中添加另一个度量,请单击+选项卡,您将能够设置另一个子查询。如果您已经配置了多个度量标准,只需单击与要修改的度量对应的选项卡即可。该选项卡将显示与其关联的度量名称的子集。
Metric框:是选择Metric 的地方。该字段自动完成,因为您键入就像一个现代的网页浏览器。自动完成通常是区分大小写的,因此只有与提供的大小写匹配的指标才会显示出来。默认情况下,只返回25个顶级匹配项,因此在键入时可能不会看到所有可能的选项。当条目出现时,单击所需的条目,或者继续键入,直到您在框中有了整个度量为止。
rate方框:允许您将度量的所有时间序列转换为更改值的比率。默认情况下,此选项将被关闭。
rate Ctr:启用下面的汇率选项框,并指示所绘制的度量值是一个单调递增的计数器。如果是这样,您可以选择提供一个最大值(Rate Ctr Max)对于计数器,以便当它翻转时,图形将显示适当的值,而不是一个负数。同样,您也可以选择设置一个重置值(Rate Ctr Reset)如果速率大于该值,则将值替换为零。为了避免出现负尖峰,通常需要设置复位值为1的速率计数器。
对于具有不同比例的度量或时间序列,可以选择Right Axis 复选框为度量的时间序列在图形的右侧添加另一个轴。如果刻度相差很大,这可以使图形更加可读性。
Aggregator:是用于操作与子查询关联的多个时间序列的数据的聚合函数的下拉列表。默认的聚合器是相加但你可以从许多其他选项中选择。
Downsample :降采样,用于减少图形上显示的数据点的数量。默认情况下,gnuart将放置一个字符,例如+或x在图的每个数据点。当时间跨度很大,而且有许多数据点时,图形就会变得很粗和难看。使用向下抽样来减少点数。只需从下拉列表中选择一个聚合函数,然后在第二个框中输入一个时间间隔。间隔必须遵循相对日期格式(不使用-ago构成部分)。例如,若要在一个小时下采样,请输入1h。最后一个选择框在与其他系列聚合时为下采样值选择一个“填充策略”。对于GUI中的图形化,只有“零”值才有区别,因为它将以零代替缺少的系列。看见日期和时间关于细节。
time secion:决定了图表中所有度量和时间序列的时间范围。这个 Frome time 决定图形何时开始,而端部时间决定它何时停止。必须填写这两个字段才能执行查询。时间可以是人类可读的、绝对的格式或相对的格式。看见日期和时间关于细节。
单击某个时间框将弹出一个实用程序,以帮助您选择时间。使用框左上角的箭头浏览月份,然后单击日期。右上角的相对链接是帮助您向前或向后跳1分钟、10分钟、1小时、1天、1周或30天。这个现在链接将将时间更新到本地系统上的当前时间。这个HH按钮可以让你选择一个小时阿姆或下午。MM按钮允许您选择一个规范化分钟。您还可以将时间剪切并粘贴到任何框中,也可以直接编辑时间。
(2)http API
- 返回metric=test的最近10秒的所有时序数据
1.Get方式:
/api/query?start=10s-ago&m=test
2.Post方式:
{
"start": "10s-ago",
"queries": [{
"aggregator": "none",
"metric": "test"
}]
}
返回:
[
{
"metric": "test",
"tags": {
"device": "D47899",
"label": "6015",
},
"aggregateTags": [],
"dps": {
"1525343027": 26.26,
"1525343032": 25.32
}
},
{
"metric": "test",
"tags": {
"device": "D47899",
"label": "6019",
},
"aggregateTags": [],
"dps": {
"1525343027": 25.32,
"1525343032": 26.74
}
},
……
{
"metric": "test",
"tags": {
"device": "D47899",
"label": "6010",
},
"aggregateTags": [],
"dps": {
"1525343027": 26.8,
"1525343032": 25.75
}
}
]
1.Get方式:
/api/query?start=10s-ago&m=sum:test{device=*,label=1001|1002}
注:device和label都为tag
2.Post方式:
{
"start": "10s-ago",
"queries": [
{
"aggregator": "sum",
"metric": "test",
"filters": [
{
"type":"wildcard",
"tagk":"device",
"filter":"*",
"groupBy":true
},
{
"type":"literal_or",
"tagk":"label",
"filter":"1001|1002",
"groupBy":true
}
]
}
]
}
返回:
[
{
"metric": "test",
"tags": {
"label": "1001",
"device": "A11223",
"status": "0"
},
"aggregateTags": [],
"dps": {
"1525344862": 24.76,
"1525344867": 24.98
}
},
{
"metric": "app.services.temperature",
"tags": {
"label": "1002",
"device": "A11224",
"status": "0"
},
"aggregateTags": [],
"dps": {
"1525344862": 25.75,
"1525344867": 24.74
}
}
]
三、对每个时序最近两小时的数据点按小时分组计算(使用downsample)
2)对每个时序最近两小时的数据点按小时分组计算(使用downsample)
1.Get方式:
/api/query?start=2h-ago&m=sum:1h-count:test{device=*,label=1001|1002}
2.Post方式:
{
"start": "2h-ago",
"queries": [
{
"aggregator": "sum",
"metric": "test",
"downsample": "1h-count",
"filters": [
{
"type":"literal_or",
"tagk":"device",
"filter":"*",
"groupBy":true
},
{
"type":"literal_or",
"tagk":"label",
"filter":"1001|1002",
"groupBy":true
}
]
}
]
}
返回:
[
{
"metric": "test",
"tags": {
"label": "1001",
"device": "A11223",
"status": "0"
},
"aggregateTags": [],
"dps": {
"1525341600": 720,
"1525345200": 91
}
},
{
"metric": "test",
"tags": {
"label": "1002",
"device": "A11224",
"status": "0"
},
"aggregateTags": [],
"dps": {
"1525341600": 720,
"1525345200": 91
}
}
]
(3)Java API
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.junit.Test;
import org.opentsdb.client.ExpectResponse;
import org.opentsdb.client.HttpClientImpl;
import org.opentsdb.client.request.QueryBuilder;
import org.opentsdb.client.request.SubQueries;
import org.opentsdb.client.response.SimpleHttpResponse;
import org.opentsdb.client.util.Aggregator;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Map;
public class QueryTest {
@Test
public void queryTest() throws IOException {
HttpClientImpl client = new HttpClientImpl("http://192.168.1.191:4242");
String iotID = new String("AacW6cTXG3");
String PID = new String("AacW6cTXG31");
QueryBuilder builder = QueryBuilder.getInstance();
SubQueries subQueries = new SubQueries();
String zimsum = Aggregator.zimsum.toString();
subQueries.addMetric("Test_iot01")
.addTag("diviceID", iotID)
.addTag("partID", PID)
.addAggregator(zimsum);
//.addDownsample("1s-" + zimsum);
long now = new Date().getTime() ;
builder.getQuery().addStart(1596873021).addEnd(now).addSubQuery(subQueries);
//System.out.println(builder.build());
try {
SimpleHttpResponse response = client.pushQueries(builder, ExpectResponse.STATUS_CODE);
String content = response.getContent();
int statusCode = response.getStatusCode();
if (statusCode == 200) {
JSONArray jsonArray = JSON.parseArray(content);
for (Object object : jsonArray) {
JSONObject json = (JSONObject) JSON.toJSON(object);
String dps = json.getString("dps");
Map<String, String> map = JSON.parseObject(dps, Map.class);
for (Map.Entry entry : map.entrySet()) {
Object key = entry.getKey();
System.out.println("Id:"+iotID+
",Time:" + entry.getKey() + ",Value:" + entry.getValue());
Double.parseDouble(String.valueOf(entry.getValue()));
}
}
}
//System.out.println(jsonArray);
} catch (IOException e) {
e.printStackTrace();
}
}
/*
* 将时间戳转换为时间
*/
public static String stampToDate(String s){
String res;
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
long lt = new Long(s);
Date date = new Date(lt);
res = simpleDateFormat.format(date);
return res;
}
/*
* 将时间转换为时间戳
*/
public static String dateToStamp(String s) throws ParseException {
String res;
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date date = simpleDateFormat.parse(s);
long ts = date.getTime();
res = String.valueOf(ts);
return res;
}
}