flink任务监控- 利用Grafana和Prometheus实现实时计算平台任务监控
简介
最近负责公司基于flink实时计算平台的基本任务监控,包括重启通知,失败监控,一些关于flink 在pushgateway 上exported_job信息上报便于最后删除 pushgateway上的信息避免重复告警等,其实开始想的也是在网上找,没有找到,现在就总结一下自己的做法。第一次写博文不合理之处大家多多理解。
修改flink的flink-conf.yaml配置文件
具体配置讲解网上很多不赘述了
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
metrics.reporter.promgateway.host: host
metrics.reporter.promgateway.port: 9091
metrics.reporter.promgateway.jobName: flinkxx #自定义
metrics.reporter.promgateway.randomJobNameSuffix: true
metrics.reporter.promgateway.deleteOnShutdown: false
#metrics.reporter.promgateway.groupingKey: job_name=
metrics.reporter.promgateway.interval: 30 SECONDS
flink job 任务失败监控告警到实时计算平台
我们这一个指标监控主要是基于flink_jobmanager_job_uptime 这个指标进行了监控的,特性是在job任务存活时,他会按照你这个配置metrics.reporter.promgateway.interval上报频率递增。基于这个特点,当任务失败后这个数值就不会改变,就能监控到任务失败。
Grafana 上查询规则
数据查询策略图:

30秒为数据上报到 promgateway 频率 除以100为了数据好看,当job任务失败后数 flink上报的promgateway 的 flink_jobmanager_job_uptime指标值不会变化。这时候 ((flink_jobmanager_job_uptime)-(flink_jobmanager_job_uptime offset 30s))/100 值就会是0,配置告警
Grafana 上告警规则
直接上图:
在告警通知中可以邮件和webhook,webhook给实时计算平台接口告警,实时计算平台的一些自定义操作看你的需求怎样了,我们自己是做的任务状的修改为FAILED。这个里我们接口里做了通过 发起http delete 请求删除 pushgateway 上flink上报的 metrics 信息,删除调用http://localhost:9091/metrics/job/hlink_jobs6d35e8378ffc405c0a3d5a8d24574bf0,hlink_jobs6d35e8378ffc405c0a3d5a8d24574bf0 这个为 exported_job, 一个运行在yarn的flink任务会有根据任务运行模式会有两个,jobmanager的exported_job和taskmanager的exported_job。
webhook需要提前配合好在 告警时候直接引入.
上图:

flink job 网络延时或任务重启监控
这个告警也是基于flink_jobmanager_job_uptime 指标,为了恢复 网络延时或者重启产生的,flink任务失败已经把实时计算平台任务状态改成的FAILED从新改成RUNNING 状态。延时会导致查询公式**((flink_jobmanager_job_uptime offset 30s)-(flink_jobmanager_job_uptime))/1000** 的值 突然大数值小于-30(正常情况为-30),重启会导致flink_jobmanager_job_uptime指标清零从新从0值上报,导致查询公式**((flink_jobmanager_job_uptime offset 30s)-(flink_jobmanager_job_uptime))/1000** 计算值突然大于0(正常情况为-30)这时候我们就会发起告警。
Grafana 上查询规则
数据查询策略图:

Grafana 上告警规则
告警配置图:

具体配置告警的邮件通知和webhook http的自定义接口操作自己实时计算平台数据。
flink job 重启次数告警
这个告警也是基于flink_jobmanager_job_numRestarts 指标,这个flink job的重启次数,一般设置重启策略的在任务异常重启后这个数值会递增+1。我们用这个值表来上报每次重启后,在实时计算平台上的重启次数+1,展示给用户,也可以邮件告知用户。
Grafana 上查询规则
数据查询策略图:
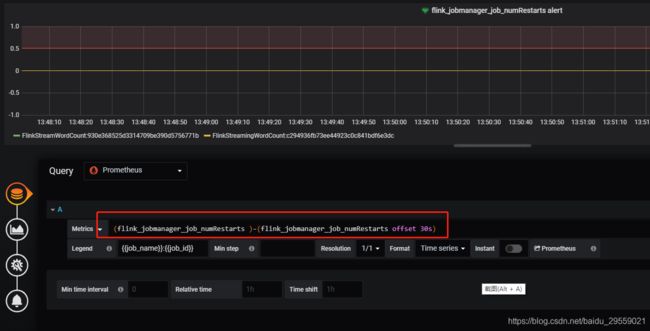
也是利用当前值减去30秒前的值,如果等于1证明重启了一次 然后告警。
Grafana 上告警规则
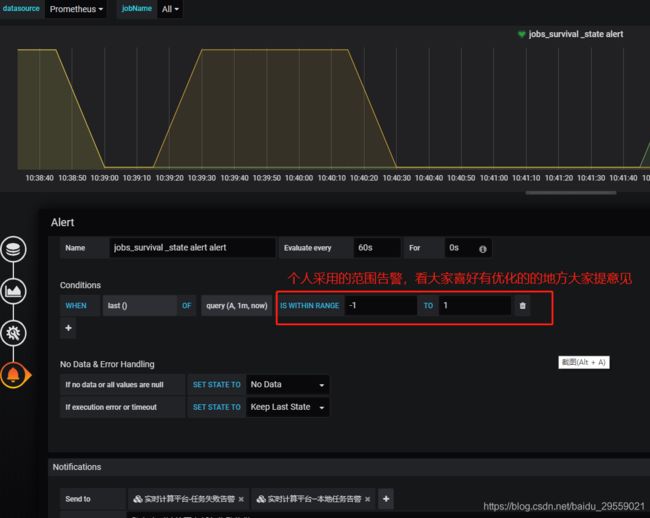
告警策略图:
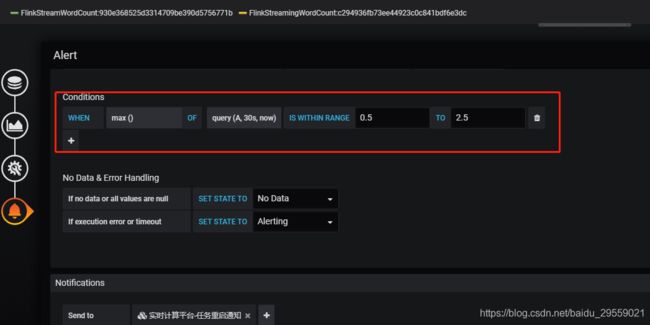
不多做解释使用了范围告警。
flink job 的exported_job 上报告警
这个主要用于上报flink 在pushgateway 上展示的 jobmanager的exported_job和taskmanager的exported_job。目的是为了后期删除pushgateway 上flink job失败或停止后的遗留信息。这个上报也是基于flink_jobmanager_job_uptime 指标。
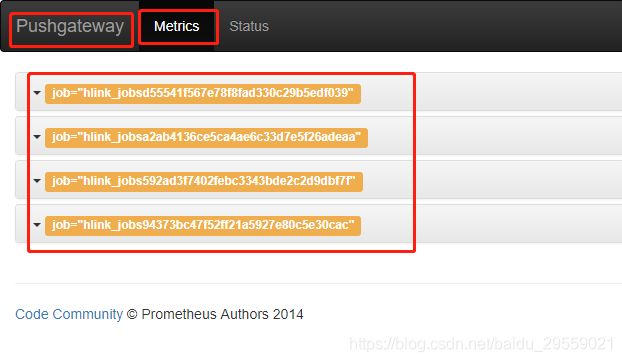
对应的就是这些。不删会导致grafana查询过期数据job任务信息一致在。话不多说上图。
Grafana 上查询规则
数据查询策略图:
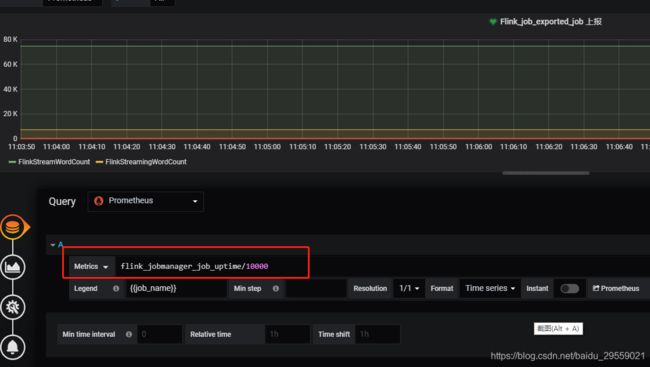
Grafana 上告警规则
数据告警策略图:
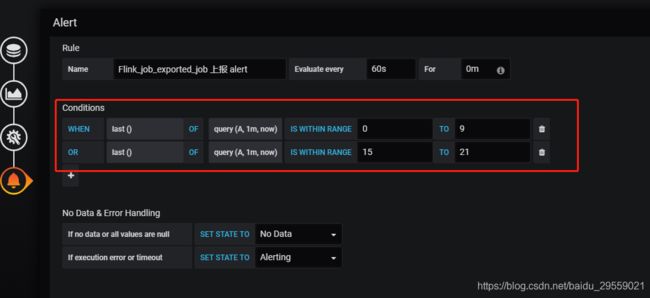
告警策略这样配置是我们自己的原因,在使用flink_jobmanager_job_uptime 指标上报exported_job自身自能上报 jobmanager的exported_job,我们自己在实时平台的接口中通过 Prometheus查询 http://localhost:9090/api/v1/query?query=flink_taskmanager_job_task_operator_select_rate{job_name=‘FlinkStreamWordCount’,job_id=‘930e368525d3314709be390d5756771b’} 查询拿到对应的 taskmanager的exported_job,flink_taskmanager_job_task_operator_select_rate这个指标是选择的一个信息比较全的指标。做两次告警原因是 这个查询在第一查询时候是查不到结果。所以用两次告警解决。应该是时间差的问题。不知道小伙伴有其他方法不,可以告诉我我优化一下哦。
告警数据样例
相信大家都能看懂吧
{
"panelId":78,
"dashboardId":4,
"ruleName":"jobs_survival _state alert",
"state":"alerting",
"message":"任务运行状态告警",
"ruleId":5,
"title":"[Alerting] jobs_survival _state alert",
"ruleUrl":"http://localhost:3000/d/-0rFuzoZk/flink-dashboard-hello?fullscreen&edit&tab=alert&panelId=78&orgId=1",
"orgId":1,
"evalMatches":[
{
"metric":"{exported_job=\"hlink_jobs381564b4d3e414fcb0e150814d34c77d\", host=\"fc_sit2_flink_v_l_03_fcbox_com\", instance=\"10.204.51.45:9091\", job=\"flink-yarn-push\", job_id=\"2fb16d151ea92994a2eaf6317cfc8c3e\", job_name=\"flinkWordCount_new\"}",
"value":1,
"tags":{
"instance":"localhost:9091",
"job_name":"yousJobname",
"exported_job":"hlink_jobs2be8c74c06b1f12a62a094f00944366f",
"job_id":"3ae6929814d93f79ed9670070821d5a7",
"host":"ssj_sit2_flwyiewi_com",
"job":"flink-yarn-push"
}
}],
"tags":{
}
}
总结
毕业四年了,第一次写博文。总结的一些 flink 任务监控告警基于Grafana和Prometheus的使用技巧,希望能够对大家有一点小的启发吧。有些可能不是很好,大家有什么更好的方案可以分享给我,感谢观看!