谈谈随机森林的视觉应用-Random Forests(1)
写这个东西是我开此博客的动机,也是我第一次用中文阐述关于自己研究的东西。写得不好请各位包涵!
(关于这个名字的中文翻译,我一向觉得非常的别扭,所以在博文中我继续使用其英文名称)
当然,对于英语比汉语更顺畅的同学,直接跳过此文,去读Antonio Criminisi 的tutorial以及相应的ppt【1】,我在phd定题的阶段,一次偶然的机会听了他的一个讲座然后进行了简短的探讨,随后决定了自己phd的topic就一定要将这个东西用一用,结果一做不可收拾,做了一年多。Random Forests的起源很早,之前也有了很多的应用,这里只讨论近几年的发展。或者说,在J. Gall 的Hough Forests提出之后。
简单的回顾一下,Random Forests, 就是很多的Random Tree的Ensemble. 一棵不行,用多棵来平均一下,就这么简单的思想。至于为什么要采用平均的这种Ensemble方法,那说起来就麻烦了,总之呢,就是一堆人搞来搞去搞了半天,各种证明与推导,最后就订下来,这么一个平均的方法,不错!一棵简单的决策树干什么呢,就是将问题细化。说起来太抽象,举个例子:
现在有这个一张图片,你想知道其在室内还是室外拍摄的,专业一点可能叫场景分类吧,你先看看图像的上方是不是蓝色的,如果是,图像到了第二层的节点,再判断一下,底部是不是蓝色,不是,那么属于outdoor的可能性或者label就给出来了。是不是很简单?你是否有一下疑问:做这两个判断就足够了吗?我怎么知道要作什么判断?如果你思考了这么两个问题,那么证明你是一个具有machine learning基础的人。所以继续读下去是有意义的。
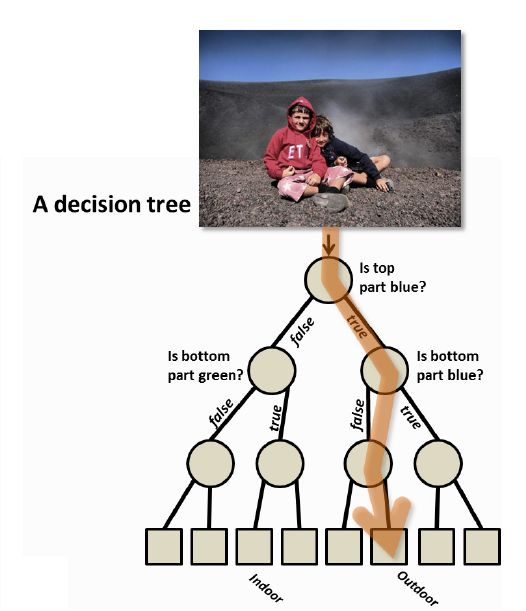
一棵树的结果就是这么简单,每个节点只有两个树丫子,直到顶端。节点就分为两类,一类叫Internal node,另一类叫Leaf node。当树已经有了的情况下,用于测试的数据就是一个笨蛋,想知道自己是谁,然后跑来问树,从树根往上爬,走到每个internal node内部节点,负责该节点的开门卫兵就会打量一下这个来者,根据他的特征给他开左边门还是右边门,直到无路走的时候,到了leaf node,leaf node比较牛X,其实就像个算命先生,告诉你,既然你走到我这来了,我帮你算一卦,你(大概)是什么东西。这个算命先生自然是故作神奇,其实他就是像字典中的一个字而已,他就告诉一下来的人怎么发音,然后这个笨蛋就大概知道了自己的名字。
RF为什么又火了?因为人的天性好玩,微软把人类整天弄得跟猿人一样的还不够,还要让我们玩物丧志!所以就有了X-Box的问世,X-Box的核心就是Kinect,Kinect也不是什么新鲜玩意,而是Kinect背后,有个算法,可以认识前面站了个人,然后还知道人的每个关节大概在哪。这个看似小儿科的东西,微软花了不小的代价,2011年,CVPR的best paper说,他们干了这事: Real-time Human Pose Recognition in Parts from Single Depth Images, Jamie Shotton, Andrew Fitzgibbon, Mat Cook, Toby Sharp, Mark Finocchio, Richard Moore, Alex Kipman, Andrew Blake。这篇文章在algorithm的层面对RF没有太大的贡献。说简单点,RF本身的技术层面只有两个:挑选很好的卫兵和算命先生,他们就是这么模型的关键!所有的关于RF的tree的改进都围绕这两个为中心,卫兵,被成为split function 或者 test function,而算命先生,成为leaf model。这篇best paper的test function 很简单,就是选择一个图像的patch,然后在patch里选择两个像素位置,比较其normalized depth。如果对depth image不熟悉也不知何为normalized depth,将其理解为一gray scale image 即可,比较 gray scale 的大小,当位置1的值大于位置2的value大于某个阈值的时候,go left,otherwise, go right. 这个卫兵就要记住两个位置和这个阈值即可,所有来的patch,找到这两个位置然后比较一下就知道该给它开哪个门了。然后到leaf node, 存着一个概率,属于哪个部分的可能性。纵观这个过程,其实tree的目的就是想把属于相同的身体部分的弄到某一个(或一些)叶子。所以,这样的tree其实与codebook learning没有什么区别,每一个叶子就是一个codeword,所以算命先生就是一个复读机,对每个来算命的,其告知的信息都是一样的。
这个由Jamie Shotton领导的组,高举 Andrew Blake主义的旗帜,坚持科学发paper观,以各种廉价的Intern为基础,全面推进在depth image 中进行人体姿态估计事业的发展。发了一系列的paper:
Ross Girshick, Jamie Shotton, Pushmeet Kohli, Antonio Criminisi, and Andrew Fitzgibbon, Efficient Regression of General-Activity Human Poses from Depth Images, in ICCV, IEEE, October 2011。
Min Sun, Pushmeet Kohli, and Jamie Shotton, Conditional Regression Forests for Human Pose Estimation, in Proc. CVPR, IEEE, 2012
Jamie Shotton, Ross Girshick, Andrew Fitzgibbon, Toby Sharp, Mat Cook, Mark Finocchio, Richard Moore, Pushmeet Kohli, Antonio Criminisi, Alex Kipman, and Andrew Blake, Efficient Human Pose Estimation from Single Depth Images, in Trans. PAMI, IEEE, 2012
Jonathan Taylor, Jamie Shotton, Toby Sharp, and Andrew Fitzgibbon, The Vitruvian Manifold: Inferring Dense Correspondences for One-Shot Human Pose Estimation, in Proc. CVPR, IEEE, June 2012
说到灌水这事,人家有本事当然可以灌水。并且,Reviewers肯定知道,这些papers只能出自于他们组,为什么? 要知道这个原因,就要说这篇best paper为什么是best paper了。前面说了,其实在RF技术层面上,没有什么建树。其神奇之处在于其训练方法。RF一直有个比较困扰的问题就是依赖于比较大的数据进行训练。而这个问题的对象是人,人的自由度那么大,并且要获取准确的3D ground truth也不是一个简单的事,这帮聪明的家伙用到了计算机图形学,造了一堆的各种虚拟的人。男男女女,大大小小,丑的漂亮的,当官的(肚子大的)或者萎缩男(色咪咪的)都造出来了,然后他们有很大的数据库可以存,电脑也很好,内存怎么说也要一个T才行,注意是RAM,不是hard drive。当然,他们有钱,这些都好办!所以,发这些文章的,能是别人吗?在ICCV CVPR一年有几篇关于这个问题的,鬼都知道肯定是他们的paper。
但是,灌水归灌水,其含金量确实值一篇cvpr 或者iccv,今天先写到这(第一次发现用我的电脑打汉字这么困难,ibus不行了,为了写blog,我得找一个在ubuntu下能快速打汉字的pkg). 下一篇我才会切入我想说的,从decision forests到 regression forets. 这才是我的真爱!
【1】Antonio Criminisi, Jamie Shotton, and Ender Konukoglu, Decision Forests: A Unified Framework for Classification, Regression, Density Estimation, Manifold Learning and Semi-Supervised Learning. In: Foundations and Trends® in Computer Graphics and Vision: Vol. 7: No 2-3, pp 81-227.
本文引用地址:http://blog.sciencenet.cn/blog-941987-690984.html