Apache Flink之程序的部署【章节二】
程序部署
在Flink中多中操作方式对编写好的程序进行部署,下面对各种部署方式的介绍
本地执⾏
//1.创建流计算执⾏环境
val env = StreamExecutionEnvironment.createLocalEnvironment(3)
//2.创建DataStream
val text = env.socketTextStream("CentOS", 9999)
//3.执⾏DataStream的转换算⼦
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
//4.将计算的结果在控制打印
counts.print()
//5.执⾏流计算任务
env.execute("Window Stream WordCount")
在学习的时候可用于方便测试
远程部署
//1.创建流计算执⾏环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.创建DataStream - 细化
val text = env.socketTextStream("CentOS", 9999)
//3.执⾏DataStream的转换算⼦
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
//4.将计算的结果在控制打印
counts.print()
//5.执⾏流计算任务
env.execute("Window Stream WordCount")
StreamExecutionEnvironment.getExecutionEnvironment⾃动识别运⾏环境,如果运⾏环境是idea,系统会⾃动切换成本地模式,默认系统的并⾏度使⽤系统最⼤线程数,等价于Spark中设置的local[*] ,如果是⽣产环境,需要⽤户在提交任务的时候指定并⾏度--parallelism
①WEB UI部署
⽤户可以访问Flink的WEB UI地址:http://主机名:8081 可以部署项目
1.将程序maven package进行 打包
2.访问http://主机名:8081

3.点击提交作业即可
②通过脚本部署
[root@CentOS ~]# cd /usr/flink-1.10.0/
[root@CentOS flink-1.10.0]# ./bin/flink run
--class com.baizhi.quickstart.FlinkWordCountQiuckStart
--detached
# 后台提交
--parallelism 4 #指定程序默认并⾏度
--jobmanager CentOS:8081 # 提交⽬标主机
/root/flink-datastream-1.0-SNAPSHOT.jar
Job has been submitted with JobID f2019219e33261de88a1678fdc78c696
查看现有任务
[root@CentOS flink-1.10.0]# ./bin/flink list --running --jobmanager CentOS:8081
Waiting for response...
------------------ Running/Restarting Jobs -------------------
01.03.2020 05:38:16 : f2019219e33261de88a1678fdc78c696 : Window Stream WordCount
(RUNNING)
--------------------------------------------------------------
No scheduled jobs.
[root@CentOS flink-1.10.0]# ./bin/flink list --all --jobmanager CentOS:8081
Waiting for response...
------------------ Running/Restarting Jobs -------------------
01.03.2020 05:44:29 : ddfc2ddfb6dc05910a887d61a0c01392 : Window Stream WordCount
(RUNNING)
--------------------------------------------------------------
No scheduled jobs.
---------------------- Terminated Jobs -----------------------
01.03.2020 05:36:28 : f216d38bfef7745b36e3151855a18ebd : Window Stream WordCount
(CANCELED)
01.03.2020 05:38:16 : f2019219e33261de88a1678fdc78c696 : Window Stream WordCount
(CANCELED)
--------------------------------------------------------------
取消指定任务
[root@CentOS flink-1.10.0]# ./bin/flink cancel --jobmanager CentOS:8081
f2019219e33261de88a1678fdc78c696
Cancelling job f2019219e33261de88a1678fdc78c696.
Cancelled job f2019219e33261de88a1678fdc78c696.
查看程序执⾏计划
[root@CentOS flink-1.10.0]# ./bin/flink info --class
com.baizhi.quickstart.FlinkWordCountQiuckStart --parallelism 4 /root/flinkdatastream-1.0-SNAPSHOT.jar
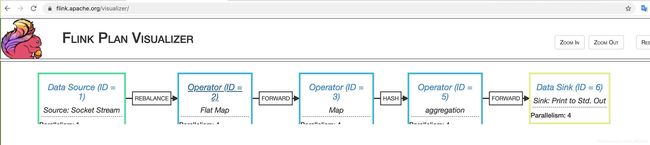
----------------------- Execution Plan -----------------------
{"nodes":[{"id":1,"type":"Source: Socket Stream","pact":"Data
Source","contents":"Source: Socket Stream","parallelism":1},{"id":2,"type":"Flat
Map","pact":"Operator","contents":"Flat Map","parallelism":4,"predecessors":
[{"id":1,"ship_strategy":"REBALANCE","side":"second"}]},
{"id":3,"type":"Map","pact":"Operator","contents":"Map","parallelism":4,"predecessors"
:[{"id":2,"ship_strategy":"FORWARD","side":"second"}]},
{"id":5,"type":"aggregation","pact":"Operator","contents":"aggregation","parallelism":
4,"predecessors":[{"id":3,"ship_strategy":"HASH","side":"second"}]},
{"id":6,"type":"Sink: Print to Std. Out","pact":"Data Sink","contents":"Sink: Print to
Std. Out","parallelism":4,"predecessors":
[{"id":5,"ship_strategy":"FORWARD","side":"second"}]}]}
--------------------------------------------------------------
No description provided.
⽤户可以访问:https://flink.apache.org/visualizer/将json数据粘贴过去,查看Flink执⾏计划图
跨平台发布
object FlinkWordCountQiuckStartCorssPlatform {
def main(args: Array[String]): Unit = {
//1.创建流计算执⾏环境
var jars="/Users/admin/IdeaProjects/20200203/flink-datastream/target/flinkdatastream-1.0-SNAPSHOT.jar"
val env = StreamExecutionEnvironment.createRemoteEnvironment("CentOS",8081,jars)
//设置默认并⾏度
env.setParallelism(4)
//2.创建DataStream - 细化
val text = env.socketTextStream("CentOS", 9999)
//3.执⾏DataStream的转换算⼦
val counts = text.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.sum(1)
//4.将计算的结果在控制打印
counts.print()
//5.执⾏流计算任务
env.execute("Window Stream WordCount")
}
}
在运⾏之前需要使⽤mvn重新打包程序。直接运⾏main函数即可