0804-SparkStreaming
0804-SparkStreaming
- 第一章 Spark Streaming概述
- 1.1 Spark Streaming是什么
- 1.2 Spark Streaming架构
- 第二章 Dstream入门
- 2.1 WordCount 案例
- 2.2 WordCount 解析
- 第三章 Dstream 整合 Kafka
- 3.1 用法及说明
- 3.2 案例
- 第四章 Dstream转换
- 4.1 UpdateStateByKey
- 4.2 Window Operations
第一章 Spark Streaming概述
1.1 Spark Streaming是什么
Spark Streaming用于流式数据的处理。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象原语如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。
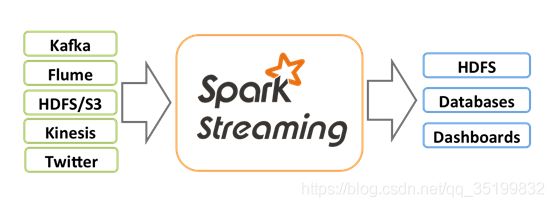
和Spark基于RDD的概念很相似,Spark Streaming使用离散化流(discretized stream)作为抽象表示,叫作
DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为 RDD 存在,而DStream是由这些RDD所组成的序列(因此得名“离散化”)。
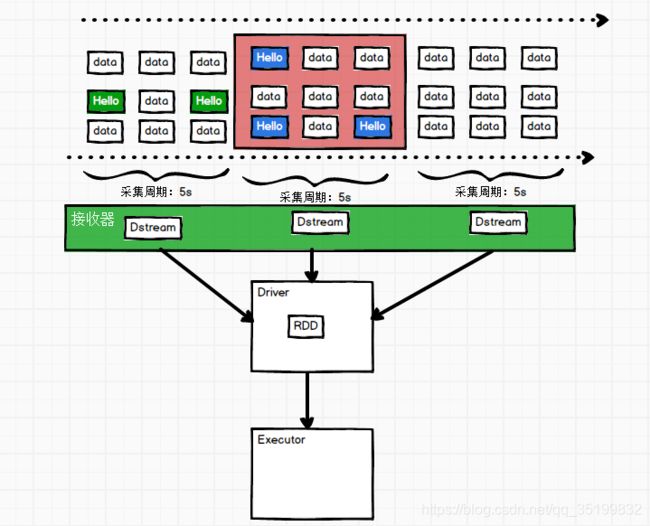
1.2 Spark Streaming架构
第二章 Dstream入门
2.1 WordCount 案例
-
需求: 使用netcat工具向9999端口不断的发送数据,通过SparkStreaming读取端口数据并统计不同单词出现的次数
-
添加依赖
-
编写代码
package com.lz.spark.day07
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @ClassName SparkStreamWordCount
* @Description: TODO
* @Author MAlone
* @Date 2019/12/18
* @Version V1.0
**/
object SparkStreamWordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("wordCount").setMaster("local[*]")
val streamContext: StreamingContext = new StreamingContext(conf, Seconds(5))
// 通过监听端口创建DStream
val lineStreams: ReceiverInputDStream[String] = streamContext.socketTextStream("node11", 9999)
// 业务处理
val result: DStream[(String, Int)] = lineStreams
.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey((x, y) => x + y)
result.print()
// 启动SparkStreamingContext
streamContext.start()
// 让SparkStreamingContext跟随接收器
streamContext.awaitTermination()
}
}
注意:如果程序运行时,log日志太多,可以将spark conf目录下的log4j 拷贝到classpath文件里面的日志级别改成WARN。
2.2 WordCount 解析
第三章 Dstream 整合 Kafka
3.1 用法及说明
在工程中需要引入 Maven 工件 spark- streaming-kafka_2.10 来使用它。包内提供的
KafkaUtils对象可以在 StreamingContext 和 JavaStreamingContext 中以你的 Kafka 消息创建出 DStream。由于 KafkaUtils 可以订阅多个主题,因此它创建出的 DStream 由成对的主题和消息组成。要创建出一个流数据,需要使用 StreamingContext 实例、一个由逗号隔开的 ZooKeeper 主机列表字符串、消费者组的名字(唯一名字),以及一个从主题到针对这个主题的接收器线程数的映射表来调用 createStream() 方法。
3.2 案例
需求:通过SparkStreaming从Kafka读取数据,并将读取过来的数据做简单计算(WordCount),最终打印到控制台。
- 导入依赖
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-8_2.11artifactId>
<version>2.1.1version>
dependency>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>0.11.0.2version>
dependency>
- 代码实现
package com.lz.spark.day07
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamKafka {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("kf")
val ssc = new StreamingContext(conf, Seconds(5))
val zkQuorum = "node11:2181,node12:2181,node13:2181"
val groupId = "yanlzh"
val topics = Map[String, Int]("first" -> 1)
val kafkaDStream: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(
ssc
, zkQuorum
, groupId
, topics
)
val result: DStream[(String, Int)] = kafkaDStream
.flatMap(_._2.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
result.print()
// 启动SparkStreamingContext
ssc.start()
// 让SparkStreamingContext跟随接收器
ssc.awaitTermination()
}
}
package com.lz
import kafka.serializer.StringDecoder
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object KafkaSparkStreaming {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并初始化SSC
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("kf")
val ssc = new StreamingContext(conf, Seconds(5))
//2.定义kafka参数
val brokers = "node11:9092,node12:9092,node13:9092"
val topic = "source"
val consumerGroup = "spark"
//3.将kafka参数映射为map
val kafkaParam: Map[String, String] = Map[String, String](
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",
ConsumerConfig.GROUP_ID_CONFIG -> consumerGroup,
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers
)
//4.通过KafkaUtil创建kafkaDSteam
val kafkaDSteam: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream[String, String, StringDecoder, StringDecoder](
ssc,
kafkaParam,
Set(topic),
StorageLevel.MEMORY_ONLY
)
//5.对kafkaDSteam做计算(WordCount)
kafkaDSteam.foreachRDD {
rdd => {
val word: RDD[String] = rdd.flatMap(_._2.split(" "))
val wordAndOne: RDD[(String, Int)] = word.map((_, 1))
val wordAndCount: RDD[(String, Int)] = wordAndOne.reduceByKey(_ + _)
wordAndCount.collect().foreach(println)
}
}
//6.启动SparkStreaming
ssc.start()
ssc.awaitTermination()
}
}
第四章 Dstream转换
4.1 UpdateStateByKey
val result: DStream[(String, Int)] = kafkaDStream
.flatMap(_._2.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
ssc.checkpoint("cp")
val result2: DStream[(String, Int)] = result.updateStateByKey[Int]((values: Seq[Int], state: Option[Int]) => {
val currentCount = values.sum
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
})