Spark RDD(DataFrame) 写入到HIVE的代码实现
在实际工作中,经常会遇到这样的场景,想将计算得到的结果存储起来,而在Spark中,正常计算结果就是RDD。
而将RDD要实现注入到Hive表中,是需要进行转化的。
关键的步骤,是将RDD转化为一个SchemaRDD,正常实现方式是定义一个case class.
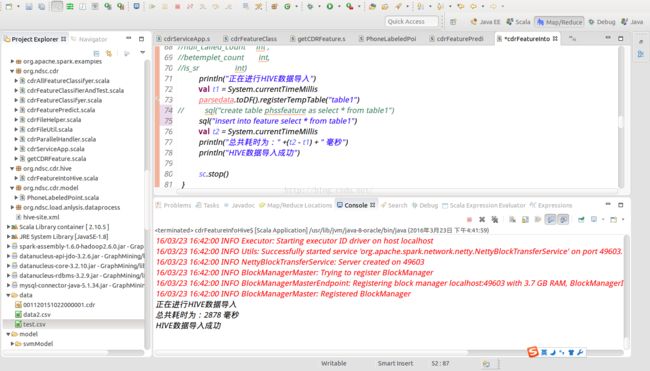
然后,关键转化代码就两行。
data.toDF().registerTempTable("table1")
sql("create table XXX as select * from table1")
而这里面,SQL语句是可以修改的,如写到某个分区,新建个表,选取其中几列等。
实现效果如图所示:
运行完成之后,可以进入HIVE查看效果,如表的字段,表的记录个数等。完胜。