2018年1月23号凌晨6:00左右,公司向银行推送交易的系统(以下简称推送系统)报出异常java.lang.OutOfMemoryError: Java heap space,随后系统挂掉了,系统的定时任务无法再启动,但因为没有添加监控,未能及时发现异常。
当天上午,业务通知有一批交易没有收到应有的结果,查看日志的时候发现推送系统近几个小时都没有打印日志了。尝试使用人去管理启停其定时任务,无效。尝试使用后台管理系统直接调用推送系统的接口,能够调通。
通知运维重启推送,业务恢复,解析了凌晨积压的大量文件。
初步怀疑,当天文件量过大,导致内存溢出,疑点在于当天的量仅接近150w,与平日交易量持平,认为是内存占用恰好达到了临界值,准备优化这些文件的解析逻辑。
当日经查证,没有相关内容的上线,没有业务量级的变化,且该机器上只有推送系统一个服务,不存在其他应用占用内存的情况,没有找到确切的原因。
2018年1月26日凌晨,推送系统系统再次停止工作,时间仍在凌晨6:00左右,此次同样是在上午发现之后重启。
此后,1月28号、30号、2月4号、6号均发生过内存溢出而重启的现象。
分析gc日志,大致如下图所示:
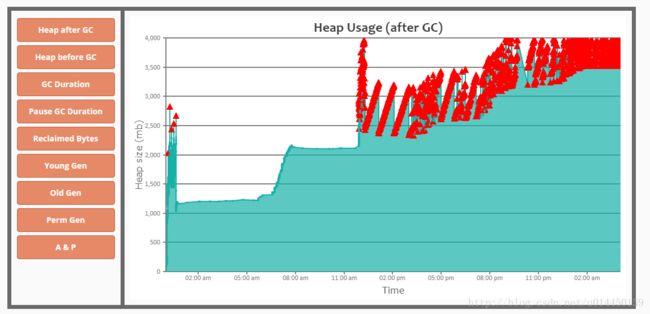
图中的每隔红色三角为一次full gc,一个绿色点为一次minor gc,正常情况下,推送系统运行一天,会触发一次到两次full gc,且之后内存占用会降低到很低的水平。但此次上线之后,一日之后,full gc次数严重高于常规量,且full gc之后内存占用仍处于比较高的水平,
一天多后,内存占满,系统异常。
根据数次gc日志分析,认为是系统代码问题导致的内存泄漏,排查代码之后,修改了部分可能会导致内存泄漏的代码,分别于2018年2月1日、2月6日、2月8日,上线了一些内存优化改动,情况略有改善,内存上升速度变慢,但是仍然未达到正常水平。
但在2月8日上线之后,2月9日,推送系统仍然出现了内存飙高的情况。
2018年2月9日上午,申请修改了JVM配置,下次内存溢出之后,会打印出heap dump文件。
此时临近春节假期,申请给推送系统添了自动邮件报警,假期期间可以临时通过重启解决问题。
2018年2月21日晚10点钟,推送系统内存由4G改为10G,重启。
2018年2月21日,经分析假期期间获取到的几个dump文件,结果如下图所示:
内存占用最高的部分都指向了公司使用的一个第三方监控平台,两个对象占用了85%左右的内存,因此基本可以确定是监控引起的。在和监控系统的沟通和公司内部的排查中发现,监控前端页面上显示推送系统的监控探针已经禁用,禁用时间是2018年1月22日上午10:26分。
时间与第一次出现内存溢出的时间吻合,禁用探针约1天之后,出现了内存溢出的情况。
2018年2月27日,在与监控平台的研发、产品了解之后确认:
当前使用的监控版本存在bug,正常探针在后台采集sql,使用sql作为key,其查询结果、耗时等信息作为value,存储在dump分析中占用内存最高的对象中,其根本结构是一个list。后台探针采集的sql会定时上报给前台和服务器,上报之后的sql会从list中清除掉。但是当前版本中,前台禁用,后台探针仍在采集sql,且无法上报,该list中的键值对会不断增加(也就解释了为何full gc过一段时间之后会失效)。后台探针本身有限制,键值对超过一定量之后会自动根据优先级清理一些低优先级的sql键值对。但是因推送系统本身sql select的结果较大(单一键值对占用内存1M——2M),当键值对数量达到3000左右(此时仍没有达到听云对于键值对数量设置的上限)的时候,内存已经爆满,full gc失效,内存溢出,推送系统停机。
在使用过探针的系统中有7个是使用了前端禁用的,但除推送以外,其他系统均已经停用该三方服务,因此后台sql采集仍在运行的系统仅有推送系统,也因此,只有推送系统出现了内存溢出的问题。
后续:
监控平台将以最高优先级对待此事,在2周内完成修复,目前的修复方向是:在前端禁用探针时,一并停止后台的sql采集。
公司将推送系统的监控探针下掉,重启,后续继续观察运行情况。
总结:
首先,前期排查的时候仍然有些不足,确认了没有业务量的变化,没有相关的上线,服务器上也没有运行其他系统,但是没有关注到监控探针一直是存在的;也没有查到1月22日当天禁用探针的事情。
既然应用层上没有任何变化,应该先从外部找原因,而不是直接先从代码上做优化,浪费了一周的时间做的优化收效甚微。应当在合适的时候寻求帮助,对于解决问题来说更有效。
