描述性统计
描述性统计
描述性统计会显示数据集的基本信息:数据集种有多少个非缺失的观测数据、列的平均值和标准偏差、还有最大值和最小值
import pyspark.sql.types as typ
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
fraud = spark.sparkContext.textFile('file:///Program Files/Pyproject/pyspark/data/ccFraud.csv')
header = fraud.first()
fraud = fraud.filter(lambda row: row != header).map(lambda row: [int(elem) for elem in row.split(',')])
fileds = [
*[
typ.StructField(h[1:-1], typ.IntegerType(), True)
for h in header.split(',')
]
]
schema = typ.StructType(fileds)
fraud_df = spark.createDataFrame(fraud, schema)
fraud_df.printSchema()
root
|-- custID: integer (nullable = true)
|-- gender: integer (nullable = true)
|-- state: integer (nullable = true)
|-- cardholder: integer (nullable = true)
|-- balance: integer (nullable = true)
|-- numTrans: integer (nullable = true)
|-- numIntlTrans: integer (nullable = true)
|-- creditLine: integer (nullable = true)
|-- fraudRisk: integer (nullable = true)
fraud_df.groupby('gender').count().show()
+------+-------+
|gender| count|
+------+-------+
| 1|6178231|
| 2|3821769|
+------+-------+
对于真正的数值特征,使用.describe()方法:
.show()方法生成结果:
numerical = ['balance', 'numTrans', 'numIntlTrans']
desc = fraud_df.describe(numerical)
desc.show()
+-------+-----------------+------------------+-----------------+
|summary| balance| numTrans| numIntlTrans|
+-------+-----------------+------------------+-----------------+
| count| 10000000| 10000000| 10000000|
| mean| 4109.9199193| 28.9351871| 4.0471899|
| stddev|3996.847309737258|26.553781024523122|8.602970115863904|
| min| 0| 0| 0|
| max| 41485| 100| 60|
+-------+-----------------+------------------+-----------------+
即使是从这些相对较少的数字中,可以看出:
- 所有的特征都呈正偏态;最大值是平均值的多倍
- 变异系数(均值与标准差之比)非常高(接近或者大于1),意味着这是一个广泛的观测数据
如何检查偏度:
fraud_df.agg({'balance' : 'skewness'}).show()
+------------------+
| skewness(balance)|
+------------------+
|1.1818315552993839|
+------------------+
列表中的聚合函数包括:avg(),count(),countDistinct(),first(),kurtosis(),max(),mean(),min(),skewness(),stddev(),stddev_pop(),stddev_samp(),sum(),sumDistinct(),var_pop(),var_samp()和variance()
相关性
特征之间相互关系的另一个非常有用的度量是相关性。
检查特征之间的相关性同样重要,包括它们之间高度相关的特征(即共性(collinear)),可能会导致模型的不可预知行为或者可能进行不必要的复杂化。
DataFrame形式,运用Pyspark计算相关性非常容易。唯一困难的是.corr()方法支持Pearson相关性系数,并且只能计算两两相关性:
fraud_df.corr('balance', 'numTrans')
# 创建相关矩阵
n_numerical = len(numerical)
corr = []
for i in range(0, n_numerical):
temp = [None] * i
for j in range(i, n_numerical):
temp.append(fraud_df.corr(numerical[i], numerical[j]))
corr.append(temp)
corr
[[1.0, 0.0004452314017265386, 0.0002713991339817875],
[None, 1.0, -0.0002805712819816554],
[None, None, 1.0]]
可视化
使用matplotlib和Bokeh
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('ggplot')
from bokeh.io import output_notebook
output_notebook()
%matplotlib inline、output_notebook()命令分别会使matplotlib或者Boken生成每个图表
直方图
直方图是迄今位置最容易直观地计算显示特征分布的方法。pyspark有三种方法可以生成直方图:
- 聚集工作节点中的数据并返回一个汇总bins列表和直方图每个bin中的计数给驱动程序
- 返回所有的数据给驱动程序,并且允许用绘图库的方法完成这项工作
- 对数据进行采样,然后给他们返回给驱动程序进行绘图
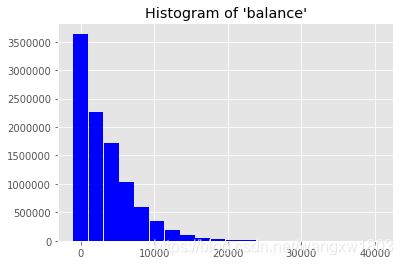
hists = fraud_df.select('balance').rdd.flatMap(
lambda row: row).histogram(20)
# 绘制直方图,可以使用matplotlib
data = {
'bins' : hists[0][:-1],
'freq' : hists[1]
}
plt.bar(data['bins'], data['freq'], width=2000,color='blue')
plt.title('Histogram of \'balance\'')
Text(0.5,1,"Histogram of 'balance'")
data_driver = {
'obs' : fraud_df.select('balance').rdd.flatMap(
lambda row: row
).collect()
}
plt.hist(data_driver['obs'],bins=20)
plt.title('Histogram of \'balance\'using .hist()')
Text(0.5,1,"Histogram of 'balance'using .hist()")

特征之间的交互
散点图能够一次可视化多达三个变量间的交互