R语言中提供了许多用来整合和重塑数据的强大方法。
- 整合 aggregate
- 重塑 reshape
在整合数据时,往往将多组观测值替换为根据这些观测计算的描述统计量。
在重塑数据时,则会通过修改数据的结构(行与列)来决定数据的组织方式。
样例数据:mtcars
从Motor Trend杂志(1974)提取的,它描述了34种车型的设计和性能特点(气缸数、排量、马力、每加仑汽油行驶的英里数,等等,详细可使用help(mtcars)。
一、转置
反转行和列,使用函数t()即可对一个矩阵或数据框进行转置。
cars <- mtcars[1:5,1:4]
> cars
mpg cyl disp hp
Mazda RX4 21.0 6 160 110
Mazda RX4 Wag 21.0 6 160 110
Datsun 710 22.8 4 108 93
Hornet 4 Drive 21.4 6 258 110
Hornet Sportabout 18.7 8 360 175
t(cars)
> t(cars)
Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive Hornet Sportabout
mpg 21 21 22.8 21.4 18.7
cyl 6 6 4.0 6.0 8.0
disp 160 160 108.0 258.0 360.0
hp 110 110 93.0 110.0 175.0
二、整合数据
在R中使用一个或者多个by变量和一个预先定义好的函数来折叠(collapse)数据。
调用格式:
aggregate(x, by, FUN)
- x:数据对象
- by:变量名组成的列表
- FUN:用来计算描述性统计量的标量函数
示例:根据气缸数和档位数整合mtcars数据,并返回各个数值型变量的均值。
options(digits = 3) # 修改小数点后的精确位数
attach(mtcars) # 加载进内存
aggdata <- aggregate(mtcars, by = list(cyl,gear), FUN = mean, na.rm = TRUE)
aggdata
detach(mtcars) # 从内存删除
> aggdata
Group.1 Group.2 mpg cyl disp hp drat wt qsec vs am gear carb
1 4 3 21.5 4 120 97 3.70 2.46 20.0 1.0 0.00 3 1.00
2 6 3 19.8 6 242 108 2.92 3.34 19.8 1.0 0.00 3 1.00
3 8 3 15.1 8 358 194 3.12 4.10 17.1 0.0 0.00 3 3.08
4 4 4 26.9 4 103 76 4.11 2.38 19.6 1.0 0.75 4 1.50
5 6 4 19.8 6 164 116 3.91 3.09 17.7 0.5 0.50 4 4.00
6 4 5 28.2 4 108 102 4.10 1.83 16.8 0.5 1.00 5 2.00
7 6 5 19.7 6 145 175 3.62 2.77 15.5 0.0 1.00 5 6.00
8 8 5 15.4 8 326 300 3.88 3.37 14.6 0.0 1.00 5 6.00
在使用aggregate()函数的时候,by中的变量必须在一个列表中(即使只有一个变量),指定的函数可为任意的内建或自编函数。
三、reshape包
reshape包是一套重构和整合数据集的万能工具。
install.packages("reshape")
library(reshape)
- 将数据“融合”(melt),使得每一行都是一个唯一的标识符-变量组合。
- 将数据“重铸”(cast),变成任意想要的形状。
mydata <- data.frame(
ID = c(1,1,2,2),
Time = c(1,2,1,2),
X1 = c(5,3,6,2),
X2 = c(6,5,1,4)
)
测量(measurement)指最后两列的值。
1.融合
每个测量变量独占一行,行中带有要唯一确定这个测量所需要的标识符变量。
md <- melt(mydata, id = c("ID","Time"))
> melt(mydata, id = c("ID","Time"))
ID Time variable value
1 1 1 X1 5
2 1 2 X1 3
3 2 1 X1 6
4 2 2 X1 2
5 1 1 X2 6
6 1 2 X2 5
7 2 1 X2 1
8 2 2 X2 4
必须指定要唯一确定每个测量所需要的变量。现在可以使用cast()函数重铸为任意形状。
2.重铸(reshape包cast,reshape不提供cast)
cast()函数读取已融合的数据,并使用提供的公式和一个(可选的)用于整合数据的函数将其重塑。调用格式为:
newdata <- cast(x, formula, FUN)
formula : row1 + row2 ~ col1 + col2
- row:定义要划掉的变量集合,确定各行的内容
- col:定义要划掉、确定各列内容的变量集合
> cast(md,ID ~ variable, mean)
ID X1 X2
1 1 4 5.5
2 2 4 2.5
> cast(md, Time ~ variable, mean)
Time X1 X2
1 1 5.5 3.5
2 2 2.5 4.5
> cast(md, ID ~ Time, mean)
ID 1 2
1 1 5.5 4
2 2 3.5 3
> cast(md, ID + Time ~ variable) # 不执行整合
ID Time X1 X2
1 1 1 5 6
2 1 2 3 5
3 2 1 6 1
4 2 2 2 4
> cast(md, ID + variable ~ Time)
ID variable 1 2
1 1 X1 5 3
2 1 X2 6 5
3 2 X1 6 2
4 2 X2 1 4
缺少FUN时,数据仅被重塑,而不被整合。
四、reshape2包
Hadley Wickham大神写了很多R语言包,包括ggplot2、plyr、reshape/reshape2等。
reshape2中主要使用函数:melt、acast、dcast等。
- melt : 拆分数据(会自动根据数据类型:data.frame、array、list选择函数进行实际操作)
1.数组(array)类型
依次对各维度的名称进行组合将数据进行线性/向量化。如果数据有N维,得到的结果共有N+1列,前N列记录数组的位置信息,最后一列才是观测值。
datax <- array(1:8, dim = c(2,2,2))
> melt(datax)
X1 X2 X3 value
1 1 1 1 1
2 2 1 1 2
3 1 2 1 3
4 2 2 1 4
5 1 1 2 5
6 2 1 2 6
7 1 2 2 7
8 2 2 2 8
> melt(datax, varnames = LETTERS[24:26], value.name = "Val")
X Y Z value
1 1 1 1 1
2 2 1 1 2
3 1 2 1 3
4 2 2 1 4
5 1 1 2 5
6 2 1 2 6
7 1 2 2 7
8 2 2 2 8
2.列表(list)类型
将列表中的数据拉成两列,一列记录列表元素的值,另一列记录列表元素的名称。如果列表中的元素是列表,则增加列变量存储元素名称。元素值排列在前,名称在后,越是顶级的列表元素名称越靠后。
datax <- list(
agi="AT1G10000",
go=c("GO:1000","GO:2000"),
kegg=c("0100","0200","0300")
)
> melt(datax)
value L1
1 AT1G10000 agi
2 GO:1000 go
3 GO:2000 go
4 0100 kegg
5 0200 kegg
6 0300 kegg
> melt(list(at_0441=datax))
value L2 L1
1 AT1G10000 agi at_0441
2 GO:1000 go at_0441
3 GO:2000 go at_0441
4 0100 kegg at_0441
5 0200 kegg at_0441
6 0300 kegg at_0441
3.数据框(data.frame)类型
melt(data, id.vars, measure.vars,
variable.name = "xxx",
value.name = "yyy",
na.rm = FALSE)
- id.vars:维度的列变量,在结果中占一列
- measure.vars:观测值的列变量,名称和值分别组成variable和value两列
- variable.name & value.name 列变量名称
> str(airquality)
'data.frame': 153 obs. of 6 variables:
$ Ozone : int 41 36 12 18 NA 28 23 19 8 NA ...
$ Solar.R: int 190 118 149 313 NA NA 299 99 19 194 ...
$ Wind : num 7.4 8 12.6 11.5 14.3 14.9 8.6 13.8 20.1 8.6 ...
$ Temp : int 67 72 74 62 56 66 65 59 61 69 ...
$ Month : int 5 5 5 5 5 5 5 5 5 5 ...
$ Day : int 1 2 3 4 5 6 7 8 9 10 ...
> head(airquality)
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
按月份分析臭氧和太阳辐射、风速、温度三者之间的关系,可以转化:
> aq <- melt(airquality,
+ id = c("Ozone","Month","Day"),
+ measure = c(2:4),
+ variable.name = "V.type",
+ value.name = "value")
> head(aq) # id.vars/var.ids/id 都可以
Ozone Month Day variable value
1 41 5 1 Solar.R 190
2 36 5 2 Solar.R 118
3 12 5 3 Solar.R 149
4 18 5 4 Solar.R 313
5 NA 5 5 Solar.R NA
6 28 5 6 Solar.R NA
id和measure两个参数可以只指定其中一个,剩余的列被当成另外一个参数的值。如果两个都省略,数值型的列被看成观测值,其他的被当成id。如果想省略参数或者去掉部分数据,参数名最好用 id/measure,否则得到的结果可能不理想。
最好使用id=1之类的来定义。
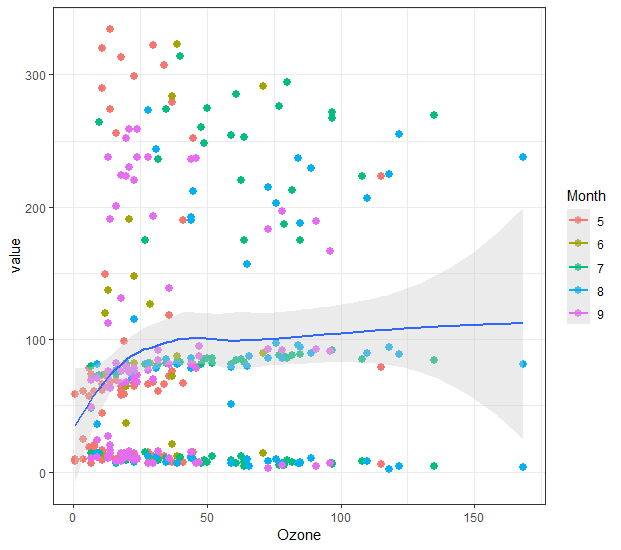
melt以后的数据,称为molten数据,用ggplot2做统计图就很方便,可以快速做出我们需要的图形,例如:
library(ggplot2)
str(aq)
aq$Month <- factor(aq$Month)
p <- ggplot(data = aq,
aes(x = Ozone, y = value, color = Month)) + theme_bw()
p + geom_point(shape = 20, size = 4) +
geom_smooth(aes(group = 1),fill = "gray80") +
facet_wrap(~ V.type, scales="free_y")
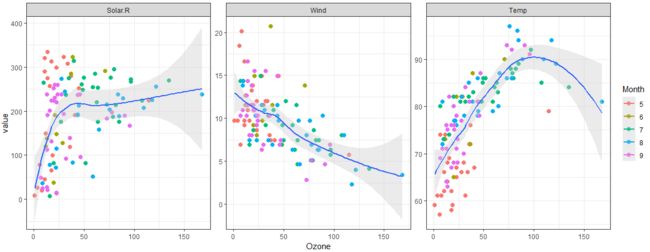
melt获得的数据(molten data)可以使用acast或dcast还原。
- acast:获得数组
- dcast:获得数据框
公式左边每个变量都会作为结果的一列,而右边的变量被当成因子类型,每个水平都会在结果中产生一列。
> head(dcast(aq, Ozone+Month+Day ~ variable))
Ozone Month Day Solar.R Wind Temp
1 1 5 21 8 9.7 59
2 4 5 23 25 9.7 61
3 6 5 18 78 18.4 57
4 7 5 11 NA 6.9 74
5 7 7 15 48 14.3 80
6 7 9 24 49 10.3 69
dcast函数的作用不止是还原数据,还可以使用函数对数据进行汇总(aggregate)。
> dcast(aq, Month ~ variable,fun.aggregate=mean,na.rm=TRUE)
Month Solar.R Wind Temp
1 5 181 11.62 65.5
2 6 190 10.27 79.1
3 7 216 8.94 83.9
4 8 172 8.79 84.0
5 9 167 10.18 76.9
END 2018-10-30 00:07:24