2019独角兽企业重金招聘Python工程师标准>>> 
最近线上一个服务又出现了频繁Full GC的情况,导致提供的业务经常超时。问题出现非常不稳定,经过两周的时候,终于又捕捉到了一次Full GC,于是联系运维做Heap Dump之后,经过一系列分析,终于解决问题。这次的问题稍微复杂一点,但是也比较有代表性,用到了VisualVM和MAT两个工具,继续记录如下。
现象
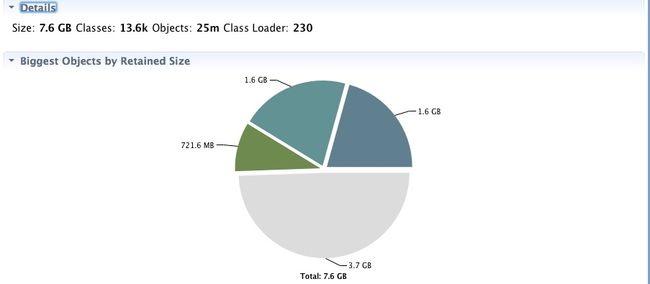
这次使用公司的CAT监控平台看到的内存表现如下:
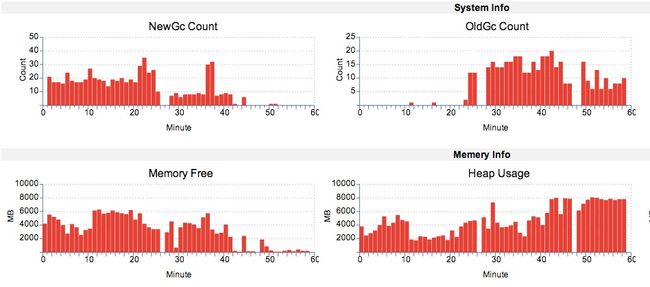
可以看到,具体表现是:
- 在很长一段时间内(数个小时),New GC比较频繁,Full GC较少(一小时个位数)。
- 过了某一时间点后,Full GC增加,New GC则减少。
- 将服务切换下线后,Memory Free逐渐回升,Full GC减少。
然后观察某一时刻的JMAP histo的内容如下:
num #instances #bytes class name
----------------------------------------------
1: 5958517 5840833584 [C
2: 37983 706246056 [B
3: 5960539 190737248 java.lang.String
4: 1522282 126603936 [Ljava.lang.Object;
5: 3692000 88608000 java.lang.Double
可以看到"[C"即"char[]"占用内存达到了5.8G,它正是String的内部结构,换句话说,因为存在了大量的大String导致这个问题。
联系运维进行了Heap Dump之后,就开始了分析的过程。因为服务器内存有8G,所以相应的DUMP也有8G,对分析也造成了一点小困难。
下面是一些工具的使用过程,操作系统是OS X 10.8。
使用VisualVM分析
首先使用VisualVM对Heap Dump进行分析。分析需要比较大的内存,而VisualVM默认的内存是256M,所以需要先设置/Applications/VisualVM.app/Contents/Resources/visualvm/etc/visualvm.conf中的最大内存量,这里我们设置成了4G-J-Xmx4096m。
好了,现在打开dump文件,整个分析过程共占用内存2G,仍然在可接受范围。之后分析内存,可以看到跟之前histo一样的类关系。

不同的是,这时候可以点进去,查看具体的对象。这里看到,竟然有几个大的String占用了756M的内存,看来我们找到问题了。
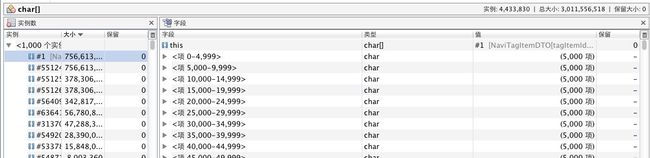
发现一个奇怪的现象:“计算保留大小”之后,这些String的保留大小都是0。
保留大小是什么呢?
它是分析工具从GC roots开始查找,找到的所有不会回收的对象,然后按照引用关系,计算出这个“对象以及它引用的对象”的内存大小。这里很有趣的是,这些对象的保留大小都是0。
开始我甚至以为是工具出了问题,后来想想,其实答案很简单:这些大String是临时对象,没有什么对象持有它——通过分析这些String的依赖关系也说明了这一点。这些对象是可以被回收的,换句话说,并不是有明显的内存泄露。
这个“没有对象持有的String”很有意思,让我想到了,会不会是log的过程中,产生了这个String?因为log的时候,会调用对象的toString()方法,而一个大对象的toString()可能是很大的。查看了一下String的内容,是[Class[field1=xxx,field2=yyy]]这种结构,几乎可以肯定是toString()的结果,那么我们现在只要查看一下具体的内容,到底是哪里太大就可以了。
可惜的是,VisualVM里我尝试了各种方法,都没有办法Dump出这个对象的数据,甚至还尝试了VisualVM提供的OQL。
OQL是一种类SQL的表达式,同时整合了一些Javascript的函数功能,但是它的缺点就是太慢了…最后尝试用OQL Dump对象未果。
使用MAT分析
转而尝试一下MAT。Eclipse MAT(Memory Analyzer Tool)是一个强大的内存分析工具,它可以方便的分析内存泄露的问题。实际使用之后,确实也感觉到比VisualVM更加强大一些。
我们使用MAT打开Dump文件,这也是一个漫长的过程。与VisualVM不同的是,MAT分析的时候,会在本地产生几个临时文件保存分析结果,所以相应的内存占用会小一些(1G左右),第二次打开也会快很多。
打开完成后,我们看到可以看到几个占用内存较大的对象,这就是最可疑的内存泄漏源。意外的是Size显示的只有1.3GB,而且我们的大String都没在里面。
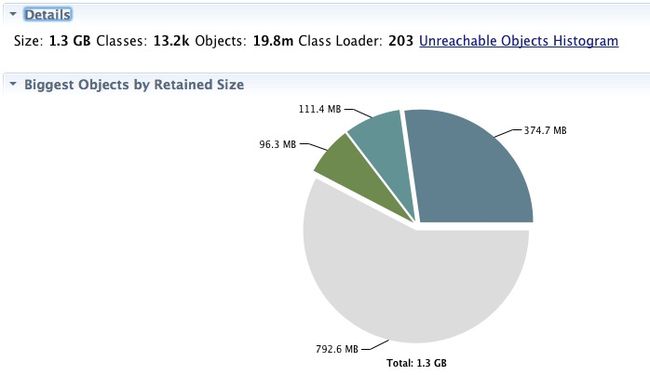
开始我们一度认为是Dump文件有错,后来上网搜索才知道,因为MAT的主要目标是排查内存占用量,所以默认大小是不计算不可达对象的——而我们的String都是不可达对象。对应Eclipse的文档里有介绍http://wiki.eclipse.org/MemoryAnalyzer/FAQ#How_to_analyse_unreachable_objects。
于是我们按照说明,在"Preferences=>Memory Analyzer"中勾选"Keep Unreachable Objects",删除索引文件Dump同路径下的所有".index",即可看到所有的对象。
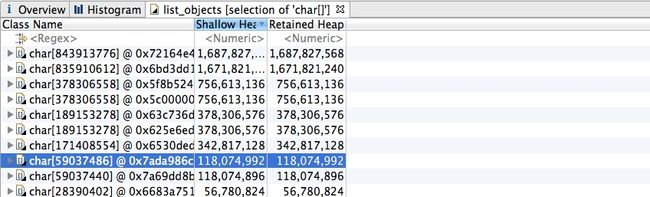
点击Histogram,即可看到类的占用。在类上选择"List Objects",即可看到所有对象。在对象上选择"Copy=>Value to File",即可保存到文件。
原理
之后我们通过分析对象,发现是因为某个用于缓存的对象使用了一个List结构,但是添加元素的没有去重,导致List越来越大造成的。这个对象本身占用内存只有110M,但是toString()出来的字符串达到700M的大小,所以引起了频繁的GC——最开始对象小的时候是New GC,后来对象大了,直接进入了年老代,就变成了Full GC。
总结
回到之前的问题,通过这次分析,我们可以这么总结:
-
将服务切换下线后,Memory Free逐渐回升,Full GC减少,Heap Dump的可达对象较少
这种情况不是内存泄露,有可能是对象创建开销太大造成的。
-
在1的前提下,New GC很频繁
这种情况可能是频繁创建小对象,或者创建一些较大的对象(尚不足以直接进入年老代)
-
在1的前提下,Full GC很频繁
这种情况是频繁创建大对象,或者创建了一些超大对象导致的。
-
第3种情况下,大对象toString()产生的大String很可能是罪魁祸首