Spark:实时数据微批处理(6.Spark内核解析)
文章目录
- 1.Spark 内核概述
- 1.1 Spark 核心组件回顾
- 1.1.1 Cluster Manager(Master, ResourceManager)
- 1.1.2 Worker(Worker, NodeManager)
- 1.1.3 Driver
- 1.1.4 Executor
- 1.1.5 Application
- 1.2 Spark 通用运行流程概述
- 2.Spark 通讯架构
- 2.1 Spark 通讯架构概述
- 2.1.1 Spark 内置 RPC 框架
- 2.1.2 Netty 通信架构
- 2.2 Spark Netty 通信架构解析
- 1.RpcEndpoint:RPC 端点。
- 2.RpcEnv: Rpc 上下文(Rpc 环境)
- 3.Dispatcher:消息分发器
- 4.Inbox:指令消息收件箱。
- 5.RpcEndpointRef:RpcEndpointRef 是对远程 RpcEndpoint 的一个引用。
- 6.OutBox:指令消息发件箱。
- 7.RpcAddress
- 8.TransportClient:Netty通信客户端
- 9.TransportServer:Netty 通信服务端
- 2.3 Spark集群启动流程分析
- 2.3.1 standalone模式分析集群启动脚本的流程
- 2.3.2 Master启动源码分析
- 2.3.3 Worker 启动源码分析
- 3.Spark 部署模式
- 3.1 Yarn 模式运行机制
- 3.1.1 YARN Cluster 模式
- 3.1.2 Yarn Client 模式
- 3.1.3 Yarn cluster 模式运行机制源码分析
- 1. bin/spark-submit 启动脚本分析
- 2. org.apache.spark.deploy.SparkSubmit 源码分析
- 3. org.apache.spark.deploy.yarn.Client 源码分析
- 4. org.apache.spark.deploy.yarn.ApplicationMaster 源码分析
- 5.org.apache.spark.executor.CoarseGrainedExecutorBackend 源码分析
- 6.总结
- 3.1.4 Yarn client 模式运行机制源码分析
- 1.client 模式下直接运行用户的主类:
- 2.实例化SparkContext
- 3.org.apache.spark.deploy.yarn.Client 源码再分析
- 4.ApplicationMaster 源码再分析
- 5.总结
- 3.1.5 Yarn cluster 和 client的总结
- 3.2 Standalone 模式运行机制
- 3.2.1 Standalone Cluster 模式
- 3.2.2 Standalone Client 模式
- 4.Spark 任务调度机制
- 4.1 Spark 任务调度概述
- 4.2 Spark Stage 级别调度
- 4.3 Spark Task 级别调度
- 4.3.1 调度策略
- 4.3.2 本地化调度
- 4.3.3 失败重试和黑名单
- 4.4 Stage 级别任务调度源码分析
- 1.SparkContext初始化
- 2.RDD 类源码分析
- 3.DAGScheduler类源码分析
- 4.TaskScheduler类源码分析
- 5.CoarseGrainedExecutorBackend 源码分析
- 4.5 Task 级别任务调度源码分析
- 1.SchedulableBuilder(调度池构建器)
- 2.SchedulingAlgorithm(调度算法)
- 5. Spark Shuffle 解析
- 5.1 Shuffle 的核心要点
- 5.1.1 Shuffle 流程源码分析
- 1.ShuffleMapTask源码分析
- 2.ShuffleManager
- 5.2 HashShuffle 解析
- 5.2.1 未优化的HashShuffle
- 5.2.2 优化的HashShuffle
- 5.3 SortShuffle 解析
- 5.3.1 普通 SortShuffle
- 5.3.2 bypassSortShuffle
- 5.3.3 普通 SortShuffle 源码解析
- 5.3.4 bypass SortShuffle 源码解析
- 6.Spark 内存管理
- 6.1 堆内和堆外内存规划
- 1.内存池:
- 2.堆内内存
- 3. 堆外内存
- 6.2 内存空间分配
- 6.2.1 静态内存管理(Static Memory Manager)
- 6.2.2 统一内存管理(Unified Memory Manager)
- 6.3 存储内存管理
- 6.3.1 RDD 的持久化机制
- 6.3.2 RDD 的缓存过程
- 6.3.3 淘汰和落盘
- 6.4 执行内存管理
- 6.4.1 多任务内存分配
- 6.4.2 Shuffle 的内存占用
1.Spark 内核概述
Spark 内核泛指 Spark 的核心运行机制
包括 Spark 核心组件的运行机制、Spark 任务调度机制、Spark 内存管理机制、Spark 核心功能的运行原理等
1.1 Spark 核心组件回顾
1.1.1 Cluster Manager(Master, ResourceManager)
Spark 的集群管理器, 主要负责对整个集群资源的分配与管理.
- Cluster Manager 在 Yarn 部署模式下为 ResourceManager;
- 在 Mesos 部署模式下为 Mesos Master;
- 在 Standalone 部署模式下为 Master.
Cluster Manager 分配的资源属于一级分配, 它将各个 Worker 上的内存, CPU 等资源分配给 Application, 但并不负责对 Executor 的资源的分配.
1.1.2 Worker(Worker, NodeManager)
Spark 的工作节点.
在 Yarn 部署模式下实际由 NodeManager (守护进程 )替代.
主要负责以下工作:
- 将自己的内存, CPU 等资源通过注册机制告知 Cluster Manager
- 创建 Executor进程
- 将资源和任务进一步分配给 Executor
- 同步资源信息, Executor 状态信息给 ClusterManager 等.
1.1.3 Driver
Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。
Driver 在 Spark 作业执行时主要负责:
- 将用户程序转化为作业(Job);
- 在 Executor 之间调度任务(Task);
- 跟踪 Executor 的执行情况;
- 通过 UI 展示查询运行情况;
1.1.4 Executor
Spark Executor 节点是负责在 Spark 作业中运行具体任务,任务彼此之间相互独立。
Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。
如果有 Executor 节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor 节点上继续运行。
Executor 有两个核心功能:
- 负责运行组成 Spark 应用的任务,并将结果返回给驱动器(Driver);
- 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 的数据是直接缓存在 Executor 进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
1.1.5 Application
用户使用 Spark 提供的 API 编写的应用程序.
- Application 通过 Spark API 将进行 RDD 的转换和 DAG 的构建, 并通过 Driver 将 Application 注册到 Cluster Manager.
- Cluster Manager 将会根据 Application 的资源需求, 通过一级分配将 Executor, 内存, CPU 等资源分配给 Application.
- Driver 通过二级分配将 Executor 等资源分配给每一个任务, Application 最后通过 Driver 告诉 Executor 运行任务
1.2 Spark 通用运行流程概述
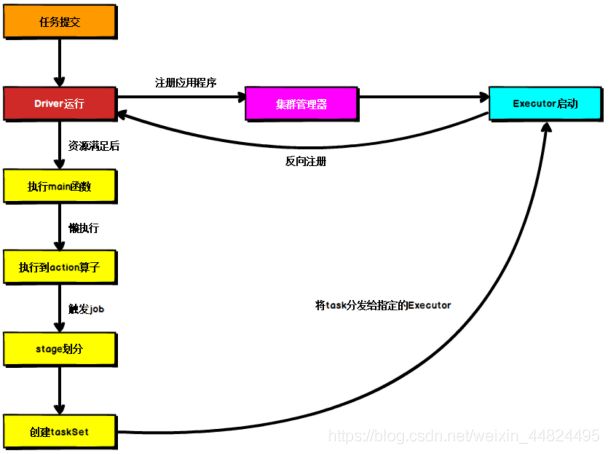
上图为 Spark 通用运行流程,不论 Spark 以何种模式进行部署,都是以如下核心步骤进行工作的:
- 任务提交后,都会先启动 Driver 程序;
- 随后 Driver 向集群管理器注册应用程序;
- 之后集群管理器根据此任务的配置文件分配 Executor 并启动该应用程序;
- 当 Driver 所需的资源全部满足后,Driver 开始执行 main 函数,Spark 转换为懒执行,当执行到 Action 算子时开始反向推算,根据宽依赖进行 Stage 的划分,随后每一个 Stage 对应一个 Taskset,Taskset 中有多个Task;
根据本地化原则,Task 会被分发到指定的 Executor 去执行,在任务执行的过程中,Executor 也会不断与 Driver 进行通信,报告任务运行情况。
2.Spark 通讯架构
2.1 Spark 通讯架构概述
2.1.1 Spark 内置 RPC 框架
在 Spark 中, 很多地方都涉及到网络通讯, 比如 Spark 各个组件间的消息互通, 用户文件与 Jar 包的上传, 节点间的 Shuffle 过程, Block 数据的复制与备份等.
1.在 Spark0.x.x 与 Spark1.x.x 版本中, 组件间的消息通信主要借助于 Akka.
2.在 Spark1.3 中引入了 Netty 通信框架. Akka要求message发送端和接收端有相同的版本, 所以为了避免 Akka 造成的版本问题,并给用户的应用更大灵活性,决定使用更通用的 RPC 实现,也就是现在的 Netty 来替代 Akka。
3.Spark1.6 中 Akka 和 Netty 可以配置使用。Netty 完全实现了 Akka 在Spark 中的功能。
4.从Spark2.0.0, Akka 被移除.
Actor 模型:
2.1.2 Netty 通信架构
Netty 借鉴了 Akka 的 Actor 模型
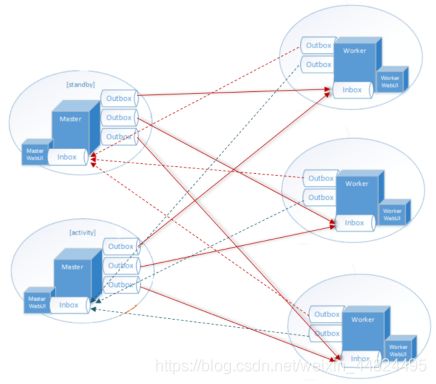
Spark通讯框架中各个组件(Client/Master/Worker)可以认为是一个个独立的实体,各个实体之间通过消息来进行通信。
具体各个组件之间的关系图如下:
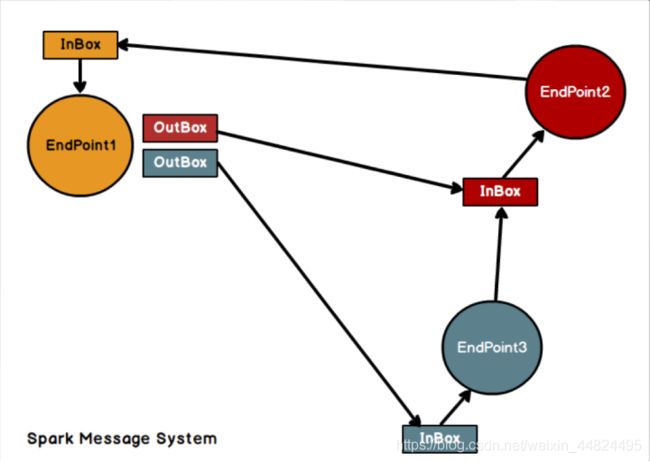
Endpoint(Client/Master/Worker)有 1 个 InBox 和 N 个 OutBox(N>=1,N取决于当前 Endpoint 与多少其他的 Endpoint 进行通信,一个与其通讯的其他Endpoint 对应一个 OutBox),Endpoint 接收到的消息被写入 InBox,发送出去的消息写入 OutBox 并被发送到其他 Endpoint 的 InBox 中。
2.2 Spark Netty 通信架构解析
Netty 官网: https://netty.io/
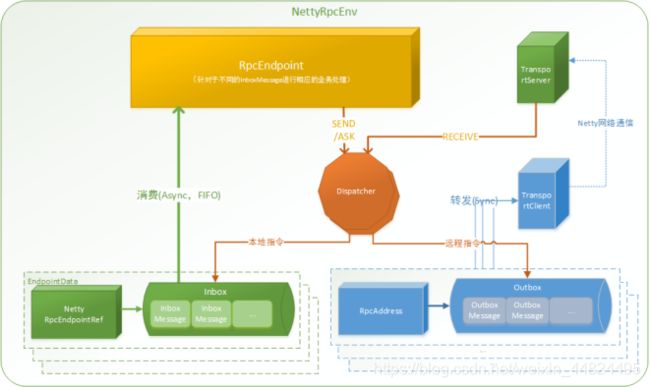
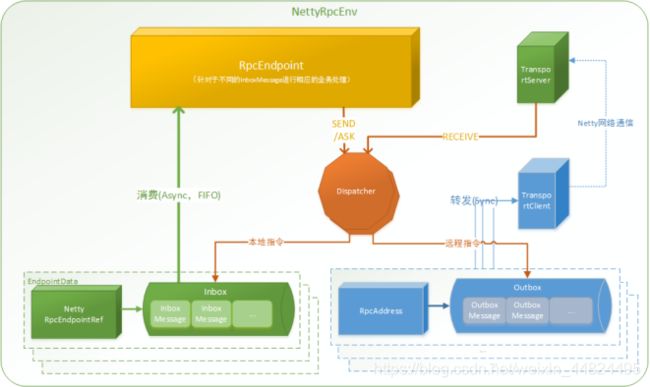
1.RpcEndpoint:RPC 端点。
Spark 针对每个节点(Client/Master/Worker)都称之为一个 RpcEndpoint ,且都实现 RpcEndpoint接口,内部根据不同端点的需求,设计不同的消息和不同的业务处理,如果需要发送(询问)则内部调用 Dispatcher 的对应方法;
说明:
•RpcEndpoint 是用来接收消息.
•发送消息的使用RpcEndpointRef
•RpcEndpointRef的具体实现类是: NettyRpcEndpointRef
2.RpcEnv: Rpc 上下文(Rpc 环境)
每个RpcEndpoint运行时依赖的上下文环境称为 RpcEnv
3.Dispatcher:消息分发器
RPC 端点需要发送消息或者从远程 RPC 端点接收到的消息,分发至对应的指令收件箱/发件箱。
•如果指令接收方是自己则存入收件箱
•如果指令接收方不是自己则放入发件箱
// class NettyRpcEnv
private[netty] def send(message: RequestMessage): Unit = {
// 获取接收者地址信息
val remoteAddr = message.receiver.address
if (remoteAddr == address) {
// Message to a local RPC endpoint.
// 把消息发送到本地的 RPC 端点 (发送到收件箱)
try {
dispatcher.postOneWayMessage(message)
} catch {
case e: RpcEnvStoppedException => logWarning(e.getMessage)
}
} else {
// Message to a remote RPC endpoint.
// 把消息发送到远程的 RPC 端点. (发送到发件箱)
postToOutbox(message.receiver, OneWayOutboxMessage(serialize(message)))
}
}
4.Inbox:指令消息收件箱。
一个本地 RpcEndpoint 对应一个收件箱
5.RpcEndpointRef:RpcEndpointRef 是对远程 RpcEndpoint 的一个引用。
当我们需要向一个具体的 RpcEndpoint 发送消息时,一般我们需要获取到该RpcEndpoint 的引用,然后通过该引用发送消息。
6.OutBox:指令消息发件箱。
对于当前 RpcEndpoint 来说,一个目标 RpcEndpoint 对应一个当前的发件箱,如果向多个目标 RpcEndpoint 发送信息,则有当前会有多个 OutBox。当消息放入 Outbox 后,紧接着通过 TransportClient 将消息发送出去。消息放入发件箱以及发送过程是在同一个线程中进行;
7.RpcAddress
表示远程的RpcEndpointRef的地址,Host + Port。
8.TransportClient:Netty通信客户端
一个 OutBox 对应一个 TransportClient,TransportClient 不断轮询OutBox,根据 OutBox 消息的 receiver 信息,请求对应的远程 TransportServer;
9.TransportServer:Netty 通信服务端
一个 RpcEndpoint 对应一个 TransportServer,接受远程消息后调用 Dispatcher 分发消息至自己的收件箱,或者对应的发件箱;
高层俯视图:
2.3 Spark集群启动流程分析
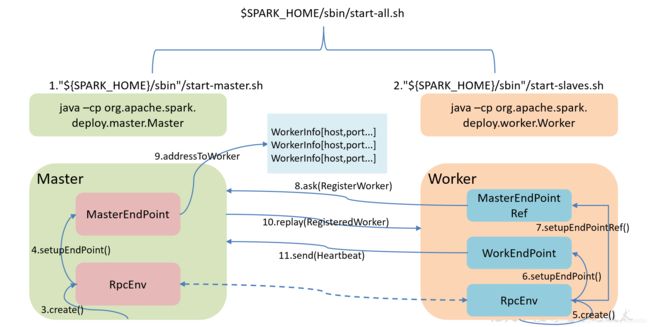
- start-all.sh脚本,实际是执行java -cp Master和java -cp Worker;
- Master启动时首先创建一个RpcEnv对象,负责管理所有通信逻辑;
- Master通过RpcEnv对象创建一个Endpoint,Master就是一个Endpoint,Worker可以与其进行通信;
- Worker启动时也是创建一个RpcEnv对象;
- Worker通过RpcEnv对象创建一个Endpoint;
- Worker通过RpcEnv对象建立到Master的连接,获取到一个RpcEndpointRef对象,通过该对象可以与Master通信;
- Worker向Master注册,注册内容包括主机名、端口、CPU Core数量、内存数量;
- Master接收到Worker的注册,将注册信息维护在内存中的Table中,存储到三个集合中:workers,IdToWorker, adressToWork,其中还包含了一个到Worker的RpcEndpointRef对象引用;
9.Master回复Worker已经接收到注册,告知Worker已经注册成功;
Worker端收到成功注册响应后,开始周期性向Master发送心跳。
2.3.1 standalone模式分析集群启动脚本的流程
启动:
sbin/start-all.sh
# Start Master
"${SPARK_HOME}/sbin"/start-master.sh
CLASS="org.apache.spark.deploy.master.Master" //启动master就是启动这个类
"${SPARK_HOME}/sbin"/spark-daemon.sh start $CLASS 1 \
--host $SPARK_MASTER_HOST \
--port $SPARK_MASTER_PORT \
--webui-port $SPARK_MASTER_WEBUI_PORT \
$ORIGINAL_ARGS
$option=start
command=$1
run_command class "$@"
mode="$1" // mode=class
execute_command nice -n "$SPARK_NICENESS" "${SPARK_HOME}"/bin/spark-class "$command" "$@"
nohup -- "$@" >> $log 2>&1 < /dev/null &
CMD=("${CMD[@]:0:$LAST}")
exec "${CMD[@]}"
/opt/module/jdk1.8.0_144/bin/java
-cp /opt/module/spark-standalone/conf/:/opt/module/spark-standalone/jars/* -Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop102:2181,hadoop103:2181,hadoop104:2181 -Dspark.deploy.zookeeper.dir=/spark1128 -Xmx1g
org.apache.spark.deploy.master.Master
--host hadoop102 --port 7077 --webui-port 8080
# Start Workers
"${SPARK_HOME}/sbin"/start-slaves.sh
2.3.2 Master启动源码分析
val rpcEnv: RpcEnv = RpcEnv.create(SYSTEM_NAME, host, port, conf, securityMgr) // ->
本质是 NettyRpcEnv
val masterEndpoint: RpcEndpointRef = rpcEnv.setupEndpoint(ENDPOINT_NAME,
new Master(rpcEnv, rpcEnv.address, webUiPort, securityMgr, conf)) //->
//生命周期
The life-cycle of an endpoint is:
constructor -> onStart -> receive* -> onStop
// java中的线程池 只能跑一个后台线程的线程池
private val forwardMessageThread: ScheduledExecutorService =
ThreadUtils.newDaemonSingleThreadScheduledExecutor("master-forward-message-thread")
// 传递的线程, 会没隔60s执行一次!
checkForWorkerTimeOutTask = forwardMessageThread.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(CheckForWorkerTimeOut) // 自己给自己发送信息
}
}, 0, WORKER_TIMEOUT_MS, TimeUnit.MILLISECONDS)
0: 延迟执行的时间
WORKER_TIMEOUT_MS:执行频率
timeOutDeadWorkers()
// 所有注册成功的worker
val workers = new HashSet[WorkerInfo]
// 每60秒判断一次work是否超时(失联60s), 如果超时, 则异常. 通过上次的心跳时间来确定
总结:
每60秒判断一次work是否超时(失联60s), 如果超时, 则异常. 通过上次的心跳时间来确定
2.3.3 Worker 启动源码分析
opt/module/jdk1.8.0_144/bin/java
-cp /opt/module/spark-standalone/conf/:/opt/module/spark-standalone/jars/*
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop102:2181,hadoop103:2181,hadoop104:2181
-Dspark.deploy.zookeeper.dir=/spark1128 -Xmx1g
org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://hadoop102:7077
org.apache.spark.deploy.worker.Worke
// 向master注册worker
registerWithMaster()
// 尝试去向master注册, 但是有可能注册失败.
// 比如master还没有启动成功, 或者网络有问题
registerMasterFutures = tryRegisterAllMasters()
masterRpcAddresses.map { masterAddress =>
// 从线程池中启动线程来执行 Worker 向 Master 注册
registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = {
try {
logInfo("Connecting to master " + masterAddress + "...")
// 根据 Master 的地址得到一个 Master 的 RpcEndpointRef, 然后就可以和 Master 进行通讯了.
val masterEndpoint: RpcEndpointRef = rpcEnv.setupEndpointRef(masterAddress, Master.ENDPOINT_NAME)
// 向 Master 注册
registerWithMaster(masterEndpoint)
} catch {
case ie: InterruptedException => // Cancelled
case NonFatal(e) => logWarning(s"Failed to connect to master $masterAddress", e)
}
}
})
}
registerWithMaster(masterEndpoint)
masterEndpoint.ask[RegisterWorkerResponse](RegisterWorker(
workerId, host, port, self, cores, memory, workerWebUiUrl))
给master发送信息:
RegisterWorker
注册成功:
private val HEARTBEAT_MILLIS = conf.getLong("spark.worker.timeout", 60) * 1000 / 4
sendToMaster(Heartbeat(workerId, self))
3.Spark 部署模式
Spark支持3种集群管理器(Cluster Manager),分别为:
- Standalone:独立模式,Spark 原生的简单集群管理器,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统,使用 Standalone 可以很方便地搭建一个集群;
- Hadoop YARN:统一的资源管理机制,在上面可以运行多套计算框架,如 MR、Storm等。根据 Driver 在集群中的位置不同,分为 yarn client 和 yarn cluster;
- Apache Mesos:一个强大的分布式资源管理框架,它允许多种不同的框架部署在其上,包括 Yarn。
实际上,除了上述这些通用的集群管理器外,Spark 内部也提供了方便用户测试和学习的简单集群部署模式。由于在实际生产环境下使用的绝大多数的集群管理器是 Hadoop YARN,因此我们关注的重点是 Hadoop YARN 模式下的 Spark 集群部署。
3.1 Yarn 模式运行机制
3.1.1 YARN Cluster 模式

- 执行脚本提交任务,实际是启动一个 SparkSubmit 的 JVM 进程;
- SparkSubmit 类中的 main方法反射调用Client的main方法;
- Client创建Yarn客户端,然后向Yarn发送执行指令:bin/java ApplicationMaster;
- Yarn框架收到指令后会在指定的NM中启动ApplicationMaster;
- ApplicationMaster启动Driver线程,执行用户的作业;
- AM向RM注册,申请资源;
- 获取资源后AM向NM发送指令:bin/java CoarseGrainedExecutorBacken;
- 启动ExecutorBackend, 并向driver注册.
- 注册成功后, ExecutorBackend会创建一个Executor对象.
- Driver会给ExecutorBackend分配任务, 并监控任务的执行.
注意:
- SparkSubmit、ApplicationMaster和CoarseGrainedExecutorBacken是独立的进程;
- Client和Driver是独立的线程;
- Executor是一个对象。
3.1.2 Yarn Client 模式
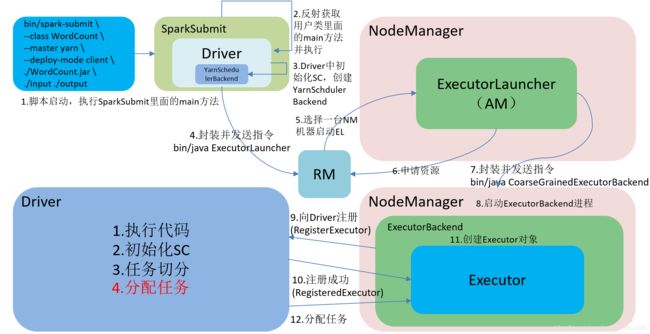
- 执行脚本提交任务,实际是启动一个SparkSubmit的 JVM 进程;
- SparkSubmit伴生对象中的main方法反射调用用户代码的main方法;
- 启动Driver线程,执行用户的作业,并创建ScheduleBackend;
- YarnClientSchedulerBackend向RM发送指令:bin/java ExecutorLauncher;
- Yarn框架收到指令后会在指定的NM中启动ExecutorLauncher(实际上还是调用ApplicationMaster的main方法);
object ExecutorLauncher {
def main(args: Array[String]): Unit = {
ApplicationMaster.main(args)
}
}
6. AM向RM注册,申请资源;
7. 获取资源后AM向NM发送指令:bin/java CoarseGrainedExecutorBacken;
8. 后面和cluster模式一致
注意:
- SparkSubmit、ExecutorLauncher和CoarseGrainedExecutorBacken是独立的进程;
- driver不是一个子线程,而是直接运行在SparkSubmit进程的main线程中, 所以sparkSubmit进程不能退出.
3.1.3 Yarn cluster 模式运行机制源码分析
启动下面的代码:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.11-2.1.1.jar \
1000
yarn 会按照下面的顺序依次启动了 3 个进程:
SparkSubmit
ApplicationMaster
CoarseGrainedExecutorB ackend
1. bin/spark-submit 启动脚本分析
启动类org.apache.spark.deploy.SparkSubmit
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
/bin/spark-class
exec "${CMD[@]}"
最终启动类:
/opt/module/jdk1.8.0_172/bin/java
-cp /opt/module/spark-yarn/conf/:/opt/module/spark-yarn/jars/*:/opt/module/hadoop-2.7.2/etc/hadoop/
org.apache.spark.deploy.SparkSubmit
--master yarn
--deploy-mode cluster
--class org.apache.spark.examples.SparkPi
./examples/jars/spark-examples_2.11-2.1.1.jar 100
2. org.apache.spark.deploy.SparkSubmit 源码分析
SparkSubmit伴生对象
main方法
def main(args: Array[String]): Unit = {
/*
参数
--master yarn
--deploy-mode cluster
--class org.apache.spark.examples.SparkPi
./examples/jars/spark-examples_2.11-2.1.1.jar 100
*/
val appArgs = new SparkSubmitArguments(args)
appArgs.action match {
// 如果没有指定 action, 则 action 的默认值是: action = Option(action).getOrElse(SUBMIT)
case SparkSubmitAction.SUBMIT => submit(appArgs)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}
submit 方法
/**
* 使用提供的参数提交应用程序
* 有 2 步:
* 1. 准备启动环境.
* 根据集群管理器和部署模式为 child main class 设置正确的 classpath, 系统属性,应用参数
* 2. 使用启动环境调用 child main class 的 main 方法
*/
@tailrec
private def submit(args: SparkSubmitArguments): Unit = {
// 准备提交环境 childMainClass = "org.apache.spark.deploy.yarn.Client"
val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args)
def doRunMain(): Unit = {
if (args.proxyUser != null) {
} else {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
}
if (args.isStandaloneCluster && args.useRest) {
// 在其他任何模式, 仅仅运行准备好的主类
} else {
doRunMain()
}
}
prepareSubmitEnvironment 方法
// In yarn-cluster mode, use yarn.Client as a wrapper around the user class
if (isYarnCluster) {
// 在 yarn 集群模式下, 使用 yarn.Client 来封装一下 user class
childMainClass = "org.apache.spark.deploy.yarn.Client"
}
doRunMain 方法
def doRunMain(): Unit = {
if (args.proxyUser != null) {
} else {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
}
runMain 方法
/**
*
* 使用给定启动环境运行 child class 的 main 方法
* 注意: 如果使用了cluster deploy mode, 主类并不是用户提供
*/
private def runMain(
childArgs: Seq[String],
childClasspath: Seq[String],
sysProps: Map[String, String],
childMainClass: String,
verbose: Boolean): Unit = {
var mainClass: Class[_] = null
try {
// 使用反射的方式加载 childMainClass = "org.apache.spark.deploy.yarn.Client"
mainClass = Utils.classForName(childMainClass)
} catch {
}
// 反射出来 Client 的 main 方法
val mainMethod = mainClass.getMethod("main", new Array[String](0).getClass)
if (!Modifier.isStatic(mainMethod.getModifiers)) {
throw new IllegalStateException("The main method in the given main class must be static")
}
try {
// 调用 main 方法.
mainMethod.invoke(null, childArgs.toArray)
} catch {
}
}
3. org.apache.spark.deploy.yarn.Client 源码分析
main方法
def main(argStrings: Array[String]) {
// 设置环境变量 SPARK_YARN_MODE 表示运行在 YARN mode
// 注意: 任何带有 SPARK_ 前缀的环境变量都会分发到所有的进程, 也包括远程进程
System.setProperty("SPARK_YARN_MODE", "true")
val sparkConf = new SparkConf
// 对传递来的参数进一步封装
val args = new ClientArguments(argStrings)
new Client(args, sparkConf).run()
}
Client.run方法
def run(): Unit = {
// 提交应用, 返回应用的 id
this.appId = submitApplication()
}
client.submitApplication 方法
/**
*
* 向 ResourceManager 提交运行 ApplicationMaster 的应用程序。
*
*/
def submitApplication(): ApplicationId = {
var appId: ApplicationId = null
try {
// 初始化 yarn 客户端
yarnClient.init(yarnConf)
// 启动 yarn 客户端
yarnClient.start()
// 从 RM 创建一个应用程序
val newApp = yarnClient.createApplication()
val newAppResponse = newApp.getNewApplicationResponse()
// 获取到 applicationID
appId = newAppResponse.getApplicationId()
reportLauncherState(SparkAppHandle.State.SUBMITTED)
launcherBackend.setAppId(appId.toString)
// Set up the appropriate contexts to launch our AM
// 设置正确的上下文对象来启动 ApplicationMaster
val containerContext = createContainerLaunchContext(newAppResponse)
// 创建应用程序提交任务上下文
val appContext = createApplicationSubmissionContext(newApp, containerContext)
// 提交应用给 ResourceManager 启动 ApplicationMaster
// "org.apache.spark.deploy.yarn.ApplicationMaster"
yarnClient.submitApplication(appContext)
appId
} catch {
}
}
方法: createContainerLaunchContext
private def createContainerLaunchContext(newAppResponse: GetNewApplicationResponse)
: ContainerLaunchContext = {
val amClass =
if (isClusterMode) { // 如果是 Cluster 模式
Utils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName
} else { // 如果是 Client 模式
Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName
}
amContainer
}
至此, SparkSubmit 进程启动完毕.
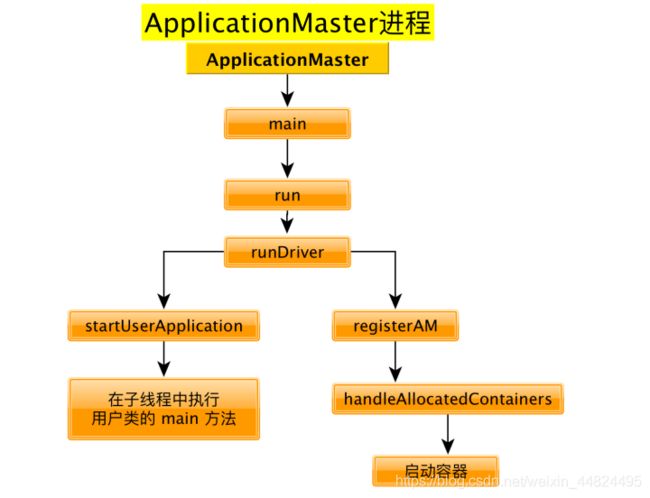
4. org.apache.spark.deploy.yarn.ApplicationMaster 源码分析
ApplicationMaster伴生对象的 main方法
def main(args: Array[String]): Unit = {
SignalUtils.registerLogger(log)
// 构建 ApplicationMasterArguments 对象, 对传来的参数做封装
val amArgs: ApplicationMasterArguments = new ApplicationMasterArguments(args)
SparkHadoopUtil.get.runAsSparkUser { () =>
// 构建 ApplicationMaster 实例 ApplicationMaster 需要与 RM通讯
master = new ApplicationMaster(amArgs, new YarnRMClient)
// 运行 ApplicationMaster 的 run 方法, run 方法结束之后, 结束 ApplicationMaster 进程
System.exit(master.run())
}
}
ApplicationMaster 伴生类的 run方法
final def run(): Int = {
// 关键核心代码
try {
val fs = FileSystem.get(yarnConf)
if (isClusterMode) {
runDriver(securityMgr)
} else {
runExecutorLauncher(securityMgr)
}
} catch {
}
exitCode
}
runDriver 方法
private def runDriver(securityMgr: SecurityManager): Unit = {
addAmIpFilter()
// 开始执行用户类. 启动一个子线程来执行用户类的 main 方法. 返回值就是运行用户类的子线程.
// 线程名就叫 "Driver"
userClassThread = startUserApplication()
val totalWaitTime = sparkConf.get(AM_MAX_WAIT_TIME)
try {
// 注册 ApplicationMaster , 其实就是请求资源
registerAM(sc.getConf, rpcEnv, driverRef, sc.ui.map(_.appUIAddress).getOrElse(""),
securityMgr)
// 线程 join: 把userClassThread线程执行完毕之后再继续执行当前线程.
userClassThread.join()
} catch {
}
}
startUserApplication 方法
private def startUserApplication(): Thread = {
// 得到用户类的 main 方法
val mainMethod = userClassLoader.loadClass(args.userClass)
.getMethod("main", classOf[Array[String]])
// 创建及线程
val userThread = new Thread {
override def run() {
try {
// 调用用户类的主函数
mainMethod.invoke(null, userArgs.toArray)
} catch {
} finally {
}
}
}
userThread.setContextClassLoader(userClassLoader)
userThread.setName("Driver")
userThread.start()
userThread
}
registerAM 方法
private def registerAM(
_sparkConf: SparkConf,
_rpcEnv: RpcEnv,
driverRef: RpcEndpointRef,
uiAddress: String,
securityMgr: SecurityManager) = {
// 向 RM 注册, 得到 YarnAllocator
allocator = client.register(driverUrl,
driverRef,
yarnConf,
_sparkConf,
uiAddress,
historyAddress,
securityMgr,
localResources)
// 请求分配资源
allocator.allocateResources()
}
allocator.allocateResources() 方法
/**
请求资源,如果 Yarn 满足了我们的所有要求,我们就会得到一些容器(数量: maxExecutors)。
通过在这些容器中启动 Executor 来处理 YARN 授予我们的任何容器。
必须同步,因为在此方法中读取的变量会被其他方法更改。
*/
def allocateResources(): Unit = synchronized {
if (allocatedContainers.size > 0) {
handleAllocatedContainers(allocatedContainers.asScala)
}
}
handleAllocatedContainers方法
/**
处理 RM 授权给我们的容器
*/
def handleAllocatedContainers(allocatedContainers: Seq[Container]): Unit = {
val containersToUse = new ArrayBuffer[Container](allocatedContainers.size)
runAllocatedContainers(containersToUse)
}
runAllocatedContainers 方法
/**
* Launches executors in the allocated containers.
在已经分配的容器中启动 Executors
*/
private def runAllocatedContainers(containersToUse: ArrayBuffer[Container]): Unit = {
// 每个容器上启动一个 Executor
for (container <- containersToUse) {
if (numExecutorsRunning < targetNumExecutors) {
if (launchContainers) {
launcherPool.execute(new Runnable {
override def run(): Unit = {
try {
new ExecutorRunnable(
Some(container),
conf,
sparkConf,
driverUrl,
executorId,
executorHostname,
executorMemory,
executorCores,
appAttemptId.getApplicationId.toString,
securityMgr,
localResources
).run() // 启动 executor
updateInternalState()
} catch {
}
}
})
} else {
}
} else {
}
}
}
ExecutorRunnable.run方法
def run(): Unit = {
logDebug("Starting Executor Container")
// 创建 NodeManager 客户端
nmClient = NMClient.createNMClient()
// 初始化 NodeManager 客户端
nmClient.init(conf)
// 启动 NodeManager 客户端
nmClient.start()
// 启动容器
startContainer()
}
ExecutorRunnable.startContainer()
def startContainer(): java.util.Map[String, ByteBuffer] = {
val ctx = Records.newRecord(classOf[ContainerLaunchContext])
.asInstanceOf[ContainerLaunchContext]
// 准备要执行的命令
val commands = prepareCommand()
ctx.setCommands(commands.asJava)
// Send the start request to the ContainerManager
try {
// 启动容器
nmClient.startContainer(container.get, ctx)
} catch {
}
}
ExecutorRunnable.prepareCommand 方法
private def prepareCommand(): List[String] = {
val commands = prefixEnv ++ Seq(
YarnSparkHadoopUtil.expandEnvironment(Environment.JAVA_HOME) + "/bin/java",
"-server") ++
javaOpts ++
// 要执行的类
Seq("org.apache.spark.executor.CoarseGrainedExecutorBackend",
"--driver-url", masterAddress,
"--executor-id", executorId,
"--hostname", hostname,
"--cores", executorCores.toString,
"--app-id", appId) ++
userClassPath ++
Seq(
s"1>${ApplicationConstants.LOG_DIR_EXPANSION_VAR}/stdout",
s"2>${ApplicationConstants.LOG_DIR_EXPANSION_VAR}/stderr")
commands.map(s => if (s == null) "null" else s).toList
}
至此, ApplicationMaster 进程启动完毕 !!
5.org.apache.spark.executor.CoarseGrainedExecutorBackend 源码分析
CoarseGrainedExecutorBackend 伴生对象
main方法
def main(args: Array[String]) {
// 启动 CoarseGrainedExecutorBackend
run(driverUrl, executorId, hostname, cores, appId, workerUrl, userClassPath)
// 运行结束之后退出进程
System.exit(0)
}
run 方法
/**
准备 RpcEnv
*/
private def run(
driverUrl: String,
executorId: String,
hostname: String,
cores: Int,
appId: String,
workerUrl: Option[String],
userClassPath: Seq[URL]) {
SparkHadoopUtil.get.runAsSparkUser { () =>
val env = SparkEnv.createExecutorEnv(
driverConf, executorId, hostname, port, cores, cfg.ioEncryptionKey, isLocal = false)
env.rpcEnv.setupEndpoint("Executor", new CoarseGrainedExecutorBackend(
env.rpcEnv, driverUrl, executorId, hostname, cores, userClassPath, env))
}
}
CoarseGrainedExecutorBackend 伴生类
继承自: ThreadSafeRpcEndpoint 是一个RpcEndpoint
查看生命周期方法
onStart 方法
连接到 Driver, 并向 Driver注册Executor
override def onStart() {
rpcEnv.asyncSetupEndpointRefByURI(driverUrl).flatMap { ref =>
// This is a very fast action so we can use "ThreadUtils.sameThread"
driver = Some(ref)
// 向驱动注册 Executor 关键方法
ref.ask[Boolean](RegisterExecutor(executorId, self, hostname, cores, extractLogUrls))
}(ThreadUtils.sameThread).onComplete {
case Success(msg) =>
case Failure(e) =>
// 注册失败, 退出 executor
exitExecutor(1, s"Cannot register with driver: $driverUrl", e, notifyDriver = false)
}(ThreadUtils.sameThread)
}
Driver端的CoarseGrainedSchedulerBackend.DriverEndPoint 的 receiveAndReply 方法
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
// 接收注册 Executor
case RegisterExecutor(executorId, executorRef, hostname, cores, logUrls) =>
if (executorDataMap.contains(executorId)) { // 已经注册过了
} else {
// 给 Executor 发送注册成功的信息
executorRef.send(RegisteredExecutor)
}
}
Eexcutor端的CoarseGrainedExecutorBackend的receive方法
override def receive: PartialFunction[Any, Unit] = {
// 向 Driver 注册成功
case RegisteredExecutor =>
logInfo("Successfully registered with driver")
try {
// 创建 Executor 对象 注意: Executor 其实是一个对象
executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false)
} catch {
}
}
至此, Executor 创建完毕
6.总结

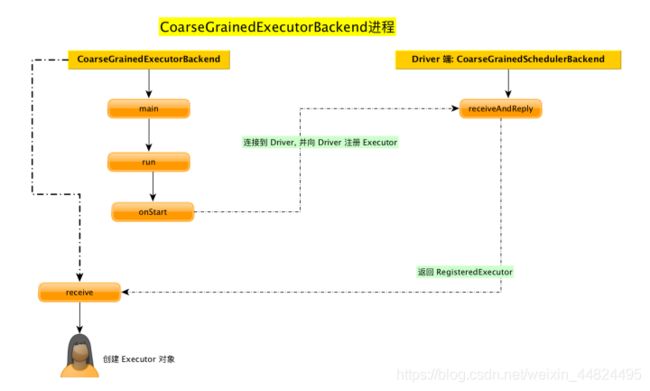
3.1.4 Yarn client 模式运行机制源码分析
执行下面的代码:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100
启动类:
/opt/module/jdk1.8.0_172/bin/java
-cp /opt/module/spark-yarn/conf/:/opt/module/spark-yarn/jars/*:/opt/module/hadoop-2.7.2/etc/hadoop/
-Xmx1g
org.apache.spark.deploy.SparkSubmit
--master yarn
--deploy-mode client
--class org.apache.spark.examples.SparkPi
./examples/jars/spark-examples_2.11-2.1.1.jar 100
依次启动 3 个不同的进程:
SparkSubmit
ExecutorLauncher
CoarseGrainedExecutorBackend
1.client 模式下直接运行用户的主类:
prepareSubmitEnvironment 方法
/*
client 模式下, 直接启动用户的主类
*/
if (deployMode == CLIENT || isYarnCluster) {
// 如果是客户端模式, childMainClass 就是用户的类
// 集群模式下, childMainClass 被重新赋值为 org.apache.spark.deploy.yarn.Client
childMainClass = args.mainClass
}
然后不会创建ApplicationMaster, 而是直接执行用户类的main方法
然后开始实例化 SparkContext
2.实例化SparkContext
val (sched, ts):(SchedulerBackend, TaskScheduler) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
// 启动 YarnScheduler
_taskScheduler.start()
SparkContext.createTaskScheduler 方法
关键代码:
private def createTaskScheduler(
sc: SparkContext,
master: String,
deployMode: String): (SchedulerBackend, TaskScheduler) = {
import SparkMasterRegex._
master match {
case masterUrl =>
// 得到的是 YarnClusterManager
val cm = getClusterManager(masterUrl) match {
case Some(clusterMgr) => clusterMgr
case None => throw new SparkException("Could not parse Master URL: '" + master + "'")
}
try {
// 创建 YarnScheduler
val scheduler: TaskScheduler = cm.createTaskScheduler(sc, masterUrl)
// 创建 YarnClientSchedulerBackend
val backend: SchedulerBackend = cm.createSchedulerBackend(sc, masterUrl, scheduler)
cm.initialize(scheduler, backend)
(backend, scheduler)
} catch {
}
}
}
YarnClusterManager 类
private[spark] class YarnClusterManager extends ExternalClusterManager {
override def canCreate(masterURL: String): Boolean = {
masterURL == "yarn"
}
override def createTaskScheduler(sc: SparkContext, masterURL: String): TaskScheduler = {
sc.deployMode match {
case "cluster" => new YarnClusterScheduler(sc)
case "client" => new YarnScheduler(sc)
case _ => throw new SparkException(s"Unknown deploy mode '${sc.deployMode}' for Yarn")
}
}
override def createSchedulerBackend(sc: SparkContext,
masterURL: String,
scheduler: TaskScheduler): SchedulerBackend = {
sc.deployMode match {
case "cluster" =>
new YarnClusterSchedulerBackend(scheduler.asInstanceOf[TaskSchedulerImpl], sc)
case "client" =>
new YarnClientSchedulerBackend(scheduler.asInstanceOf[TaskSchedulerImpl], sc)
case _ =>
throw new SparkException(s"Unknown deploy mode '${sc.deployMode}' for Yarn")
}
}
override def initialize(scheduler: TaskScheduler, backend: SchedulerBackend): Unit = {
scheduler.asInstanceOf[TaskSchedulerImpl].initialize(backend)
}
}
_taskScheduler.start()
YarnClientSchedulerBackend 的 start 方法
/**
* Create a Yarn client to submit an application to the ResourceManager.
* This waits until the application is running.
*
* 创建客户端, 提交应用给 ResourceManager
* 会一直等到应用开始执行
*/
override def start() {
val driverHost = conf.get("spark.driver.host")
val driverPort = conf.get("spark.driver.port")
val argsArrayBuf = new ArrayBuffer[String]()
argsArrayBuf += ("--arg", hostport)
val args = new ClientArguments(argsArrayBuf.toArray)
client = new Client(args, conf)
// 使用 Client 提交应用
bindToYarn(client.submitApplication(), None)
waitForApplication()
}
3.org.apache.spark.deploy.yarn.Client 源码再分析
submitApplication 方法
yarnClient.submitApplication(appContext)
ExecutorLauncher 类
yarnClient 提交应用的时候, 把要执行的主类(ExecutorLauncher)封装到配置中. 所以不是启动ApplicationMaster, 而是启动ExecutorLauncher
// createContainerLaunchContext()
val amClass =
if (isClusterMode) {
Utils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName
} else {
Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName
}
/**
* This object does not provide any special functionality. It exists so that it's easy to tell
* apart the client-mode AM from the cluster-mode AM when using tools such as ps or jps.
*
* 这个对象不提供任何特定的功能.
*
* 它的存在使得在使用诸如ps或jps之类的工具时,很容易区分客户机模式AM和集群模式AM。
*
*/
object ExecutorLauncher {
def main(args: Array[String]): Unit = {
ApplicationMaster.main(args)
}
}
4.ApplicationMaster 源码再分析
run 方法
final def run(): Int = {
try {
if (isClusterMode) {
runDriver(securityMgr)
} else {
// 非集群模式, 直接执行 ExecutorLauncher, 而不在需要运行 Driver
runExecutorLauncher(securityMgr)
}
} catch {
}
exitCode
}
runExecutorLauncher
private def runExecutorLauncher(securityMgr: SecurityManager): Unit = {
val driverRef = waitForSparkDriver()
addAmIpFilter()
registerAM(sparkConf, rpcEnv, driverRef, sparkConf.get("spark.driver.appUIAddress", ""),
securityMgr)
// In client mode the actor will stop the reporter thread.
reporterThread.join()
}
在以后的执行流程就和yarn-cluster模式一样了
5.总结
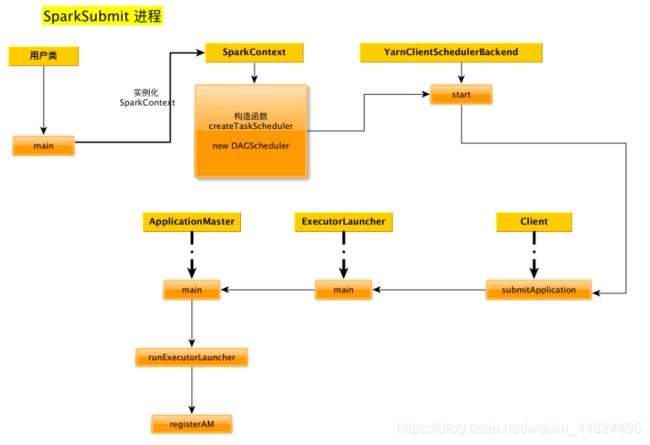
3.1.5 Yarn cluster 和 client的总结
- 提交的时候,会启动3种进程:ApplicationMster名字有区别
- driver的位置不同:
cluster模式:(1)AM是在某个NM上 (2)driver是AM进程的一个子线程
client模式: driver运行在Submit进程的主线程中
3.2 Standalone 模式运行机制
Standalone 集群有 2 个重要组成部分,分别是:
- Master(RM):是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责;
- Worker(NM):是一个进程,一个 Worker 运行在集群中的一台服务器上,主要负责两个职责,
- 一个是用自己的内存存储 RDD 的某个或某些 partition
- 另一个是启动其他进程和线程(Executor),对 RDD 上的 partition 进行并行的处理和计算。
根据 driver的位置不同, 也分 2 种:
3.2.1 Standalone Cluster 模式
 在Standalone Cluster模式下,任务提交后,Master会找到一个 Worker 启动Driver。
在Standalone Cluster模式下,任务提交后,Master会找到一个 Worker 启动Driver。
Driver启动后向Master注册应用程序,Master根据 submit 脚本的资源需求找到内部资源至少可以启动一个Executor 的所有Worker,然后在这些 Worker之间分配Executor,Worker上的Executor启动后会向Driver反向注册,所有的 Executor 注册完成后,Driver 开始执行main函数,之后执行到Action算子时,开始划分 tage,每个 Stage 生成对应的taskSet,之后将 Task 分发到各个 Executor 上执行。
3.2.2 Standalone Client 模式
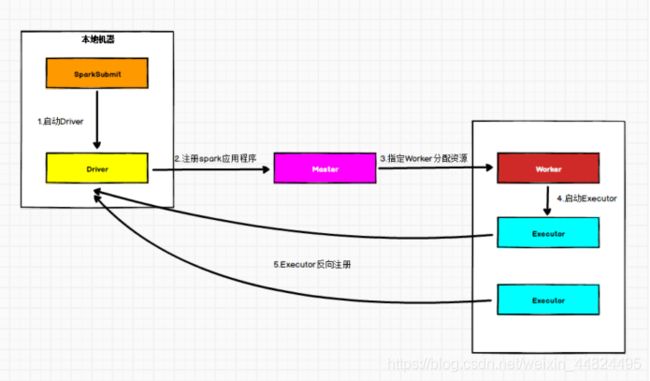
在 Standalone Client 模式下,Driver 在任务提交的本地机器上运行。
Driver启动后向 Master 注册应用程序,Master 根据 submit 脚本的资源需求找到内部资源至少可以启动一个Executor 的所有 Worker,然后在这些 Worker 之间分配 Executor,Worker 上的 Executor 启动后会向Driver反向注册,所有的Executor注册完成后,Driver 开始执行main函数,之后执行到Action算子时,开始划分Stage,每个Stage生成对应的TaskSet,之后将Task分发到各个Executor上执行。
4.Spark 任务调度机制
在生产环境下,Spark 集群的部署方式一般为 YARN-Cluster 模式,
在上一章介绍了 Spark YARN-Cluster 模式下的任务提交流程,但是并没有具体说明 Driver 的工作流程, Driver 线程主要是初始化 SparkContext对象,准备运行所需的上下文,然后一方面保持与ApplicationMaster的RPC连接,通过ApplicationMaster申请资源,另一方面根据用户业务逻辑开始调度任务,将任务下发到已有的空闲Executor上。
当ResourceManager向ApplicationMaster返回Container资源时,ApplicationMaster就尝试在对应的Container上启动Executor进程,Executor进程起来后,会向Driver反向注册,注册成功后保持与Driver的心跳,同时等待Driver分发任务,当分发的任务执行完毕后,将任务状态上报给Driver。
4.1 Spark 任务调度概述
当 Driver 起来后,Driver 则会根据用户程序逻辑(.map.reduce等)准备任务,并根据Executor资源情况逐步分发任务。
在详细阐述任务调度前,首先说明下 Spark 里的几个概念。一个 Spark 应用程序包括Job、Stage以及Task三个概念:
- Job 是以 Action 算子为界,遇到一个Action算子则触发一个Job;
- Stage 是 Job 的子集,以 RDD 宽依赖(即 Shuffle )为界,遇到 Shuffle 做一次划分;
- Task 是 Stage 的子集,以并行度(分区数)来衡量,这个 Stage 分区数是多少,则这个Stage 就有多少个 Task。
Spark 的任务调度总体来说分两路进行:
一路是 Stage 级的调度
一路是 Task 级的调度
总体调度流程如下图所示:
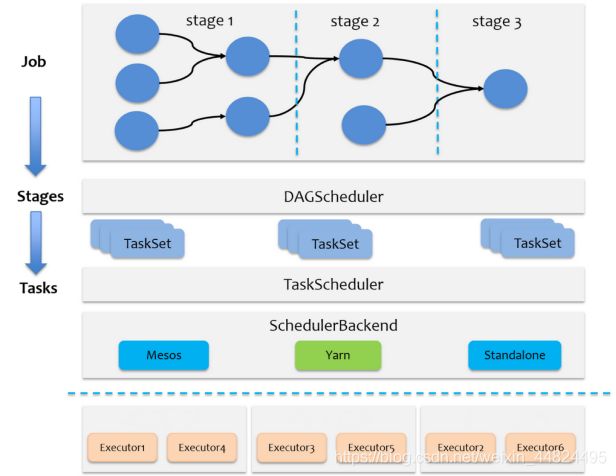
Spark RDD 通过其 Transactions 操作,形成了RDD血缘关系图,即DAG,最后通过Action的调用,触发Job并调度执行。
DAGScheduler负责Stage级的调度,主要是将job切分成若干Stages,并将每个Stage打包成TaskSet交给TaskScheduler调度。
TaskScheduler负责Task级的调度,将DAGScheduler传过来的TaskSet按照指定的调度策略分发到Executor上执行,调度过程中SchedulerBackend负责提供可用资源,其中SchedulerBackend有多种实现,分别对接不同的资源管理系统。

Driver初始化SparkContext过程中,会分别初始化DAGScheduler、TaskScheduler、SchedulerBackend以及HeartbeatReceiver,并启动 SchedulerBackend以及HeartbeatReceiver。
SchedulerBackend通过ApplicationMaster申请资源,并不断从TaskScheduler中拿到合适的Task分发到Executor执行。
HeartbeatReceiver负责接收Executor的心跳信息,监控Executor的存活状况,并通知到TaskScheduler。
4.2 Spark Stage 级别调度
Spark的任务调度是从DAG切割开始,主要是由DAGScheduler来完成。当遇到一个Action操作后就会触发一个Job的计算,并交给DAGScheduler来提交,下图是涉及到Job提交的相关方法调用流程图。
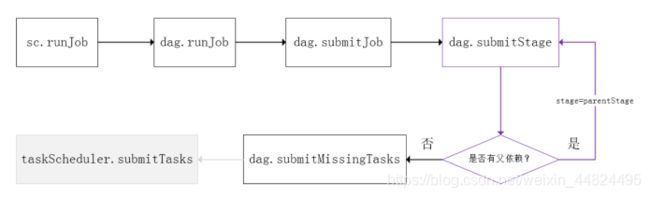
- Job 由最终的RDD和Action方法封装而成;
- SparkContext将Job交给DAGScheduler提交,它会根据RDD的血缘关系构成的DAG进行切分,将一个Job划分为若干Stages,具体划分策略是,由最终的RDD不断通过依赖回溯判断父依赖是否是宽依赖,即以Shuffle为界,划分Stage,窄依赖的RDD之间被划分到同一个Stage中,可以进行pipeline式的计算。
- 划分的Stages分两类,一类叫做ResultStage,为DAG最下游的Stage,由Action方法决定,另一类叫做ShuffleMapStage,为下游Stage准备数据
下面看一个简单的例子WordCount。

说明:
- Job由saveAsTextFile触发,该Job由RDD-3和saveAsTextFile方法组成,根据RDD之间的依赖关系从RDD-3开始回溯搜索,直到没有依赖的RDD-0,
- 在回溯搜索过程中,RDD-3依赖RDD-2,并且是宽依赖,所以在RDD-2和RDD-3之间划分Stage,RDD-3被划到最后一个Stage,即ResultStage中
- RDD-2依赖RDD-1,RDD-1依赖RDD-0,这些依赖都是窄依赖,所以将RDD-0、RDD-1和RDD-2划分到同一个Stage,即ShuffleMapStage中,实际执行的时候,数据记录会一气呵成地执行RDD-0到RDD-2的转化。
- 不难看出,其本质上是一个深度优先搜索算法。
一个Stage是否被提交,需要判断它的父Stage是否执行,只有在父Stage执行完毕才能提交当前Stage
如果一个Stage没有父Stage,那么从该Stage开始提交。
Stage提交时会将Task信息(分区信息以及方法等)序列化并被打包成TaskSet交给TaskScheduler,一个Partition对应一个Task,另一方面TaskScheduler会监控Stage的运行状态,只有Executor丢失或者Task由于Fetch失败才需要重新提交失败的Stage以调度运行失败的任务,其他类型的Task失败会在TaskScheduler的调度过程中重试。
相对来说DAGScheduler做的事情较为简单,仅仅是在Stage层面上划分DAG,提交Stage并监控相关状态信息。
TaskScheduler则相对较为复杂,下面详细阐述其细节。
4.3 Spark Task 级别调度
Spark Task 的调度是由TaskScheduler来完成,由前文可知,DAGScheduler将Stage打包到TaskSet交给TaskScheduler,TaskScheduler会将TaskSet封装为TaskSetManager加入到调度队列中,
TaskSetManager结构如下图所示。
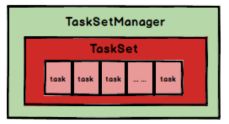
TaskSetManager负责监控管理同一个Stage中的Tasks,TaskScheduler就是以TaskSetManager为单元来调度任务。
前面也提到,TaskScheduler初始化后会启动SchedulerBackend,它负责跟外界打交道,接收Executor的注册信息,并维护Executor的状态,所以说SchedulerBackend是管“粮食”的,同时它在启动后会定期地去“询问”TaskScheduler有没有任务要运行,也就是说,它会定期地“问”TaskScheduler“我有这么余量,你要不要啊”,TaskScheduler在SchedulerBackend“问”它的时候,会从调度队列中按照指定的调度策略选择TaskSetManager去调度运行,大致方法调用流程如下图所示:
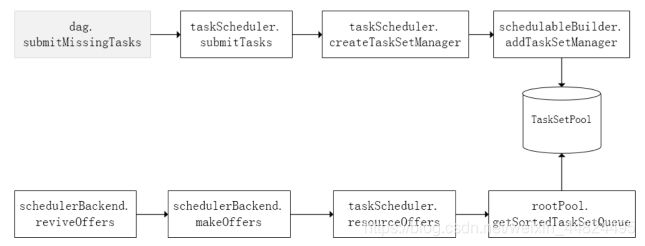
将TaskSetManager加入rootPool调度池中之后,调用SchedulerBackend的riviveOffers方法给driverEndpoint发送ReviveOffer消息;driverEndpoint收到ReviveOffer消息后调用makeOffers方法,过滤出活跃状态的Executor(这些Executor都是任务启动时反向注册到Driver的Executor),然后将Executor封装成WorkerOffer对象;准备好计算资源(WorkerOffer)后,taskScheduler基于这些资源调用resourceOffer在Executor上分配task。
4.3.1 调度策略
TaskScheduler支持两种调度策略,一种是FIFO,也是默认的调度策略,另一种是FAIR。
在TaskScheduler初始化过程中会实例化rootPool,表示树的根节点,是Pool类型。
- FIFO调度策略
如果是采用FIFO调度策略,则直接简单地将TaskSetManager按照先来先到的方式入队,出队时直接拿出最先进队的TaskSetManager,其树结构如下图所示,TaskSetManager保存在一个FIFO队列中。

- FAIR调度策略(0.8 开始支持)
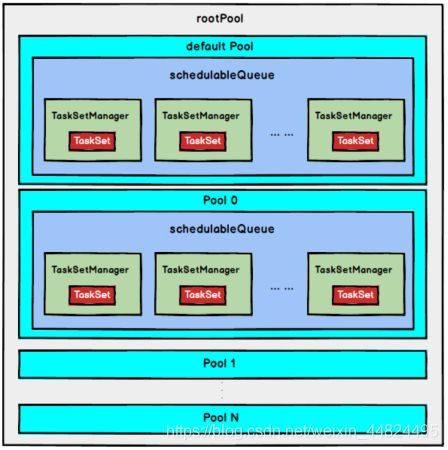
FAIR模式中有一个rootPool和多个子Pool,各个子Pool中存储着所有待分配的TaskSetMagager。
在FAIR模式中,需要先对子Pool进行排序,再对子Pool里面的TaskSetMagager进行排序,因为Pool和TaskSetMagager都继承了Schedulable特质,因此使用相同的排序算法。
排序过程的比较是基于Fair-share来比较的,每个要排序的对象包含三个属性: runningTasks值(正在运行的Task数)、minShare值、weight值,比较时会综合考量runningTasks值,minShare值以及weight值。
注意,minShare、weight的值均在公平调度配置文件fairscheduler.xml中被指定,调度池在构建阶段会读取此文件的相关配置。 - 如果 A 对象的runningTasks大于它的minShare,B 对象的runningTasks小于它的minShare,那么B排在A前面;(runningTasks 比 minShare 小的先执行)
- 如果A、B对象的 runningTasks 都小于它们的 minShare,那么就比较 runningTasks 与 math.max(minShare1, 1.0) 的比值(minShare使用率),谁小谁排前面;(minShare使用率低的先执行)
- 如果A、B对象的runningTasks都大于它们的minShare,那么就比较runningTasks与weight的比值(权重使用率),谁小谁排前面。(权重使用率低的先执行)
- 如果上述比较均相等,则比较名字。
整体上来说就是通过minShare和weight这两个参数控制比较过程,可以做到让minShare使用率和权重使用率少(实际运行task比例较少)的先运行。
FAIR模式排序完成后,所有的TaskSetManager被放入一个ArrayBuffer里,之后依次被取出并发送给Executor执行。
从调度队列中拿到TaskSetManager后,由于TaskSetManager封装了一个Stage的所有Task,并负责管理调度这些Task,那么接下来的工作就是TaskSetManager按照一定的规则一个个取出Task给TaskScheduler,TaskScheduler再交给SchedulerBackend去发到Executor上执行。
如何启用公平调度器:
val conf = new SparkConf().setMaster(...).setAppName(...)
conf.set("spark.scheduler.mode", "FAIR")
val sc = new SparkContext(conf)
4.3.2 本地化调度
DAGScheduler切割Job,划分Stage, 通过调用submitStage来提交一个Stage对应的tasks,submitStage会调用submitMissingTasks,submitMissingTasks 确定每个需要计算的 task 的preferredLocations,通过调用getPreferrdeLocations()得到partition的优先位置,由于一个partition对应一个Task,此partition的优先位置就是task的优先位置,
对于要提交到TaskScheduler的TaskSet中的每一个Task,该ask优先位置与其对应的partition对应的优先位置一致。
从调度队列中拿到TaskSetManager后,那么接下来的工作就是TaskSetManager按照一定的规则一个个取出task给TaskScheduler,TaskScheduler再交给SchedulerBackend去发到Executor上执行。前面也提到,TaskSetManager封装了一个Stage的所有Task,并负责管理调度这些Task。 根据每个Task的优先位置,确定Task的Locality级别,Locality一共有五种,优先级由高到低顺序:
| 名称 | 解析 |
|---|---|
| PROCESS_LOCAL | 进程本地化,task和数据在同一个Executor中,性能最好。 |
| NODE_LOCAL | 节点本地化,task和数据在同一个节点中,但是task和数据不在同一个Executor中,数据需要在进程间进行传输。 |
| RACK_LOCAL | 机架本地化,task和数据在同一个机架的两个节点上,数据需要通过网络在节点之间进行传输。 |
| NO_PREF | 对于task来说,从哪里获取都一样,没有好坏之分。 |
| ANY | task和数据可以在集群的任何地方,而且不在一个机架中,性能最差。 |
在调度执行时,Spark 调度总是会尽量让每个task以最高的本地性级别来启动,当一个task以本地性级别启动,但是该本地性级别对应的所有节点都没有空闲资源而启动失败,此时并不会马上降低本地性级别启动而是在某个时间长度内再次以本地性级别来启动该task,若超过限时时间则降级启动,去尝试下一个本地性级别,依次类推。
可以通过调大每个类别的最大容忍延迟时间,在等待阶段对应的Executor可能就会有相应的资源去执行此task,这就在在一定程度上提升了运行性能。
4.3.3 失败重试和黑名单
除了选择合适的Task调度运行外,还需要监控Task的执行状态,前面也提到,与外部打交道的是SchedulerBackend,Task被提交到Executor启动执行后,Executor会将执行状态上报给SchedulerBackend,SchedulerBackend则告诉TaskScheduler,TaskScheduler找到该Task对应的TaskSetManager,并通知到该TaskSetManager,这样TaskSetManager就知道Task的失败与成功状态,对于失败的Task,会记录它失败的次数,如果失败次数还没有超过最大重试次数,那么就把它放回待调度的Task池子中,否则整个Application失败。
在记录Task失败次数过程中,会记录它上一次失败所在的Executor Id和Host,这样下次再调度这个Task时,会使用黑名单机制,避免它被调度到上一次失败的节点上,起到一定的容错作用。黑名单记录Task上一次失败所在的Executor Id和Host,以及其对应的“拉黑”时间,
“拉黑”时间是指这段时间内不要再往这个节点上调度这个Task了。
4.4 Stage 级别任务调度源码分析
1.SparkContext初始化
任务调度的时候, 需要用到 3 个非常重要的组件, 都是在 SparkContext 初始化的时候创建并启动:
这三个组件分别是:
SchedulerBackend ,TaskScheduler , DAGScheduler
// 用来与其他组件通讯用
private var _schedulerBackend: SchedulerBackend = _
// DAG 调度器, 是调度系统的中的中的重要组件之一, 负责创建 Job, 将 DAG 中的 RDD 划分到不同的 Stage, 提交 Stage 等.
// SparkUI 中有关 Job 和 Stage 的监控数据都来自 DAGScheduler
@volatile private var _dagScheduler: DAGScheduler = _
// TaskScheduler 按照调度算法对集群管理器已经分配给应用程序的资源进行二次调度后分配给任务
// TaskScheduler 调度的 Task 是由DAGScheduler 创建的, 所以 DAGScheduler 是 TaskScheduler的前置调度器
private var _taskScheduler: TaskScheduler = _
// 创建 SchedulerBackend 和 TaskScheduler
val (sched, ts):(SchedulerBackend, TaskScheduler) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
// 创建 DAGScheduler
_dagScheduler = new DAGScheduler(this)
// 启动 TaskScheduler, 内部会也会启动 SchedulerBackend
_taskScheduler.start()
我们从一个 action 开始. 例如: collect
2.RDD 类源码分析
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}
sc.runJob 方法
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
// 作业的切分
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
}
3.DAGScheduler类源码分析
dagScheduler.runJob 方法
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
// 提交任务 返回值 JobWaiter 用来确定 Job 的成功与失败
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
}
dagScheduler.submitJob 方法
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// 创建 JobWaiter 对象
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
// 向内部事件循环器发送消息 JobSubmitted
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}
DAGSchedulerEventProcessLoop 类
DAGSchedulerEventProcessLoop 是 DAGSheduler内部的事件循环处理器, 用于处理DAGSchedulerEvent类型的事件.
前面发送的是JobSubmitted类型的事件
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
// 处理提交的 Job
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
}
DAGScheduler.handleJobSubmitted
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
// Stage 的划分是从后向前推断的, 所以先创建最后的阶段
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
}
submitStage(finalStage)
}
DAGScheduler.createResultStage() 方法
private def createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
// 1. 获取所有父 Stage 的列表
val parents: List[Stage] = getOrCreateParentStages(rdd, jobId)
// 2. 给 resultStage 生成一个 id
val id = nextStageId.getAndIncrement()
// 3. 创建 ResultStage
val stage: ResultStage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
// 4. stageId 和 ResultStage 做映射
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
DAGScheduler.getOrCreateParentStages() 方法
private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
// 获取所有的 Shuffle 依赖(宽依赖)
getShuffleDependencies(rdd).map { shuffleDep =>
// 对每个 shuffle 依赖, 获取或者创建新的 Stage: ShuffleMapStage
getOrCreateShuffleMapStage(shuffleDep, firstJobId)
}.toList
}
说明:
•一共有两种Stage: ResultStage和ShuffleMapStage
DAGScheduler.getShuffleDependencies
// 得到所有宽依赖
private[scheduler] def getShuffleDependencies(
rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = {
val parents = new HashSet[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new Stack[RDD[_]]
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop()
if (!visited(toVisit)) {
visited += toVisit
toVisit.dependencies.foreach {
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep
case dependency =>
waitingForVisit.push(dependency.rdd)
}
}
}
parents
}
DAGScheduler.submitStage(finalStage) 方法
提交 finalStage
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 获取所有的父 Stage
val missing = getMissingParentStages(stage).sortBy(_.id)
// 如果为空, 则提交这个 Stage
if (missing.isEmpty) {
submitMissingTasks(stage, jobId.get)
} else { // 如果还有父 Stage , 则递归调用
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
}
}
说明:
•从前面的分析可以看到, 阶段划分是从后向前
•最前面的 Stage 先提交
DAGScheduler.submitMissingTasks 方法
private def submitMissingTasks(stage: Stage, jobId: Int) {
// 任务划分. 每个分区创建一个 Task
val tasks: Seq[Task[_]] = try {
stage match {
case stage: ShuffleMapStage =>
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = stage.rdd.partitions(id)
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, stage.latestInfo.taskMetrics, properties, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId)
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, properties, stage.latestInfo.taskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId)
}
}
} catch {
}
// 提交任务
if (tasks.size > 0) {
// 使用 taskScheduler 提交任务
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
} else {
}
}
4.TaskScheduler类源码分析
TaskScheduler是一个Trait, 我们分析它的实现类: TaskSchedulerImpl
override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
this.synchronized {
// 创建 TaskManger 对象. 用来追踪每个任务
val manager: TaskSetManager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
// manage 和 TaskSet 交给合适的任务调度器来调度
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
}
// 跟 ExecutorBackend 通讯
backend.reviveOffers()
}
CoarseGrainedSchedulerBackend.reviveOffers
override def reviveOffers() {
// DriverEndpoint 给自己发信息: ReviveOffers
driverEndpoint.send(ReviveOffers)
}
DriverEndpoint.receive 方法
private def makeOffers() {
// 过滤出 Active 的Executor
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
// 封装资源
val workOffers = activeExecutors.map { case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toIndexedSeq
// 启动任务
launchTasks(scheduler.resourceOffers(workOffers))
}
DriverEndpoint.launchTasks
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
// 序列化任务
val serializedTask = ser.serialize(task)
if (serializedTask.limit >= maxRpcMessageSize) {
}
else {
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
// 发送任务到 Executor. CoarseGrainedExecutorBackend 会收到消息
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}
5.CoarseGrainedExecutorBackend 源码分析
override def receive: PartialFunction[Any, Unit] = {
//
case LaunchTask(data) =>
if (executor == null) {
exitExecutor(1, "Received LaunchTask command but executor was null")
} else {
// 把要执行的任务反序列化
val taskDesc = ser.deserialize[TaskDescription](data.value)
// 启动任务开始执行
executor.launchTask(this, taskId = taskDesc.taskId, attemptNumber = taskDesc.attemptNumber,
taskDesc.name, taskDesc.serializedTask)
}
}
至此, stage 级别的任务调度完成
4.5 Task 级别任务调度源码分析
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
根据前面的分析介绍, DAGSheduler将Task 提交给TaskScheduler时, 需要将多个 Task打包为TaskSet.
TaskSet是整个调度池中对Task进行调度管理的基本单位, 由调度池中的TaskManager来管理.
taskScheduler.submitTasks 方法
// 把 TaskSet 交给任务调度池来调度
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
schedulableBuilder的类型是:SchedulableBuilder, 它是一个Trait, 有两个已知的实现子类: FIFOSchedulableBuilder 和 FairSchedulableBuilder
1.SchedulableBuilder(调度池构建器)
- FIFOSchedulableBuilder
FIFOSchedulableBuilder.addTaskSetManager
override def addTaskSetManager(manager: Schedulable, properties: Properties) {
// 对 FIFO 调度, 则直接交给根调度器来调度
// 因为 FIFO 调度只有一个根调度度池
rootPool.addSchedulable(manager)
}
说明:
•rootPool是根调度池, 它的类型是Pool, 表示Poll或TaskSet的可调度实体.
•FIFO 调度是默认调度算法
•spark.scheduler.mode类设置调度算法:FIFO,FAIR
•根调度池是在初始化TaskSchedulerImpl的时候创建的.
•FIFOSchedulableBuilder 不需要再构建新的子调度池, 只需要有 rootPoll就可以了
override def buildPools() {
// nothing
}
- FairSchedulableBuilder
不仅仅需要根调度池, 还需要创建更多的调度池
FairSchedulableBuilder.buildPools 方法内会创建更多的子调度池.
2.SchedulingAlgorithm(调度算法)
/**
* An interface for sort algorithm
* 用于排序算法的接口
* FIFO: FIFO algorithm between TaskSetManagers
* FIFO: TaskSetManager 之间的排序
*
* FS: FS algorithm between Pools, and FIFO or FS within Pools
* FS: 池之间排序
*/
private[spark] trait SchedulingAlgorithm {
def comparator(s1: Schedulable, s2: Schedulable): Boolean
}
- FIFOSchedulingAlgorithm
private[spark] class FIFOSchedulingAlgorithm extends SchedulingAlgorithm {
// 是不是先调度 s1
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val priority1 = s1.priority
val priority2 = s2.priority
var res = math.signum(priority1 - priority2)
if (res == 0) {
val stageId1 = s1.stageId
val stageId2 = s2.stageId
res = math.signum(stageId1 - stageId2)
}
res < 0 // 值小的先调度
}
}
- FairSchedulingAlgorithm
private[spark] class FairSchedulingAlgorithm extends SchedulingAlgorithm {
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val minShare1 = s1.minShare
val minShare2 = s2.minShare
val runningTasks1 = s1.runningTasks
val runningTasks2 = s2.runningTasks
val s1Needy = runningTasks1 < minShare1
val s2Needy = runningTasks2 < minShare2
val minShareRatio1 = runningTasks1.toDouble / math.max(minShare1, 1.0)
val minShareRatio2 = runningTasks2.toDouble / math.max(minShare2, 1.0)
val taskToWeightRatio1 = runningTasks1.toDouble / s1.weight.toDouble
val taskToWeightRatio2 = runningTasks2.toDouble / s2.weight.toDouble
var compare = 0
if (s1Needy && !s2Needy) { // 谁的 runningTasks1 < minShare1 谁先被调度
return true
} else if (!s1Needy && s2Needy) {
return false
} else if (s1Needy && s2Needy) { // 如果都 runningTasks < minShare
// 则比较 runningTasks / math.max(minShare1, 1.0) 的比值 小的优先级高
compare = minShareRatio1.compareTo(minShareRatio2)
} else {
// 如果都runningTasks > minShare, 则比较 runningTasks / weight 的比值
// 小的优先级高
compare = taskToWeightRatio1.compareTo(taskToWeightRatio2)
}
if (compare < 0) {
true
} else if (compare > 0) {
false
} else {
// 如果前面都一样, 则比较 TaskSetManager 或 Pool 的名字
s1.name < s2.name
}
}
}
5. Spark Shuffle 解析
在所有的 MapReduce 框架中, Shuffle 是连接 map 任务和 reduce 任务的桥梁. map 任务的中间输出要作为 reduce 任务的输入, 就必须经过 Shuffle, 所以 Shuffle 的性能的优劣直接决定了整个计算引擎的性能和吞吐量.
相比于 Hadoop 的 MapReduce, 我们将看到 Spark 提供了多种结算结果处理的方式及对 Shuffle 过程进行的多种优化.
Shuffle 是所有 MapReduce 计算框架必须面临的执行阶段, Shuffle 用于打通 map 任务的输出与reduce 任务的输入.
map 任务的中间输出结果按照指定的分区策略(例如, 按照 key 的哈希值)分配给处理某一个分区的 reduce 任务.
通用的 MapReduce 框架:
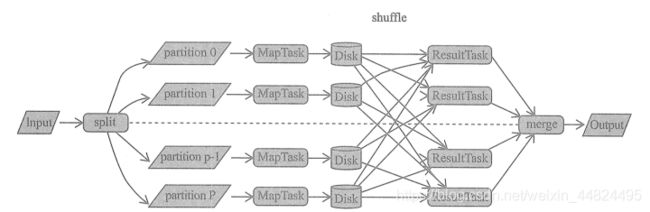
5.1 Shuffle 的核心要点

在划分 Stage 时,最后一个 Stage 称为finalStage(变量名),它本质上是一个ResultStage类型的对象,前面的所有 Stage 被称为 ShuffleMapStage。
ShuffleMapStage 的结束伴随着 shuffle 文件的写磁盘。
ResultStage 基本上对应代码中的 action 算子,即将一个函数应用在 RDD的各个partition的数据集上,意味着一个job的运行结束。
5.1.1 Shuffle 流程源码分析
我们从CoarseGrainedExecutorBackend开始分析
启动任务
override def receive: PartialFunction[Any, Unit] = {
case LaunchTask(data) =>
if (executor == null) {
} else {
val taskDesc = ser.deserialize[TaskDescription](data.value)
// 启动任务
executor.launchTask(this, taskId = taskDesc.taskId, attemptNumber = taskDesc.attemptNumber,
taskDesc.name, taskDesc.serializedTask)
}
}
Executor.launchTask 方法
def launchTask(
context: ExecutorBackend,
taskId: Long,
attemptNumber: Int,
taskName: String,
serializedTask: ByteBuffer): Unit = {
// Runnable 接口的对象.
val tr = new TaskRunner(context, taskId = taskId, attemptNumber = attemptNumber, taskName,
serializedTask)
runningTasks.put(taskId, tr)
// 在线程池中执行 task
threadPool.execute(tr)
}
tr.run方法
override def run(): Unit = {
// 更新 task 的状态
execBackend.statusUpdate(taskId, TaskState.RUNNING, EMPTY_BYTE_BUFFER)
try {
// 把任务相关的数据反序列化出来
val (taskFiles, taskJars, taskProps, taskBytes) =
Task.deserializeWithDependencies(serializedTask)
val value = try {
// 开始运行 Task
val res = task.run(
taskAttemptId = taskId,
attemptNumber = attemptNumber,
metricsSystem = env.metricsSystem)
res
} finally {
}
} catch {
} finally {
}
}
Task.run 方法
final def run(
taskAttemptId: Long,
attemptNumber: Int,
metricsSystem: MetricsSystem): T = {
context = new TaskContextImpl(
stageId,
partitionId,
taskAttemptId,
attemptNumber,
taskMemoryManager,
localProperties,
metricsSystem,
metrics)
try {
// 运行任务
runTask(context)
} catch {
} finally {
}
}
Task.runTask 方法
Task.runTask是一个抽象方法.
Task 有两个实现类, 分别执行不同阶段的Task
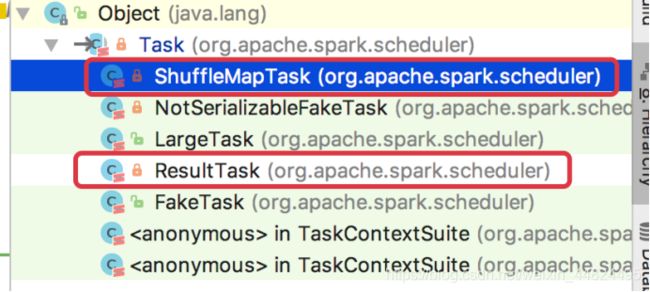
1.ShuffleMapTask源码分析
ShuffleMapTask.runTask 方法
override def runTask(context: TaskContext): MapStatus = {
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
// 获取 ShuffleWriter
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
// 写出 RDD 中的数据. rdd.iterator 是读(计算)数据的操作.
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
} catch {
}
}
具体如何把数据写入到磁盘, 是由ShuffleWriter.write方法来完成.
ShuffleWriter是一个抽象类, 有 3 个实现:
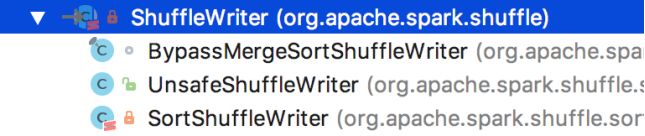
根据在manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)中的dep.shuffleHandle由manager来决定选使用哪种ShuffleWriter.
2.ShuffleManager
ShuffleManage 是一个Trait, 从2.0.0开始就只有一个实现类了: SortShuffleManager
registerShuffle 方法: 匹配出来使用哪种ShuffleHandle
override def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle = {
if (SortShuffleWriter.shouldBypassMergeSort(SparkEnv.get.conf, dependency)) {
new BypassMergeSortShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else if (SortShuffleManager.canUseSerializedShuffle(dependency)) {
new SerializedShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else {
new BaseShuffleHandle(shuffleId, numMaps, dependency)
}
}
getWriter 方法
/** Get a writer for a given partition. Called on executors by map tasks. */
override def getWriter[K, V](
handle: ShuffleHandle,
mapId: Int,
context: TaskContext): ShuffleWriter[K, V] = {
// 根据不同的 Handle, 创建不同的 ShuffleWriter
handle match {
case unsafeShuffleHandle: SerializedShuffleHandle[K@unchecked, V@unchecked] =>
new UnsafeShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
context.taskMemoryManager(),
unsafeShuffleHandle,
mapId,
context,
env.conf)
case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K@unchecked, V@unchecked] =>
new BypassMergeSortShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
bypassMergeSortHandle,
mapId,
context,
env.conf)
case other: BaseShuffleHandle[K@unchecked, V@unchecked, _] =>
new SortShuffleWriter(shuffleBlockResolver, other, mapId, context)
}
}
5.2 HashShuffle 解析
Spark-1.6 之前默认的shuffle方式是hash. 在 spark-1.6版本之后使用Sort-Base Shuffle,因为HashShuffle存在的不足所以就替换了HashShuffle. Spark2.0之后, 从源码中完全移除了HashShuffle.
本节 HashShuffle做个了解
5.2.1 未优化的HashShuffle
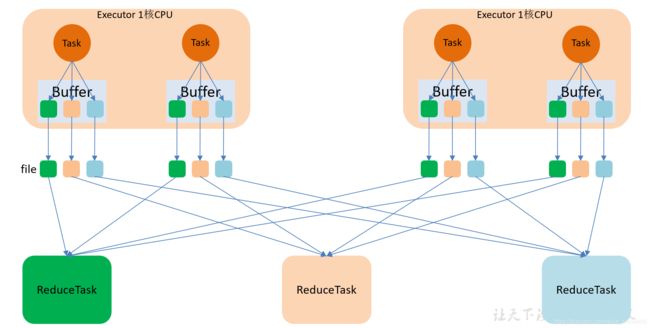
为了方便分析假设前提:每个 Executor 只有 1 个CPU core,也就是说,无论这个 Executor 上分配多少个 task 线程,同一时间都只能执行一个 task 线程。
如下图中有 3个 Reducer,从 Task 开始那边各自把自己进行 Hash 计算(分区器:hash/numreduce取模),分类出3个不同的类别,每个 Task 都分成3种类别的数据,想把不同的数据汇聚然后计算出最终的结果,所以Reducer 会在每个 Task 中把属于自己类别的数据收集过来,汇聚成一个同类别的大集合,每1个 Task 输出3份本地文件,这里有4个 Mapper Tasks,所以总共输出了4个 Tasks x 3个分类文件 = 12个本地小文件。
缺点:
- map 任务的中间结果首先存入内存(缓存), 然后才写入磁盘. 这对于内存的开销很大, 当一个节点上 map 任务的输出结果集很大时, 很容易导致内存紧张, 发生 OOM
- 生成很多的小文件. 假设有 M 个 MapTask, 有 N 个 ReduceTask, 则会创建 M * n 个小文件, 磁盘 I/O 将成为性能瓶颈.
5.2.2 优化的HashShuffle
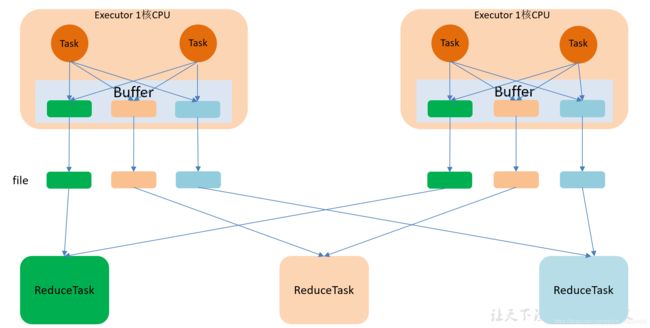
优化的 HashShuffle 过程就是启用合并机制,合并机制就是复用buffer,开启合并机制的配置是spark.shuffle.consolidateFiles。该参数默认值为false,将其设置为true即可开启优化机制。通常来说,如果我们使用HashShuffleManager,那么都建议开启这个选项。
这里还是有 4 个Tasks,数据类别还是分成 3 种类型,因为Hash算法会根据你的 Key 进行分类,在同一个进程中,无论是有多少过Task,都会把同样的Key放在同一个Buffer里,然后把Buffer中的数据写入以Core数量为单位的本地文件中,(一个Core只有一种类型的Key的数据),每1个Task所在的进程中,分别写入共同进程中的3份本地文件,这里有4个Mapper Tasks,所以总共输出是 2个Cores x 3个分类文件 = 6个本地小文件。
5.3 SortShuffle 解析
5.3.1 普通 SortShuffle
在该模式下,数据会先写入一个数据结构,reduceByKey 写入 Map,一边通过 Map 局部聚合,一遍写入内存。Join 算子写入 ArrayList 直接写入内存中。然后需要判断是否达到阈值,如果达到就会将内存数据结构的数据写入到磁盘,清空内存数据结构。
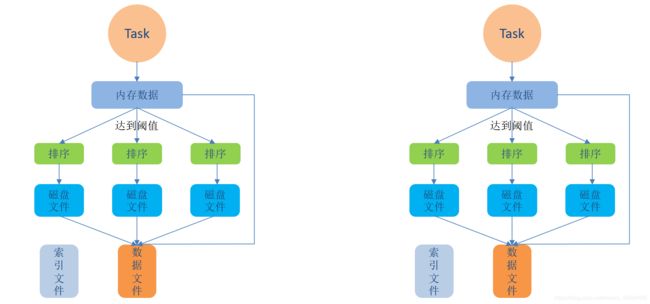
在溢写磁盘前,先根据 key 进行排序,排序过后的数据,会分批写入到磁盘文件中。默认批次为 10000 条,数据会以每批一万条写入到磁盘文件。写入磁盘文件通过缓冲区溢写的方式,每次溢写都会产生一个磁盘文件,也就是说一个 Task 过程会产生多个临时文件。
最后在每个 Task 中,将所有的临时文件合并,这就是merge过程,此过程将所有临时文件读取出来,一次写入到最终文件。意味着一个Task的所有数据都在这一个文件中。同时单独写一份索引文件,标识下游各个Task的数据在文件中的索引,start offset和end offset。
5.3.2 bypassSortShuffle
bypass运行机制的触发条件如下(必须同时满足):
- shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值,默认为200。
- 不是聚合类的shuffle算子(没有预聚合)(比如groupByKey)。
此时 task 会为每个 reduce 端的 task 都创建一个临时磁盘文件,并将数据按 key 进行 hash 然后根据key 的 hash 值,将 key 写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
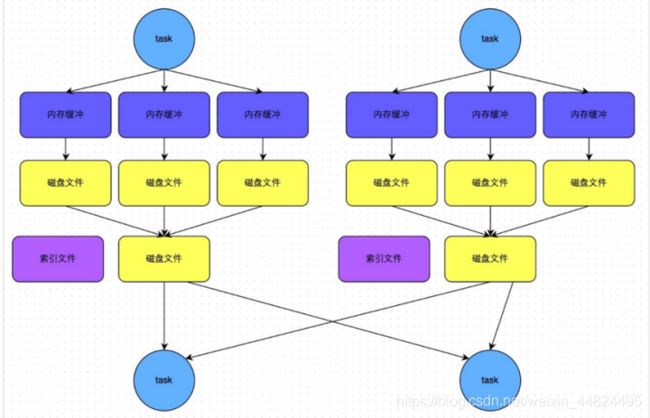
该过程的磁盘写机制其实跟未经优化的 HashShuffleManager 是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的HashShuffleManager来说,shuffle read的性能会更好。 而该机制与普通SortShuffleManager运行机制的不同在于:不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
5.3.3 普通 SortShuffle 源码解析
write 方法
override def write(records: Iterator[Product2[K, V]]): Unit = {
// 排序器
sorter = if (dep.mapSideCombine) {
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
// care whether the keys get sorted in each partition; that will be done on the reduce side
// if the operation being run is sortByKey.
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
// 将 Map 任务的输出记录插入到缓存中
sorter.insertAll(records)
// 数据 shuffle 数据文件
val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
try { // 将 map 端缓存的数据写入到磁盘中, 并生成 Block 文件对应的索引文件.
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
// 记录各个分区数据的长度
val partitionLengths = sorter.writePartitionedFile(blockId, tmp)
// 生成 Block 文件对应的索引文件. 此索引文件用于记录各个分区在 Block文件中的偏移量, 以便于
// Reduce 任务拉取时使用
shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
} finally {
}
}
5.3.4 bypass SortShuffle 源码解析
有时候, map 端不需要在持久化数据之前进行排序等操作, 那么 ShuffleWriter的实现类之一BypassMergeSortShuffleWriter 就可以派上用场了.
触发 BypassMergeSort
private[spark] object SortShuffleWriter {
def shouldBypassMergeSort(conf: SparkConf, dep: ShuffleDependency[_, _, _]): Boolean = {
// We cannot bypass sorting if we need to do map-side aggregation.
// 如果 map 端有聚合, 则不能绕过排序
if (dep.mapSideCombine) {
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
false
} else {
val bypassMergeThreshold: Int = conf.getInt("spark.shuffle.sort.bypassMergeThreshold", 200)
// 分区数不能超过200 默认值
dep.partitioner.numPartitions <= bypassMergeThreshold
}
}
}
6.Spark 内存管理
Spark 与 Hadoop 的重要区别之一就在于对内存的使用.
Hadoop 只将内存作为计算资源, Spark 除将内存作为计算资源外, 还将内存的一部分纳入到存储体系中. Spark 使用 MemoryManage 对存储体系和计算使用的内存进行管理.
6.1 堆内和堆外内存规划
Spark 将内存从逻辑上区分为堆内内存和堆外内存, 称为内存模型(MemoryMode).
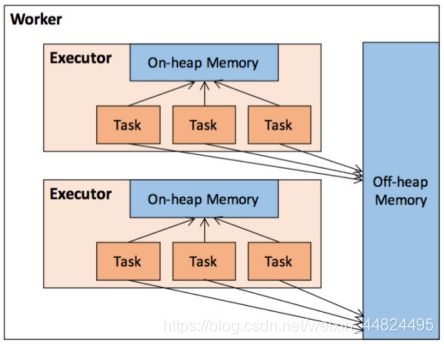
枚举类型MemoryMode中定义了堆内存和堆外内存:
@Private
public enum MemoryMode {
ON_HEAP, // 堆内内存
OFF_HEAP // 堆外内存
}
说明:
- 这里的堆内存不能与 JVM 中的 Java 堆直接画等号, 它只是 JVM 堆内存的一部分. 由 JVM 统一管理
- 堆外内存则是 Spark 使用 sun.misc.Unsafe的 API 直接在工作节点的系统内存中开辟的空间.
1.内存池:
无论前面的哪种内存, 都需要一个内存池对内存进行资源管理, 抽象类MemoryPool定义了内存池的规范:
private[memory] abstract class MemoryPool(lock: Object) {
@GuardedBy("lock")
private[this] var _poolSize: Long = 0
/**
* Returns the current size of the pool, in bytes.
*/
final def poolSize: Long = lock.synchronized {
_poolSize
}
/**
* Returns the amount of free memory in the pool, in bytes.
*/
final def memoryFree: Long = lock.synchronized {
_poolSize - memoryUsed
}
/**
* Expands the pool by `delta` bytes.
*/
final def incrementPoolSize(delta: Long): Unit = lock.synchronized {
require(delta >= 0)
_poolSize += delta
}
/**
* Shrinks the pool by `delta` bytes.
*/
final def decrementPoolSize(delta: Long): Unit = lock.synchronized {
require(delta >= 0)
require(delta <= _poolSize)
require(_poolSize - delta >= memoryUsed)
_poolSize -= delta
}
/**
* Returns the amount of used memory in this pool (in bytes).
*/
def memoryUsed: Long
}
有两个实现类:

2.堆内内存
堆内内存的大小由 Spark 应用程序启动时的-executor-memory 或 spark.executor.memory 参数配置.
- Executor 内运行的并发任务共享 JVM 堆内内存, 这些任务在缓存 RDD 数据和广播数据时占用的内存被规划为存储内存
- 而这些任务在执行 Shuffle 时占用的内存被规划为执行内存.
- 剩余的部分不做特殊规划, 那些 Spark 内部的对象实例, 或者用户定义的 Spark 应用程序中的对象实例, 均占用剩余的空间.
不同的管理模式下, 这三部分占用的空间大小各不相同.
Spark 对堆内内存的管理是一种逻辑上的”规划式”的管理,因为对象实例占用内存的申请和释放都由 JVM 完成,Spark 只能在申请后和释放前记录这些内存,我们来看其具体流程:
申请内存流程如下:
- Spark 在代码中 new 一个对象实例;
- JVM 从堆内内存分配空间,创建对象并返回对象引用;
- Spark 保存该对象的引用,记录该对象占用的内存。
释放内存流程如下:
- Spark记录该对象释放的内存,删除该对象的引用;
- 等待JVM的垃圾回收机制释放该对象占用的堆内内存。
存在的问题
- 我们知道,JVM 的对象可以以序列化的方式存储,序列化的过程是将对象转换为二进制字节流,本质上可以理解为将非连续空间的链式存储转化为连续空间或块存储,在访问时则需要进行序列化的逆过程——反序列化,将字节流转化为对象,序列化的方式可以节省存储空间,但增加了存储和读取时候的计算开销。
- 对于 Spark 中序列化的对象,由于是字节流的形式,其占用的内存大小可直接计算,而对于非序列化的对象,其占用的内存是通过周期性地采样近似估算而得,即并不是每次新增的数据项都会计算一次占用的内存大小,这种方法降低了时间开销但是有可能误差较大,导致某一时刻的实际内存有可能远远超出预期。
- 此外,在被 Spark 标记为释放的对象实例,很有可能在实际上并没有被 JVM 回收,导致实际可用的内存小于 Spark 记录的可用内存。所以 Spark 并不能准确记录实际可用的堆内内存,从而也就无法完全避免内存溢出(OOM, Out of Memory)的异常。
- 虽然不能精准控制堆内内存的申请和释放,但 Spark 通过对存储内存和执行内存各自独立的规划管理,可以决定是否要在存储内存里缓存新的 RDD,以及是否为新的任务分配执行内存,在一定程度上可以提升内存的利用率,减少异常的出现。
3. 堆外内存
为了进一步优化内存的使用以及提高 Shuffle 时排序的效率,Spark 引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据。
堆外内存意味着把内存对象分配在 Java 虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机)。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响。
利用 JDK Unsafe API,Spark 可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的 GC 扫描和回收,提升了处理性能。
堆外内存可以被精确地申请和释放(堆外内存之所以能够被精确的申请和释放,是由于内存的申请和释放不再通过JVM机制,而是直接向操作系统申请,JVM对于内存的清理是无法准确指定时间点的,因此无法实现精确的释放),而且序列化的数据占用的空间可以被精确计算,所以相比堆内内存来说降低了管理的难度,也降低了误差。
在默认情况下堆外内存并不启用,可通过配置 spark.memory.offHeap.enabled 参数启用,并由 spark.memory.offHeap.size 参数设定堆外空间的大小。
除了没有 other 空间,堆外内存与堆内内存的划分方式相同,所有运行中的并发任务共享存储内存和执行内存。
6.2 内存空间分配
6.2.1 静态内存管理(Static Memory Manager)
在 Spark1.6之前采用的静态内存管理机制下,存储内存、执行内存和其他内存的大小在 Spark 应用程序运行期间均为固定的,但用户可以在应用程序启动前进行配置.
堆内内存管理:
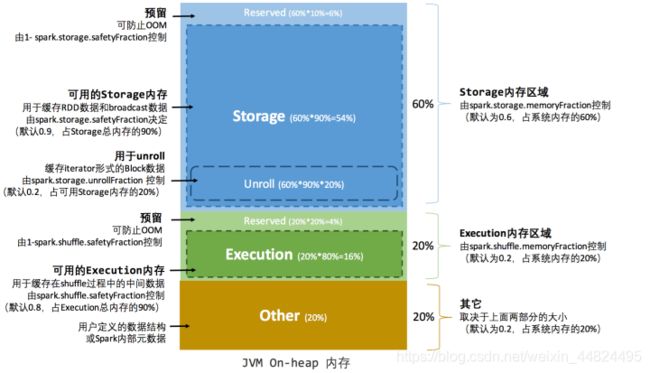
- Storage 内存(Storage Memory): 主要用于存储 Spark 的 cache 数据,例如 RDD 的缓存、Broadcast 变量,Unroll 数据等。
- Execution 内存(Execution Memory):主要用于存放 Shuffle、Join、Sort、Aggregation 等计算过程中的临时数据。
- other(有时候也叫用户内存):主要用于存储 RDD 转换操作所需要的数据,例如 RDD 依赖等信息。 预留内存(Reserved Memory):系统预留内存,会用来存储Spark内部对象。
- 预留内存(Reserved Memory): 防止 OOM
可用的存储内存 = systemMaxMemory * spark.storage.memoryFraction * spark.storage.safety Fraction
可用的执行内存 = systemMaxMemory * spark.shuffle.memoryFraction * spark.shuffle.safety Fraction
其中 systemMaxMemory 取决于当前 JVM 堆内内存的大小,最后可用的执行内存或者存储内存要在此基础上与各自的 memoryFraction 参数和 safetyFraction 参数相乘得出。
上述计算公式中的两个 safetyFraction 参数,其意义在于在逻辑上预留出 1-safetyFraction 这么一块保险区域,降低因实际内存超出当前预设范围而导致 OOM 的风险(上文提到,对于非序列化对象的内存采样估算会产生误差)。
值得注意的是,这个预留的保险区域仅仅是一种逻辑上的规划,在具体使用时 Spark 并没有区别对待,和”其它内存”一样交给了 JVM 去管理。
Storage内存和Execution内存都有预留空间,目的是防止OOM,因为Spark堆内内存大小的记录是不准确的,需要留出保险区域。
堆外内存管理:
堆外的空间分配较为简单,只有存储内存和执行内存。
可用的执行内存和存储内存占用的空间大小直接由参数 spark.memory.storageFraction 决定,由于堆外内存占用的空间可以被精确计算,所以无需再设定保险区域。

静态内存管理机制实现起来较为简单,但如果用户不熟悉 Spark 的存储机制,或没有根据具体的数据规模和计算任务或做相应的配置,很容易造成“一半海水,一半火焰”的局面,即存储内存和执行内存中的一方剩余大量的空间,而另一方却早早被占满,不得不淘汰或移出旧的内容以存储新的内容。
由于新的内存管理机制的出现,这种方式目前已经很少有开发者使用,出于兼容旧版本的应用程序的目的,Spark 仍然保留了它的实现。
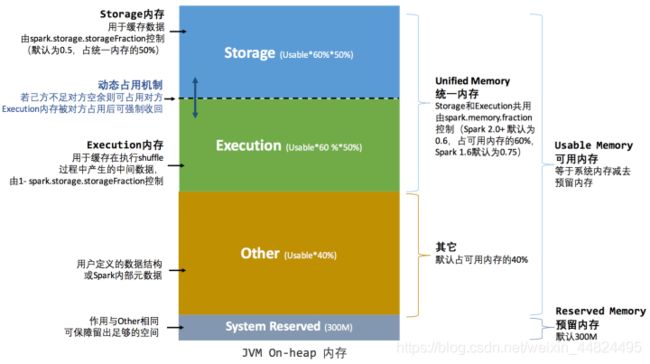
6.2.2 统一内存管理(Unified Memory Manager)
Spark 1.6 之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域.
统一堆内内存管理:
统一堆外内存管理:
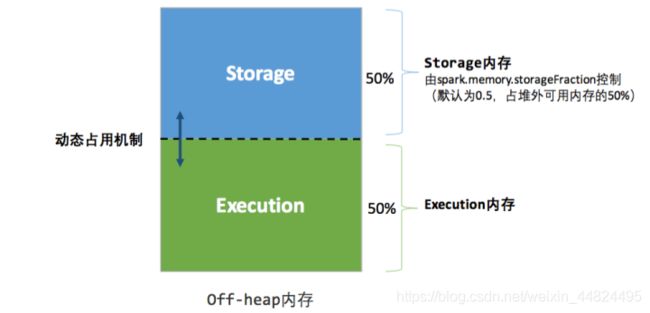
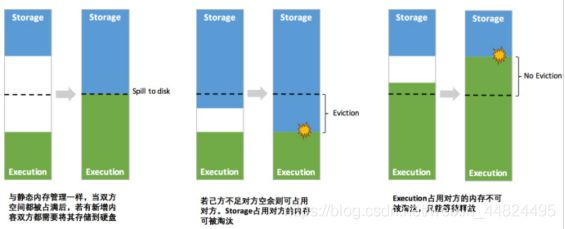
统一内存管理最重要的优化在于动态占用机制, 其规则如下:
- 设定基本的存储内存和执行内存区域spark.storage.storageFraction, 该设定确定了双方各自拥有的空间的范围
- 双方的空间都不足时, 则存储到硬盘. 若己方空间不足而对方空余时, 可借用对方的空间.
- 执行内存的空间被对方占用后, 可让对方讲占用的部分转存到硬盘, 然后“归还”借用的空间
- 存储内存的空间被对方占用后, 无法让对方“归还”, 因为需要考虑 Shuffle 过程中的诸多因素, 实现起来比较复杂.
凭借统一内存管理机制, Spark 在一定程度上提高了堆内内存和堆外内存的利用率, 降低了开发者维护 Spark 内存的难度, 但并不意味着开发者可以高枕无忧.
如果存储内存的空间太大或者说缓存的数据过多,反而会导致频繁的全量垃圾回收,降低任务执行时的性能,因为缓存的 RDD 数据通常都是长期驻留内存的。所以要想充分发挥 Spark 的性能,需要开发者进一步了解存储内存和执行内存各自的管理方式和实现原理。
6.3 存储内存管理
6.3.1 RDD 的持久化机制
RDD 作为 Spark 最基本的数据抽象, 是分区记录(partition)的只读集合, 只能基于在稳定物理存储中的数据集上创建, 或者在其他已有的 RDD 上执行转换(Transformation)操作产生一个新的 RDD.
转换后的 RDD 与原始的 RDD 之间产生的依赖关系, 构成了血统(Lineage). 凭借血统, Spark 可以保证每一个 RDD 都可以被重新恢复.
但 RDD 的所有转换都是惰性的, 即只有当行动(Action)发生时, Spark 才会创建任务读取 RDD, 然后才会真正的执行转换操作.
Task 在启动之初读取一个分区的时, 会先判断这个分区是否已经被持久化, 如果没有则需要检查 Checkpoint 或按照血统重新计算.
如果要在一个 RDD 上执行多次行动, 可以在第一次行动中使用 persis 或 cache 方法, 在内存或磁盘中持久化或缓存这个 RDD, 从而在后面的Action 时提示计算速度.
事实上, cache 方法是使用默认的 MEMORY_ONLY的存储级别将 RDD 持久化到内存, 所以缓存是一种特殊的持久化.
堆内内存和堆外内存的设计, 便可以对缓存 RDD 时使用的内存做统一的规划和管理
RDD 的持久化由 Spark 的 Storage 模块负责, 实现了 RDD 与物理存储的紧耦合.
Storage 模块负责管理 Spark 在计算过程中产生的数据, 将那些在内存或磁盘, 在本地或远程存取数据的功能封装了起来.
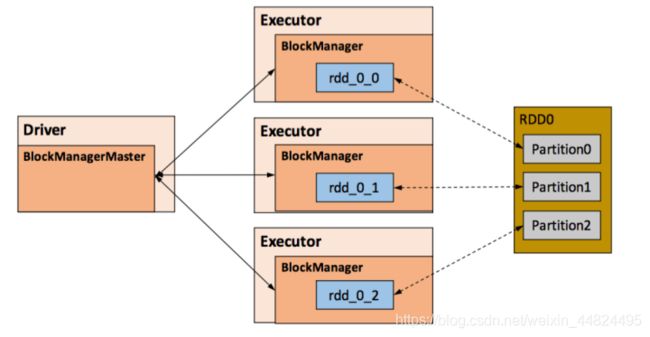
在具体实现时 Driver 端和 Executor 端的 Storage 模块构成了主从式的架构: 即 Driver 端的 BlockManager 为 Master, Executor 端的 BlockManager 为 Slave. Storage 模块在逻辑上以 Block 为基本存储单位, RDD 的每个 Partition 经过处理后唯一对应一个 Block. Master 负责整个 Spark 应用程序的 Block 元数据信息的管理和维护, 而 Slave 需要将 Block 的更新状态上报到 Master, 同时接收 Master 的命令, 例如新增或删除一个 RDD
在对 RDD 持久化时,Spark 规定了 MEMORY_ONLY、MEMORY_AND_DISK 等 7 种不同的存储级别 ,而存储级别是以下 5 个变量的组合:
class StorageLevel private(
private var _useDisk: Boolean,
private var _useMemory: Boolean,
private var _useOffHeap: Boolean,
private var _deserialized: Boolean,
private var _replication: Int = 1)
7 种存储级别请参考: http://www.zhenchao.cf/bigdata_spark_atguigu/di-2-bu-fen-spark-core/di-5-zhang-rdd-bian-cheng/50-rdd-de-chi-jiu-hua.html
通过对数据结构的分析,可以看出存储级别从三个维度定义了 RDD 的 Partition(同时也就是 Block)的存储方式:
- 存储位置:磁盘/堆内内存/堆外内存。如 MEMORY_AND_DISK 是同时在磁盘和堆内内存上存储,实现了冗余备份。OFF_HEAP 则是只在堆外内存存储,目前选择堆外内存时不能同时存储到其他位置。
- 存储形式:Block 缓存到存储内存后,是否为非序列化的形式。如 MEMORY_ONLY 是非序列化方式存储,OFF_HEAP 是序列化方式存储。
- 副本数量:大于 1 时需要远程冗余备份到其他节点。如 DISK_ONLY_2 需要远程备份 1 个副本。
6.3.2 RDD 的缓存过程
RDD 在缓存到存储内存之前, Partition 中的数据一般以迭代器(Iterator)的数据结构来访问, 这是 Scala 语言中遍历数据集合的方法. 通过 Iterator 可以获取分区中每一条序列化或者非序列化的数据项(Record), 这些 Record的对象实例在逻辑上占用了 JVM 堆内内存的 other 部分的空间, 同一 Partition 的不同 Record 的空间并不连续.
RDD 在缓存到存储内存之后, Partition 被转换成 Block, Record 在堆内内存或堆外内存中占用一块连续的空间.
将 Partition 由不连续的存储空间转换为连续存储空间的过程, Spark 称之为展开(Unroll)
Block 有序列化和非序列化两种存储格式, 具体以哪种方式存取决于该 RDD 的存储级别.
非序列化的 Block 以一种 DeserializedMemoryEntry 的数据结构定义, 用一个数组存储所有的对象实例, 序列化的 Block 则以 SerializedMemoryEntry的数据结构定义, 用字节缓冲区(ByteBuffer)来存储二进制数据.
每个 Executor 的 Storage 模块用一个链式 Map 结构(LinkedHashMap)来管理堆内和堆外存储内存中所有的 Block 对象的实例, 对这个LinkedHashMap新增和删除, 间接记录了内存的申请和释放.
因为不能保证存储空间可以一次容纳Iterator中的所有数据, 当前的计算任务在 Unroll 时要向 MemoryManager 申请足够的 Unroll 空间来临时占位, 空间不足则 Unroll 失败, 空间足够时可以继续进行.
对于序列化的 Partition, 其所需的 Unroll 空间可以直接累加计算, 一次申请. 而对于非序列化的 Partition 则要在遍历 Record 的过程中依次申请, 即读取一条 Record, 采用估算器所需的 Unroll 空间并进行申请, 空间不足时可以中断, 释放已占用的 Unroll 空间.
如果最终 Unroll 成功, 当前 Partition 所占用的 Unroll 空间被转换为正常的缓存 RDD 的存储空间.

说明:
•在静态内存管理时,Spark 在存储内存中专门划分了一块 Unroll 空间,其大小是固定的,统一内存管理时则没有对 Unroll 空间进行特别区分,当存储空间不足时会根据动态占用机制进行处理。
6.3.3 淘汰和落盘
由于同一个 Executor 的所有的计算任务共享有限的存储内存空间, 当有新的 Block 需要缓存但是剩余空间不足无法动态占用时, 就要对 LinkedHashMap中的旧 Block 进行淘汰(Eviction), 而被淘汰的 Block 如果其存储级别中同时包含存储到磁盘的要求, 则要对其进行落盘(Drop), 否则就是直接删除该 Block
存储内存的淘汰规则为:
- 被的淘汰的旧 Block 要与新 Block 的 MemoryNode 相同, 即同属于堆内内存或堆外内存
- 新旧Block 不能同属于同一个 RDD, 避免循环淘汰
- 旧 Block 所属 RDD 不能处于被读状态, 避免引发一致性问题
- 遍历 LinkedHashMap 中的 Block, 按照最近最少使用(LRU)的顺序淘汰, 直到满足新 Block 所需的空间.
落盘的流程则比较简单, 如果其存储级别符号_useDisk为true的条件, 再根据其_deserialized判断是否是非序列化的形式, 若是则对其进行序列化, 最后将数据存储到磁盘, 然后在 Storage 模块中更新其信息
6.4 执行内存管理
6.4.1 多任务内存分配
Executor 内运行的任务同样共享执行内存, Spark 用一个 HashMap 结构保存了“任务->内存耗费”的映射.
每个任务可占用的执行内存大小的范围为1/2N ~ 1/N, 其中 N 为当前 Executor 内正在运行的任务的个数.
每个任务在启动之时, 要向 MemoryManage 申请最少 1/2N的执行内存, 如果不能被满足要求则该任务被阻塞,直到有其他任务释放了足够的执行内存, 该任务才可以被唤醒.
6.4.2 Shuffle 的内存占用
执行内存主要用来存储任务在执行 Shuffle 时占用的内存,Shuffle 是按照一定规则对 RDD 数据重新分区的过程,我们来看 Shuffle 的 Write 和 Read 两阶段对执行内存的使用:
Shuffle Write
- 若在 map 端选择普通的排序方式,会采用 ExternalSorter 进行外排,在内存中存储数据时主要占用堆内执行空间。
- 若在 map 端选择 Tungsten 的排序方式,则采用 ShuffleExternalSorter 直接对以序列化形式存储的数据排序,在内存中存储数据时可以占用堆外或堆内执行空间,取决于用户是否开启了堆外内存以及堆外执行内存是否足够。
Shuffle Read - 在对 reduce 端的数据进行聚合时,要将数据交给 Aggregator 处理,在内存中存储数据时占用堆内执行空间。
- 如果需要进行最终结果排序,则要将再次将数据交给 ExternalSorter 处理,占用堆内执行空间。
在 ExternalSorter 和 Aggregator 中,Spark 会使用一种叫 AppendOnlyMap 的哈希表在堆内执行内存中存储数据,但在 Shuffle 过程中所有数据并不能都保存到该哈希表中,当这个哈希表占用的内存会进行周期性地采样估算,当其大到一定程度,无法再从 MemoryManager 申请到新的执行内存时,Spark 就会将其全部内容存储到磁盘文件中,这个过程被称为溢存(Spill),溢存到磁盘的文件最后会被归并(Merge)。
Shuffle Write 阶段中用到的 Tungsten(钨丝) 是 Databricks 公司提出的对 Spark 优化内存和 CPU 使用的计划(钨丝计划),解决了一些 JVM 在性能上的限制和弊端。Spark 会根据 Shuffle 的情况来自动选择是否采用 Tungsten 排序。
Tungsten 采用的页式内存管理机制建立在 MemoryManager 之上,即 Tungsten 对执行内存的使用进行了一步的抽象,这样在 Shuffle 过程中无需关心数据具体存储在堆内还是堆外。每个内存页用一个 MemoryBlock 来定义,并用 Object obj 和 long offset 这两个变量统一标识一个内存页在系统内存中的地址。
堆内的 MemoryBlock 是以 long 型数组的形式分配的内存,其 obj 的值为是这个数组的对象引用,offset是 long 型数组的在 JVM 中的初始偏移地址,两者配合使用可以定位这个数组在堆内的绝对地址;
堆外的 MemoryBlock 是直接申请到的内存块,其 obj 为 null,offset 是这个内存块在系统内存中的 64 位绝对地址。Spark 用 MemoryBlock 巧妙地将堆内和堆外内存页统一抽象封装,并用页表(pageTable)管理每个 Task 申请到的内存页。
Tungsten 页式管理下的所有内存用 64 位的逻辑地址表示,由页号和页内偏移量组成:
页号:占 13 位,唯一标识一个内存页,Spark 在申请内存页之前要先申请空闲页号。 页内偏移量:占 51 位,是在使用内存页存储数据时,数据在页内的偏移地址。 有了统一的寻址方式,Spark 可以用 64 位逻辑地址的指针定位到堆内或堆外的内存,整个 Shuffle Write 排序的过程只需要对指针进行排序,并且无需反序列化,整个过程非常高效,对于内存访问效率和 CPU 使用效率带来了明显的提升[10]。
Spark 的存储内存和执行内存有着截然不同的管理方式:对于存储内存来说,Spark 用一个 LinkedHashMap 来集中管理所有的 Block,Block 由需要缓存的 RDD 的 Partition 转化而成;而对于执行内存,Spark 用 AppendOnlyMap 来存储 Shuffle 过程中的数据,在 Tungsten 排序中甚至抽象成为页式内存管理,开辟了全新的 JVM 内存管理机制。