SparkSQL代码笔记03——连接hive
一、使用内置hive
ps:需要注意内置hive是非常容易出现问题的
1.先启动集群/opt/software/spark-2.2.0-bin-hadoop2.7/sbin/start-all.sh
2.进入到spark-shell模式/opt/software/spark-2.2.0-bin-hadoop2.7/bin/spark-shell --master spark://hadoop01:7077
3.在spark-shell下操作hive
spark.sql("show tables").show 查询所有hive的表
spark.sql("CREATE TABLE IF NOT EXISTS src (key INT,value STRING)") 创建表
spark.sql("LOAD DATA LOCAL INPATH '/opt/software/spark-2.2.0-bin-hadoop2.7/examples/src/main/resources/kv1.txt' INTO TABLE src") 添加数据
spark.sql("SELECT * FROM src").show 查询表中数据
会出现一个问题FileNotFoundException 没有找到文件
通过在主节点和从节点查询可以发现,主节点存在spark-warehouse目录 目录中是存在数据的
但是在从节点中没有这个文件夹,所以此时将文件夹分发到从节点
scp -r ./spark-warehouse/ root@hadoop02:$PWD
再次执行查询
ps:这样表面看查询是没什么问题了,但是实际问题在于是将master节点上的数据分发到从节点上的,那么不可能说每次操作有了数据都执行拷贝操作,所以此时就需要使用HDFS来进行存储数据了
所以先将所有从节点上的spark-warehouse删除掉
删除后将主节点上的spark-warehouse和metastor_db删除掉
然后在启动集群的时候添加一个命令
--conf spark.sql.warehouse.dir=hdfs://hadoop01:8020/spark_warehouse
此方法只做一次启动即可 后续再启动集群的时候就无需添加这个命令了,因为记录在metastore_db中了
ps:spark-sql中可以直接使用SQL语句操作
二、集成外部hive
1.将Hive中的hive-site.xml软连接到Spark安装目录下的conf目录下。[主节点有即可]
ln -s /opt/software/apache-hive-1.2.1-bin/conf/hive-site.xml /opt/software/spark-2.2.0-bin-hadoop2.7/conf/hive-site.xml
ps:或者直接复制粘贴到此目录下即可
2.打开spark shell,注意带上访问Hive元数据库的JDBC客户端
将mysql驱动jar包拷贝到spark的bin目录下
./spark-shell --master spark://hadoop01:7077 --jars mysql-connector-java-5.1.36.jar
ps:做完外部hive链接需要注意,因为hive-site.xml文件是在Spark的conf目录下,若直接启动spark-shell无论是单机版还是集群版都会出现报错 Error creating transactional connection factory 原因在于,启动时会加载hive-site.xml文件,所以必须添加jar路径, 为了以后使用建议删除软连接,需要的时候在做外部hive的连接
删除软连接方式:
rm -rf 软连接方式
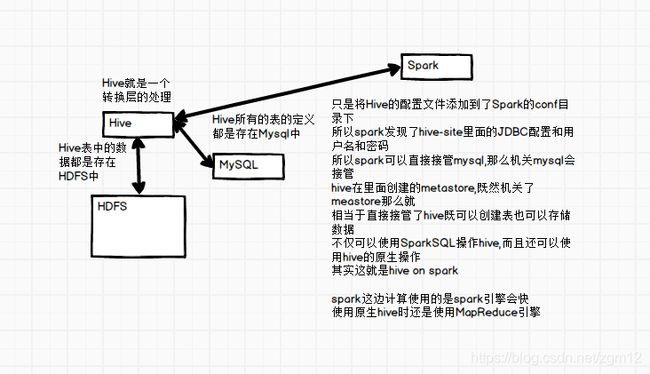
总结:
若要把Spark SQL连接到一个部署好的Hive上,你必须把hive-site.xml复制到 Spark的配置文件目录中($SPARK_HOME/conf)。即使没有部署好Hive,Spark SQL也可以运行。 需要注意的是,如果你没有部署好Hive,Spark SQL会在当前的工作目录中创建出自己的Hive 元数据仓库,叫作 metastore_db。此外,如果你尝试使用 HiveQL 中的 CREATE TABLE (并非 CREATE EXTERNAL TABLE)语句来创建表,这些表会被放在你默认的文件系统中的 /user/hive/warehouse 目录中(如果你的 classpath 中有配好的 hdfs-site.xml,默认的文件系统就是 HDFS,否则就是本地文件系统)。
三、Idea中代码操作
3.1 本地运行
ps:需要有Hadoop本地环境 //这样不会在hive中创建表
package scalaBase.day15
import org.apache.spark.sql.SparkSession
//本地模式,不用hive-site.xml hdfs-site.xml core-site.xml,
// 但是路径报错LOAD DATA input path does not exist: data/kv1.txt;
object HiveCodeDemo1 {
def main(args: Array[String]): Unit = {
val spark= SparkSession.builder()
.appName("hivelocal")
.config("spark.sql.warehouse.dir","f://spark-warehouse")
.master("local")
.enableHiveSupport()
.getOrCreate()
import spark.implicits._
spark.sql("create table if not exists skv1(key int, value string)")
// spark.sql("load data local inpath 'f:/kv1.txt' into table skv1") //路径报错
spark.sql("select * from skv1").show()
spark.sql("select count(1) from skv1").show()
spark.stop()
}
}
3.2 集群运行
运行的时候,实际上hive开不开无所谓,因为其实是spark与mysql中的元数据进行的连接,会在hive中创建表
ps:需要添加hive-site.xml hdfs-site.xml core-site.xml 到resources目录下
ps:如果是本地执行,并不提交到集群,那么删掉这三个,不然报错:路径找不到,因为会到hdfs上去找
package scalaBase.day15
import org.apache.spark.sql.SparkSession
object HiveCodeDemo2 {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("hivecode2")
.config("spark.sql.warehouse.dir","hdfs://mini1:9000/spark-warehouse")
// .master("local")
.enableHiveSupport()
.getOrCreate()
spark.sql("create table if not exists skv2(key int,value string)")
spark.sql("load data local inpath '/zgm/kv1.txt' into table skv2")
spark.sql("select * from skv2").show()
spark.stop()
}
}
/usr/local/spark-2.2.0-bin-hadoop2.6/bin/spark-submit \
--class scalaBase.day15.HiveCodeDemo2 \
--master spark://mini1:7077 \
--executor-memory 512m \
--total-executor-cores 2 \
--jars /ajar/mysql-connector-java-5.1.35-bin.jar \ //这里一定要加上
/ajar/hiveCode2.jar