clustering k-means
程序给出了k-means的用法和简单的pandas操作excel
1.选择一个参数k,也就是聚类时分成几类
2,随机选择k个中心点
3,计算每个样本到中心的距离,把这个样本归为与中心距离最近的那一类
4,更新中心
5,重复3,4步。达到最大迭代次数或者中心不发生变化,重复结束
距离公式:
首先help(np.linalg.norm)查看其文档:
norm(x, ord=None, axis=None, keepdims=False)
- 1
| 参数 | 说明 | 计算方法 |
|---|---|---|
| 默认 | 二范数:ℓ2 | x21+x22+…+x2n−−−−−−−−−−−−−−−√ |
| ord=2 | 二范数:ℓ2 | 同上 |
| ord=1 | 一范数:ℓ1 | |x1|+|x2|+…+|xn| |
| ord=np.inf | 无穷范数:ℓ∞ | max(|xi|) |
程序如下:
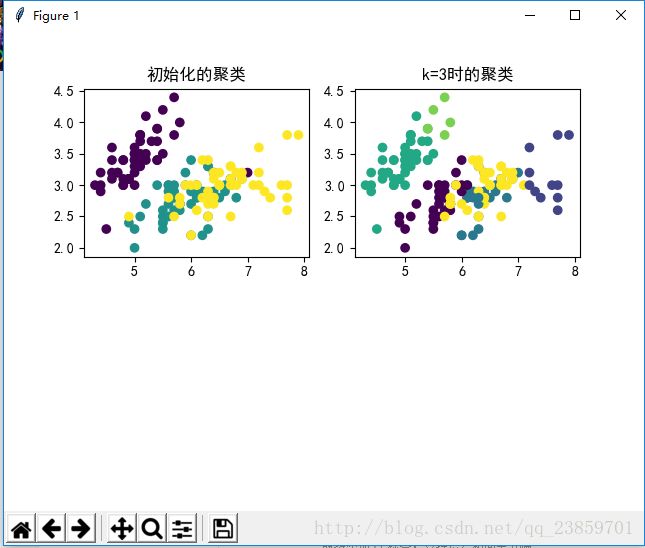
import numpy as np from sklearn import datasets import pandas as pd import matplotlib.pyplot as plt from pylab import mpl '''练习一下pandas操作excel表 ''' def pandas_data():#从sklearn中加载数据,然后使用pandas写到excel转成int方便聚类,再使用pandas读取出来。 data=datasets.load_iris()#加载iris库 data_df=pd.DataFrame(data['data'])#iris是一个数组,一个是data和target data_df.columns=['A','B','C','D'] data_df.index = range(150) writer = pd.ExcelWriter('Save_Excel.xlsx')#将加载的数据保存为excel data_df.to_excel(writer, 'page_1', float_format='%.5f')#保存的精度为%.5f writer.save() df=np.mat(pd.read_excel('Save_Excel.xlsx', skiprows=[0]))#读取出来 x=df[1:149,1:5] target=data['target'][0:148] m,n=np.shape(x) y=np.zeros((m,n+1)) y[:,:-1]=x y[:,-1] =target return x ,y#得到一个有特征没有标签的x,和带标签的y,为了测试精度 ''' k-means算法的主程序 ''' def k_means(x,k,maxiter): m,n=np.shape(x) y=np.zeros((m,n+1)) y[:,:-1]=x centerpoint=y[np.random.randint(1,high=m,size=k),:] #随机得到k个中心点 for i in range(k): centerpoint[i,-1]=i oldpoint=None iternumber=0 # 主循环(当迭代次数iternumber=maxiter时或者中心点不变时,循环结束) while shouldstop(centerpoint,oldpoint,iternumber,maxiter): oldpoint=np.copy(centerpoint) iternumber+=1 for i in range(m): y[i,-1]=cal_dist(x[i,:],centerpoint) centerpoint=up_centerpoint(y,k) return y def plot_show(y,y_pred): mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体:解决plot不能显示中文问题 mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题 plt.subplot(221) plt.scatter(y[:,0], y[:,1], c=y[:, -1]) plt.title("初始化的聚类") plt.subplot(222) plt.scatter(y_pred[:,0], y_pred[:,1], c=y_pred[:,-1]) plt.title("k=3时的聚类") plt.show() ''' 更新中心点 ''' def up_centerpoint(y,k): result=np.zeros((k,y.shape[1])) for i in range(k): temp = y[y[:, -1] == i, :-1] result[i,:-1]=np.mean(temp,axis=0) result[i,-1]=i return ''' 计算每个点与中心点的距离,将这个点归为与中心点距离最近的那一类 ''' def cal_dist(x,centerpoint): m,n=np.shape(centerpoint) bestlable=centerpoint[0,-1] bestdist=np.linalg.norm(x-centerpoint[0,0:-1]) for i in range(1,m): dist=np.linalg.norm(x-centerpoint[i,0:-1]) if dist<bestdist: bestdist=dist bestlable=centerpoint[i,-1] return bestlable ''' 控制主循环是否结束 ''' def shouldstop(centerpoint,oldpoint,iternumber,maxiter):# if iternumber<maxiter: return True if np.array_equal(centerpoint,oldpoint): return False def main(): k=6 maxiter=1 x,y=pandas_data() y_predict=k_means(x,k,maxiter) plot_show(y,y_predict) if __name__ == '__main__': main()
结果显示: