机器学习相关知识点记录
文章目录
- 机器学习思维导图
- 机器学习思维导图1
- 机器学习思维导图2
- 机器学习思维导图3
- 聚类算法
- DBSCAN算法
- NBC算法
- 待补充
- 分割线
- 分割线
机器学习思维导图
机器学习思维导图1

转自:机器学习思维导图_wlkdb的博客 20180620
机器学习思维导图2
GitHub - dformoso/machine-learning-mindmap: A mindmap summarising Machine Learning concepts, from Data Analysis to Deep Learning.
机器学习思维导图3

转自:机器学习6种简单实用算法及学习曲线、思维导图 20200108
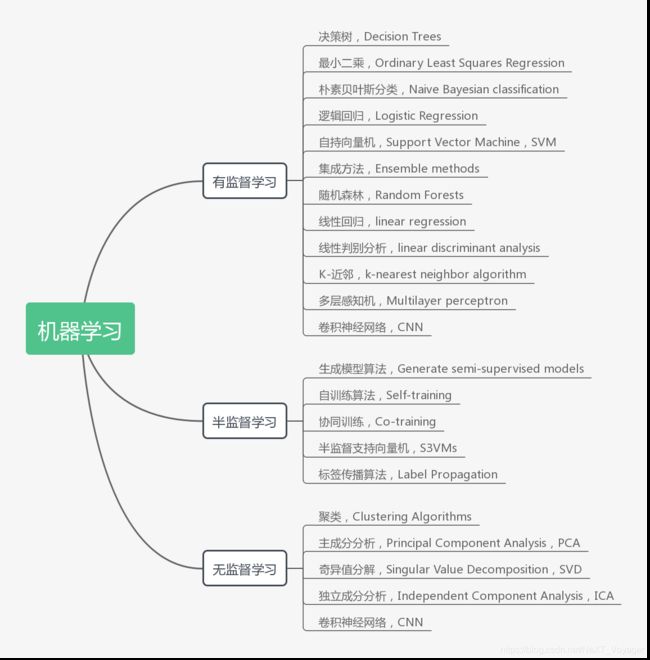
转自:一张机器学习算法的思维导图_麦田里的守望者 20190908
聚类算法
DBSCAN算法
Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
DBSCAN算法具有以下特点:
- DBSCAN可以识别数据中任意形状的簇和噪声(异常值);
- 与k-means聚类不同,DBSCAN不需要簇的数量这一先验知识,且簇不一定是球状的;
- DBSCAN在基于密度的离群值检测中也很有用,因为它可以识别不属于任何簇的离群点;
DBSCAN算法需要2个输入参数:epsilon, minpts;
对于一个样本点,只有满足“在其以epsilon为半径的邻域内至少包含有minpts(核心点的最少邻居数)个样本点”的条件,才能将其划分为一个簇;
The DBSCAN algorithm identifies three kinds of points:
- Core point — A point in a cluster that has at least minpts neighbors in its epsilon neighborhood
- Border point — A point in a cluster that has fewer than minpts neighbors in its epsilon neighborhood
- Noise point — An outlier that does not belong to any cluster
Matlab工具箱中实现的DBSCAN算法的处理步骤:
- Step 1:给定输入点集x,任意选择第1个未标记点x1作为当前点x_curr,初始化其簇标签C=1;
- Step 2:寻找在当前点x_curr的epsilon邻域范围内的所有邻居点,得到一个点集points_x1;
如果点集points_x1中点数量少于minpts,则修改当前点x_curr的簇标签为a noise point (or an outlier),并跳转至Step 4;
如果点集points_x1中点数量大于等于minpts,则当前点x_curr可被视为属于簇标签C的a core point; - Step 3:迭代取点集points_x1中的点作为当前点x_curr执行Step 2,直至没有新的可以标记属于簇标签C的邻居点被发现;
- Step 4:选择下一个未标记点作为当前点x_curr,初始化其簇标签C=C+1,执行Step2;
- Step 5:重复Step 2-Step 4,直至输入点集x中的所有点都被打了标记;
DBSCAN算法尚存在的缺陷:
DBSCAN利用epsilon, minpts来度量数据的绝对全局密度,但只采用了一组参数,无法区分小的、靠近的、密集的簇和大的、稀疏的簇;
DBSCAN - MATLAB & Simulink - MathWorks 中国
DBSCAN聚类算法——机器学习(理论+图解+python代码)_huacha__的博客 20180726
20分钟看懂DBSCAN的基本原理 - 知乎 20191027
NBC算法
NBC聚类算法也是一种基于邻域的聚类算法,它根据数据的邻域特征/邻域关系发现簇(clusters)。
NBC算法具有以下优点:
- (1)NBC算法能有效发现任意分布(不同密度、多种间隔尺寸)的簇;
- (2) NBC比现有聚类算法需要更少的输入参数,NBC只需要1个输入参数(k值),而DBSCAN需要三个输入参数(k值、邻域半径和密度阈值);
- (3) NBC uses cell-based structure and VA file [3] to organize the targeted data, 因而对于大型、高维数据库的聚类也很高效和可拓展性好;
实验表明,NBC在聚类效果和聚类效率上都优于DBSCAN。
作者不将NBC视作是现有聚类方法的一个替代,而是视为一个很好的补充。
NBC的核心概念是邻域密度因子NDF,NDF是一种相对局部密度度量,区别于DBSCAN中所使用的绝对全局密度度量;
“那些k-最近邻中包含点p的点的数量应该不少于点p的k-最近邻中所包含的点的数量;”这句话这么理解:点p的k-最近邻中所包含的点的数量即是k个,但点p肯定会落入 数量不少于k个的点 的k-最近邻中;
the definitions of k-nearest neighbors set and reverse k-nearest neighbors set.
the definitions of an object’s neighborhood.
the definitions of the reverse k-Neighborhood
def1 kNN§: 点p的k个最近邻点的集合;(点p不计数,即kNN§中不包含点p)
def2 R-kNN§: 那些k-最近邻中包含点p的点的集合;
def3 rNB§: 点p的邻域(以p为中心,r为半径)中所包含的点的集合;(rNB§中不包含点p)
def4 kNB§: 距点p距离等于“kNN§中距点p的最远距离”的点的集合;(例如,点p的k-th, (k+1)-th, …最近邻点与点p的距离可能相等呢)
def5 R-kNB§: 那些kNB()中包含点p的点的集合;

从局部视角看,数据库中的数据点可以唯一地分为三种类型:密集点、稀疏点和均匀分布点(dense point, sparse point and even/uniformly distribution point)。直觉上,簇内部的点应该是稠密点或偶数点,簇边界上的点大多为稀疏点;离群点和噪声也是稀疏点。
def6 NDF的定义
With NDF, we give the definitions of three types of data points in local sense: local even points, local dense points and local sparse points.
def10 基于邻域的密度直达
def11 基于邻域的密度可达
def12 基于邻域的密度相连
NBC算法的处理步骤:
- Step 1:给定输入点集x,任意选择第1个未标记点x1作为当前点x_curr,初始化其簇标签C=1;
- Step 2:计算当前点x_curr的NDF()值:
如果当前点x_curr是a DP or EP,即NDF(x_curr)>=1,则可将其纳入簇标签C的簇;
如果当前点x_curr是a SP,即NDF(x_curr)<1,则暂时将其放在一边,并跳转至Step 5; - Step 3:寻找当前点x_curr的密度直达点,得到一个点集points_x1,标记它们的簇标签为C;
- Step 4:迭代取点集points_x1中的点作为当前点x_curr执行Step 3,直至没有新的可以标记属于簇标签C的密度直达点被发现;
- Step 5:选择下一个未标记点作为当前点x_curr,初始化其簇标签C=C+1,执行Step 2;
- Step 6:重复Step 2-Step 5,直至there is no more DP or EP in x to fetch to create clusters;
待补充
数学公式粗体 \textbf{} 或者 m e m o r y {\bf memory} memory
数学公式粗斜体 \bm{}
摘录自“bookname_author”
此文系转载,原文链接:名称 20200505
高亮颜色说明:突出重点
个人觉得,:待核准个人观点是否有误
分割线
分割线
我是颜色为00ffff的字体
我是字号为2的字体
我是颜色为00ffff, 字号为2的字体
我是字体类型为微软雅黑, 颜色为00ffff, 字号为2的字体
分割线
分割线
问题描述:
原因分析:
解决方案: