Linux 内核 list_head 学习(二)
(一)结构体定义
struct list_head {
struct list_head *next,*prev;
};
#define LIST_HEAD_INIT(name){&(name),&(name)}
#define LIST_HEAD(name)\
struct list_head name = LIST_HEAD_INIT(name)
struct list_head {
struct list_head *next,*prev;
};
#define LIST_HEAD_INIT(name){&(name),&(name)}
#define LIST_HEAD(name)\
struct list_head name = LIST_HEAD_INIT(name)
申请一个变量LIST_HEAD(temp)等价于这个:
struct list_head temp = {&(temp), &(temp)}
附带知识:
结构体赋值:
1、对成员赋值
例如结构体struct st1 {
int a;
int b;
int c;
}
1.1 用{}形式
struct st1 st1 = {1,2,3);
1.2 linux kernel风格.
struct st1 st1 = {
.a = 1;
.b = 2;
};
//注 此风格(即在成员变量之前加点“.”),可以不按成员变量的顺序进行赋值。如可以为
struct st1 st1 = {
.c = 3;
.a = 1;
.b = 2;
};
2 对整体赋值.
struct st1 a, b;
b = a;
3 结构体作为函数返回值对另一个结构体赋值.
struct st1 func1();
struct st1 a = func1();
(二)结构体初始化
结构体初始化函数:
static inline void INIT_LIST_HEAD(struct list_head*list)
{
list->next= list;
list->prev= list;
}
static inline void INIT_LIST_HEAD(struct list_head*list)
{
list->next= list;
list->prev= list;
}
初始化结构体list指向自己本身。
对于(一)结构体定义和(二)结构体初始化来说,最终的效果是一样的,都是将一个
struct list_head变量指向自己本身。
可以写一个小的程序测试一下
- /*test.c*/
- #include <stdio.h>
- struct list_head {
- struct list_head *next,*prev;
- };
- #define LIST_HEAD_INIT(name){&(name),&(name)}
- #define LIST_HEAD(name)\
- struct list_head name = LIST_HEAD_INIT(name)
- static inline void INIT_LIST_HEAD(struct list_head*list)
- {
- list->next= list;
- list->prev= list;
- }
- int main()
- {
- LIST_HEAD(temp);
- printf("%p %p %p\n",(&temp)->prev,(&temp)->next,&temp);
- INIT_LIST_HEAD(&temp);
- printf("%p %p %p\n",(&temp)->prev,(&temp)->next,&temp);
- return 0;
- }
- 运行结果:
- ^_^[sunny@sunny-laptop~/DS]11$./a.out
- 0xbf8191a8 0xbf8191a8 0xbf8191a8
- 0xbf8191a8 0xbf8191a8 0xbf8191a8
- ^_^[sunny@sunny-laptop~/DS]12$
可以看出他们完毕之后的地址都是一样的。
(三)增加结点
附带知识:
内联函数 inline
在c 中,为了解决一些频繁调用的小函数而大量消耗栈空间或者是叫栈内存的问题,特别的引入了inline修饰符,表示为内联函数。
内联函数使用inline关键字定义,
并且函数体和声明必须结合在一起,
否则编译器将他作为普通函数对待。
inline void function(int x); //仅仅是声明函数,没有任何效果
inline void function(int x) //正确
{
return x;
}
内联函数 inline
在c 中,为了解决一些频繁调用的小函数而大量消耗栈空间或者是叫栈内存的问题,特别的引入了inline修饰符,表示为内联函数。
内联函数使用inline关键字定义,
并且函数体和声明必须结合在一起,
否则编译器将他作为普通函数对待。
inline void function(int x); //仅仅是声明函数,没有任何效果
inline void function(int x) //正确
{
return x;
}
增加结点的话,有两种方式:头插法和尾插法。
我们调用的话就调用
static inline void list_add(struct list_head *new, struct list_head *head);
static inline void list_add_tail(struct list_head *new, struct list_head *head);
这两个接口。
头插法:
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
尾插法:
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
真正的实现插入:
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
__list_add(new, prev, next):表示在prev和next之间添加一个新的节点new
所以对于list_add()中的__list_add(new, head, head->next)表示的在head和
head->next之间加入一个新的节点,是头插法。
对于list_add_tail()中的__list_add(new, head->prev, head)表示在head->prev(双向循环链表的最后一个结点)和head之间添加一个新的结点。
(四)删除结点
(五)替换结点
(四)删除结点
指定一个结点,删除这个结点
我们调用的话,调用
static inline void list_del(struct list_head *entry)
这个函数接口就可以了。
- static inline void __list_del(struct list_head* prev, struct list_head*next)
- {
- next->prev= prev;
- prev->next=next;
- }
- static inline void list_del(struct list_head*entry)
- {
- __list_del(entry->prev, entry->next);
- entry->next= LIST_POISON1;
- entry->prev= LIST_POISON2;
- }
__list_del(entry->prev, entry->next)表示将entry的前一个和后一个之间建立关联。
至于让,
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
LIST_POISON1和LIST_POISON2这两个变量在poison.h中定义的:
#define LIST_POISON1 ((void *) 0x00100100 + POISON_POINTER_DELTA)
#define LIST_POISON2 ((void *) 0x00200200 + POISON_POINTER_DELTA)
prev、next指针分别被设为LIST_POSITION2和LIST_POSITION1两个特殊值,这样设置是为了保证不在链表中的节点项不可访问(对LIST_POSITION1和LIST_POSITION2的访问都将引起页故障)。
还有一个删除操作的接口函数
- static inline void list_del_init(struct list_head*entry)
- {
- __list_del(entry->prev, entry->next);
- INIT_LIST_HEAD(entry);
- }
这个函数首先将entry从双向链表中删除之后,并且将entry初始化为一个空链表。
list_del(entry)和list_del_init(entry)唯一不同的是对entry的处理,前者是将entry设置为不可用,后者是将其设置为一个空的链表的开始。
(五)替换结点
结点的替换操作是将old的结点替换成new,提供的接口是
static inline void list_replace_init(struct list_head *old,
struct list_head *new);
下面是替换的有关代码
- static inline void list_replace(struct list_head*old,
- struct list_head *new)
- {
- new->next= old->next;
- new->next->prev= new;
- new->prev= old->prev;
- new->prev->next= new;
- }
- static inline void list_replace_init(struct list_head*old,
- struct list_head *new)
- {
- list_replace(old, new);
- INIT_LIST_HEAD(old);
- }
List_replace_init首先调用list_replace改变new和old的指针关系,然后调用INIT_LIST_HEAD(old)将其设置为一个指向自己的结点(这个操作和前面的删除操作是一样的——初始化)。
(六)结点搬移
搬移就是将一个结点从一个链表但终删除之后,加入到其他的一新的链表当中。这里提供了两个接口:
static inline void list_move(struct list_head *list, struct list_head *head)
static inline void list_move_tail(struct list_head *list,struct list_head *head)
前者是加入的时候使用头插法,后者使用的是尾插法。
static inline void list_move(struct list_head *list, struct list_head *head)
{
__list_del(list->prev, list->next);
list_add(list, head);
}
首先调用__list_del(list->prev, list->next),将list的前一个结点和后一个结点建立联系,之后调用list_add(list, head)将list添加到head的链表。下面的和这个类似,不同的是使用的是尾插法。
static inline void list_move_tail(struct list_head *list,
struct list_head *head)
{
__list_del(list->prev, list->next);
list_add_tail(list, head);
}
(七)检测是否为最后节点、检测链表是否为空、检测链表是不是有一个成员结点
判断list这个结点是不是链表head的最后一个节点。
static inline int list_is_last(const struct list_head *list,
const struct list_head *head)
{
return list->next == head;
}
下面两个接口都是判断head这个链表是不是为一个空链表(也就是只进行过初始化操作或者是刚申请的一个变量)。
- static inline int list_empty(const struct list_head*head)
- {
- return head->next== head;
- }
- static inline int list_empty_careful(const struct list_head*head)
- {
- struct list_head *next = head->next;
- return (next== head)&&(next== head->prev);
- }
list_empty()函数和list_empty_careful()函数都是用来检测链表是否为空的。但是稍有区别的就是第一个链表使用的检测方法是判断表头的结点的下一个结点是否为其本身,如果是则返回为1,否则返回0。第二个函数使用的检测方法是判断表头的前一个结点和后一个结点是否为其本身,如果同时满足则返回0,否则返回值为1。
这主要是为了应付另一个cpu正在处理同一个链表而造成next、prev不一致的情况。但代码注释也承认,这一安全保障能力有限:除非其他cpu的链表操作只有list_del_init(),否则仍然不能保证安全,也就是说,还是需要加锁保护。
下面的这个函数是用来判断head这个链表是不是只有一个成员结点(不算带头结点的那个head)。
- static inline int list_is_singular(const struct list_head*head)
- {
- return !list_empty(head)&&(head->next== head->prev);
- }
(八)旋转链表的第一个节点到最后
这个函数的操作的最终结果是将head的next与head自己本身进行了交换。
- static inline void list_rotate_left(struct list_head*head)
- {
- struct list_head *first;
- if (!list_empty(head)){
- first = head->next;
- list_move_tail(first, head);
- }
- }
(九)分割链表
这里提供的函数接口是:
static inline void __list_cut_position(struct list_head *list,
struct list_head *head, struct list_head *entry)
list:将剪切的结点要加进来的链表
head:被剪切的链表
entry:所指位于由head所指领头的链表内,它可以指向head,但是这样的话,head就不能被剪切了,在代码中调用了INIT_LIST_HEAD(list)。
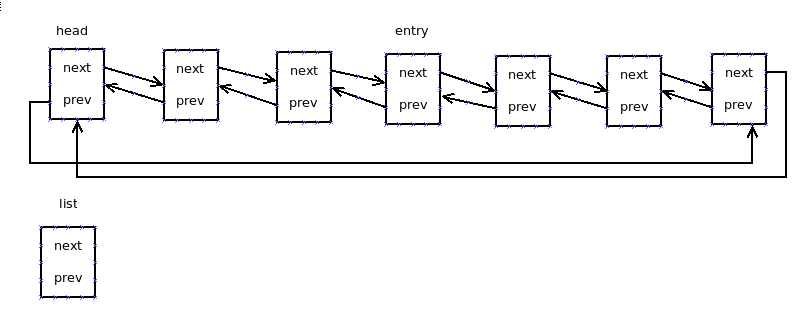
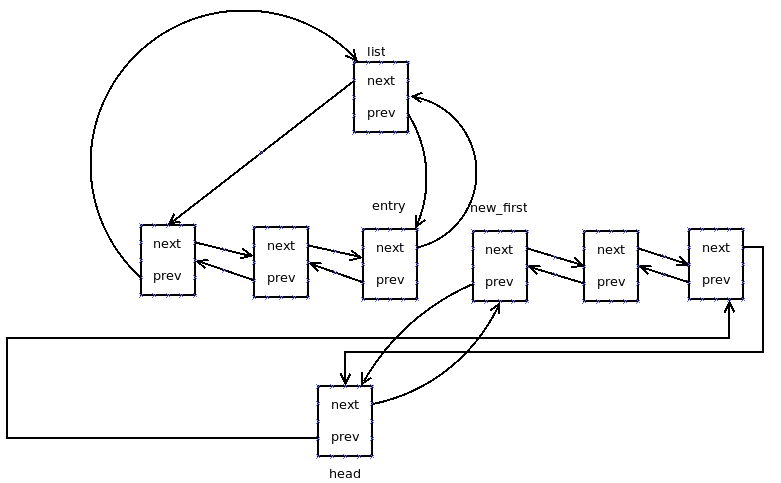
是将head(不包括head)到entry之间的所有结点剪切下来加到list所指向的链表中。这个操作之后就有了两个链表head和list。具体的结果参看下面的截图:
- static inline void list_cut_position(struct list_head*list,
- struct list_head *head, struct list_head *entry)
- {
- if (list_empty(head))
- return;
- if (list_is_singular(head)&&
- (head->next!= entry && head!= entry))
- return;
- if (entry == head)
- INIT_LIST_HEAD(list);
- else
- __list_cut_position(list, head, entry);
- }
真正的分割操作是下面的函数:
- static inline void __list_cut_position(struct list_head*list,
- struct list_head *head, struct list_head *entry)
- {
- struct list_head *new_first = entry->next;
- list->next= head->next;
- list->next->prev= list;
- list->prev= entry;
- entry->next= list;
- head->next= new_first;
- new_first->prev= head;
- }
分割之前的情况:
分割之后的结果:
(十)链表的合并
提供的接口有四个:
static inline void list_splice(const struct list_head *list,
struct list_head *head)
static inline void list_splice_tail(struct list_head *list,
struct list_head *head)
static inline void list_splice_init(struct list_head *list,
struct list_head *head)
static inline void list_splice_tail_init(struct list_head *list,
struct list_head *head)
真正的合并操作是这个函数实现的:
- static inline void __list_splice(const struct list_head*list,
- struct list_head *prev,
- struct list_head *next)
- {
- struct list_head *first = list->next;
- struct list_head *last = list->prev;
- first->prev= prev;
- prev->next= first;
- last->next=next;
- next->prev= last;
- }
这个函数实现的结果是将list领头的这个链表合并到prev和next之间,不包括list这个结点。
- static inline void list_splice(const struct list_head*list,
- struct list_head *head)
- {
- if (!list_empty(list))
- __list_splice(list, head, head->next);
- }
将list所指链的内容加到head和head->next之间(类似于头插法)。
- static inline void list_splice_tail(struct list_head*list,
- struct list_head *head)
- {
- if (!list_empty(list))
- __list_splice(list, head->prev, head);
- }
将list所指链的内容加到head->prev和head(类似于尾插法),插入之后,head->prev将会是原来的list->prev,这点需要注意。
- static inline void list_splice_init(struct list_head*list,
- struct list_head *head)
- {
- if (!list_empty(list)){
- __list_splice(list, head, head->next);
- INIT_LIST_HEAD(list);
- }
- }
将list所指链的内容加到head和head->next之间(类似于头插法),完了之后,将list初始化为一个空链表。
- static inline void list_splice_tail_init(struct list_head*list,
- struct list_head *head)
- {
- if (!list_empty(list)){
- __list_splice(list, head->prev, head);
- INIT_LIST_HEAD(list);
- }
- }
将list所指链的内容加到head->prev和head(类似于尾插法),插入之后,head->prev将会是原来的list->prev,这点需要注意,完了之后,将list初始化为一个空链表。
(十一)链表的宏遍历
在开始链表的遍历之前,先看一个问题:通过一个结构体的成员变量如何访问其他结构体成员的变量。
我们先看一个例子吧:
有这个结构体
struct symbol_list {
int num ;
char value [STR_TOKEN ] ; / /STR_TOKEN为一个宏定义的一个整数
struct list_head list ;
} ;
int num ;
char value [STR_TOKEN ] ; / /STR_TOKEN为一个宏定义的一个整数
struct list_head list ;
} ;
我们的目标是通过for_each_symbol()函数得到这个结构体变量的首地址,这样,我们就能通过这个首地址访问这个结构体的其他成员变量了。
struct symbol_list *for_each_symbol(struct list_head*pos){
const typeof ( ( (struct symbol_list * )0 ) - >list ) *ptr = pos ;
int offset = ( int ) ( & ( (struct symbol_list * )0 ) - >list ) ;
struct symbol_list *p = (struct symbol_list * ) ( (char * )ptr - offset ) ;
return p ;
}
const typeof ( ( (struct symbol_list * )0 ) - >list ) *ptr = pos ;
int offset = ( int ) ( & ( (struct symbol_list * )0 ) - >list ) ;
struct symbol_list *p = (struct symbol_list * ) ( (char * )ptr - offset ) ;
return p ;
}
先看第一句const typeof(((struct symbol_list *)0)->list) *ptr = pos,其中 typeof(type)是gcc的扩展,是得到type的数据类型,和我们比较熟悉的sizeof()比较类似。这一句的执行结果是申请一个struct list_head类型的指针变量,并将pos这个变量赋值给ptr,至于为什么要赋值给ptr,这里是为了防止修改pos的值。
接着,我们看第二句,int offset = (int)(&((struct symbol_list *)0)->list),将0强制转化为struct symbol_list类型的指针,并且取出list变量的地址给offset,这一句是为了得到list所指向的变量相对于整个结构体变量的相对地址。
最后一句,struct symbol_list *p = (struct symbol_list *)((char *)ptr - offset),是将ptr的值与offset相对地址相减,这样就可以得到了这个结构体变量的首地址,这样我们就可以通过这个p来获取这个结构体其他成员变量的值了。这里需要注意一点,就是将ptr强制转化的时候不是转化成了(int *),而是转化成了(char *)。指针相减:在数组中的定义是说明两个元素之间的相隔元素为单位的距离。这里就是一些指针相减的知识,char指针+1是1字节地址偏移,int指针+1是4字节地址偏移。不相信的话,你自己可以
printf("%p", pointer)
看看。
下面我们还需要看一个东西才能正式进入内核链表的遍历。
container_of宏定义在include/linux/kernel.h中:
#define container_of(ptr, type, member)({ \
const typeof ( ( (type * )0 ) - >member ) *__mptr = (ptr ) ; \
(type * ) ( (char * )__mptr - offsetof (type ,member ) ) ; } )
const typeof ( ( (type * )0 ) - >member ) *__mptr = (ptr ) ; \
(type * ) ( (char * )__mptr - offsetof (type ,member ) ) ; } )
offsetof宏定义在include/linux/stddef.h中:
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
在container_of(ptr, type, member)中,ptr表示指向struct list_head成员变量的地址,type表示这个结构体的类型,member表示struct list_head在该结构体中的变量名称。
所以container_of(ptr, type, member)就等价于下面的东西:
const typeof(((type*)0)->member)*__mptr= (ptr);
(type * ) ( (char * )__mptr - ( (size_t ) & ( (type * )0 ) - >member ) ) ;
(type * ) ( (char * )__mptr - ( (size_t ) & ( (type * )0 ) - >member ) ) ;
再次注意一下,这里将__mptr强制转化成了(char *)类型进行了地址相减操作。
(1)这个宏好和container_of(ptr, type, member)没有什么区别:都是得到ptr所指地址的这个结构体的首地址
#define list_entry(ptr, type, member)\
container_of (ptr , type , member )
container_of (ptr , type , member )
(2)这里的ptr是一个链表的头节点,这个宏就是取得这个链表第一元素的所指结构体的首地址。
#define list_first_entry(ptr, type, member)\
list_entry ( (ptr ) - > next , type , member )
list_entry ( (ptr ) - > next , type , member )
(3)这个实际上就是一个for循环,从头到尾遍历链表。prefetch()用于预取以此提高效率。
#define list_for_each(pos, head)\
for (pos = (head ) - > next ; prefetch (pos - > next ) , pos ! = (head ) ; \
pos = pos - > next )
for (pos = (head ) - > next ; prefetch (pos - > next ) , pos ! = (head ) ; \
pos = pos - > next )
(4)这个实际上就是一个for循环,从头到尾遍历链表。和前一个不同的是,这个没有使用prefetch()函数来预取提高效率。
#define __list_for_each(pos, head)\
for (pos = (head ) - > next ; pos ! = (head ) ; pos = pos - > next )
for (pos = (head ) - > next ; pos ! = (head ) ; pos = pos - > next )
(5)这个实际上就是一个for循环,从尾到头遍历链表。prefetch()用于预取以此提高效率。
#define list_for_each_prev(pos, head)\
for (pos = (head ) - >prev ; prefetch (pos - >prev ) , pos ! = (head ) ; \
pos = pos - >prev )
for (pos = (head ) - >prev ; prefetch (pos - >prev ) , pos ! = (head ) ; \
pos = pos - >prev )
(6)这个实际上就是一个for循环,从头到尾遍历链表。这里使用了n来记录pos的下一个,这样处理完一个流程之后再赋给pos,避免了删除pos结点造成的问题,由它的英文注释我们可以看书,其实这个函数是专门为删除结点是准备的。
#define list_for_each_safe(pos, n, head)\
for (pos = (head ) - > next , n = pos - > next ; pos ! = (head ) ; \
pos = n , n = pos - > next )
for (pos = (head ) - > next , n = pos - > next ; pos ! = (head ) ; \
pos = n , n = pos - > next )
注:list_for_each(pos, head)和list_for_each_safe(pos, n, head)都是从头至尾遍历链表的,但是对于前者来说当操作中没有删除结点的时候使用,但是如果操作中有删除结点 的操作的时候就使用后者,对于后面代safe的一般都是这个目的。
(7)这个实际上就是一个for循环,从尾到头遍历链表。这里使用了n来记录pos的前一个,这样处理完一个流程之后再赋给pos,避免了删除pos结点造成的问题,由它的英文注释我们可以看书,其实这个函数是专门为删除结点是准备的。
#define list_for_each_prev_safe(pos, n, head)\
for (pos = (head ) - >prev , n = pos - >prev ; \
prefetch (pos - >prev ) , pos ! = (head ) ; \
pos = n , n = pos - >prev )
for (pos = (head ) - >prev , n = pos - >prev ; \
prefetch (pos - >prev ) , pos ! = (head ) ; \
pos = n , n = pos - >prev )
(8)第一个参数为传入的遍历指针,指向宿主数据结构,第二个参数为链表头,为list_head结构,第三个参数为list_head结构在宿主结构中的成员名。
list_entry((head)->next, typeof(*pos), member)用来得到head链表的第一个元素所在结构体的首地址。
这个函数是根据member成员遍历head链表,并且将每个结构体的首地址赋值给pos,这样的话,我们就可以在循环体里面通过pos来访问该结构体变量的其他成员了。而前面的list_for_each(pos, head)中的pos是list_head类型的。
#define list_for_each_entry(pos, head, member) \
for (pos = list_entry ( (head ) - > next , typeof ( *pos ) , member ) ; \
prefetch (pos - >member . next ) , &pos - >member ! = (head ) ; \
pos = list_entry (pos - >member . next , typeof ( *pos ) , member ) )
for (pos = list_entry ( (head ) - > next , typeof ( *pos ) , member ) ; \
prefetch (pos - >member . next ) , &pos - >member ! = (head ) ; \
pos = list_entry (pos - >member . next , typeof ( *pos ) , member ) )
(9)和第(8)个类似,只是遍历的顺序不一样,是从尾到头来遍历。
#define list_for_each_entry_reverse(pos, head, member) \
for (pos = list_entry ( (head ) - >prev , typeof ( *pos ) , member ) ; \
prefetch (pos - >member .prev ) , &pos - >member ! = (head ) ; \
pos = list_entry (pos - >member .prev , typeof ( *pos ) , member ) )
for (pos = list_entry ( (head ) - >prev , typeof ( *pos ) , member ) ; \
prefetch (pos - >member .prev ) , &pos - >member ! = (head ) ; \
pos = list_entry (pos - >member .prev , typeof ( *pos ) , member ) )
(10)pos表示结构体变量;head表示这个链表的开始节点,是list_head类型;member是list_head在结构体当中的变量的名字。
这个函数的功能就是如果pos非空,那么pos的值就为其本身,如果pos为空,那么就从链表头强制扩展一个虚pos指针,这个宏定义是为了在list_for_each_entry_continue()中使用做准备的。
#define list_prepare_entry(pos, head, member)\
( (pos ) ? : list_entry (head , typeof ( *pos ) , member ) )
( (pos ) ? : list_entry (head , typeof ( *pos ) , member ) )
(11)pos表示结构体变量;head表示这个链表的开始节点,是list_head类型;member是list_head在结构体当中的变量的名字。
这个函数是根据member成员遍历head链表,并且将每个结构体的首地址赋值给pos,这样的话,我们就可以在循环体里面通过pos来访问该结构体变量的其他成员了。而前面的list_for_each(pos, head)中的pos是list_head类型的。
这个函数得遍历可以不从链表的头开始遍历,可以从一个指定的pos节点遍历。
#define list_for_each_entry_continue(pos, head, member) \
for (pos = list_entry (pos - >member . next , typeof ( *pos ) , member ) ; \
prefetch (pos - >member . next ) , &pos - >member ! = (head ) ; \
pos = list_entry (pos - >member . next , typeof ( *pos ) , member ) )
for (pos = list_entry (pos - >member . next , typeof ( *pos ) , member ) ; \
prefetch (pos - >member . next ) , &pos - >member ! = (head ) ; \
pos = list_entry (pos - >member . next , typeof ( *pos ) , member ) )
(12)和(11)类似,不同的是遍历的顺序相反。
#define list_for_each_entry_continue_reverse(pos, head, member) \
for (pos = list_entry (pos - >member .prev , typeof ( *pos ) , member ) ; \
prefetch (pos - >member .prev ) , &pos - >member ! = (head ) ; \
pos = list_entry (pos - >member .prev , typeof ( *pos ) , member ) )
for (pos = list_entry (pos - >member .prev , typeof ( *pos ) , member ) ; \
prefetch (pos - >member .prev ) , &pos - >member ! = (head ) ; \
pos = list_entry (pos - >member .prev , typeof ( *pos ) , member ) )
(13)这个函数的遍历是从当前这个点开始遍历的。
#define list_for_each_entry_from(pos, head, member) \
for ( ; prefetch (pos - >member . next ) , &pos - >member ! = (head ) ; \
pos = list_entry (pos - >member . next , typeof ( *pos ) , member ) )
for ( ; prefetch (pos - >member . next ) , &pos - >member ! = (head ) ; \
pos = list_entry (pos - >member . next , typeof ( *pos ) , member ) )
(14)和list_for_each_entry的遍历类似,这个带了safe是为了防止删除节点而造成断链的发生。
#define list_for_each_entry_safe(pos, n, head, member) \
for (pos = list_entry ( (head ) - > next , typeof ( *pos ) , member ) , \
n = list_entry (pos - >member . next , typeof ( *pos ) , member ) ; \
&pos - >member ! = (head ) ; \
pos = n , n = list_entry (n - >member . next , typeof ( *n ) , member ) )
for (pos = list_entry ( (head ) - > next , typeof ( *pos ) , member ) , \
n = list_entry (pos - >member . next , typeof ( *pos ) , member ) ; \
&pos - >member ! = (head ) ; \
pos = n , n = list_entry (n - >member . next , typeof ( *n ) , member ) )
(15)和list_for_each_entry_continue()遍历类似,这个带了safe是为了防止删除节点而造成断链的发生。
#define list_for_each_entry_safe_continue(pos, n, head, member) \
for (pos = list_entry (pos - >member . next , typeof ( *pos ) , member ) , \
n = list_entry (pos - >member . next , typeof ( *pos ) , member ) ; \
&pos - >member ! = (head ) ; \
pos = n , n = list_entry (n - >member . next , typeof ( *n ) , member ) )
for (pos = list_entry (pos - >member . next , typeof ( *pos ) , member ) , \
n = list_entry (pos - >member . next , typeof ( *pos ) , member ) ; \
&pos - >member ! = (head ) ; \
pos = n , n = list_entry (n - >member . next , typeof ( *n ) , member ) )
(16)从当前的节点开始遍历。
#define list_for_each_entry_safe_from(pos, n, head, member) \
for (n = list_entry (pos - >member . next , typeof ( *pos ) , member ) ; \
&pos - >member ! = (head ) ; \
pos = n , n = list_entry (n - >member . next , typeof ( *n ) , member ) )
for (n = list_entry (pos - >member . next , typeof ( *pos ) , member ) ; \
&pos - >member ! = (head ) ; \
pos = n , n = list_entry (n - >member . next , typeof ( *n ) , member ) )
(17)和list_for_each_entry_safe类似,不过遍历的顺序刚好相反。
#define list_for_each_entry_safe_reverse(pos, n, head, member) \
for (pos = list_entry ( (head ) - >prev , typeof ( *pos ) , member ) , \
n = list_entry (pos - >member .prev , typeof ( *pos ) , member ) ; \
&pos - >member ! = (head ) ; \
pos = n , n = list_entry (n - >member .prev , typeof ( *n ) , member ) )
for (pos = list_entry ( (head ) - >prev , typeof ( *pos ) , member ) , \
n = list_entry (pos - >member .prev , typeof ( *pos ) , member ) ; \
&pos - >member ! = (head ) ; \
pos = n , n = list_entry (n - >member .prev , typeof ( *n ) , member ) )
(18)list_safe_reset_next is not safe to use in general if the list may be modified concurrently (eg. the lock is dropped in the loop body). An exception to this is if the cursor element (pos) is pinned in the list, and list_safe_reset_next is called after re-taking the lock and before completing the current iteration of the loop body.
#define list_safe_reset_next(pos, n, member) \
n = list_entry (pos - >member . next , typeof ( *pos ) , member )
n = list_entry (pos - >member . next , typeof ( *pos ) , member )