python网络爬虫— —构建一个基础的网络爬虫应用
本项目使用python的requests库和BeautifulSopu来进行网页内容的爬取,首先简单介绍这两个库,之后说明爬取网页内容的一般步骤,最后以爬取豆瓣读书top250中的前50本书为例说明实际的python爬虫应用应该怎么去构建。
1、requests库
requests 库是一个简洁且简单的处理HTTP请求的第三方库。
request 库支持非常丰富的链接访问功能,包括:国际域名和URL 获取、HTTP 长连接和连接缓存、HTTP 会话和Cookie 保持、浏览器使用风格的SSL 验证、基本的摘要认证、有效的键值对Cookie 记录、自动解压缩、自动内容解码、文件分块上传、HTTP(S)代理功能、连接超时处理、流数据下载等。
requests学习资料我推荐看官方文档快速上手部分,这将会让你快速了解request的使用方法。
其他资料:
廖雪峰python教程requests库
2. BeautifulSoup库
简单来说,Beautiful Soup是python的一个库,最主要的功能是解析网页从而抓取需要的数据。官方解释如下:Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
BeautifulSoup学习资料我只推荐看官方文档。
3. 爬虫一般步骤
在对requests和BeautifulSoup这两个库有初步的了解之后,你就可以通过一个或几个实战的小项目来加深对python爬虫的理解,但在这之前我想要先根据我的经验来说明一下我在实际的编写爬虫代码的过程中遵循的一些步骤。
3.1 爬取HTML页面通用步骤
def getHTMLText( url ):
"""
爬取HTML网页通用框架
:param url: 链接
:return: text
"""
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
text = r.content.decode('utf-8')
# text = r.text
return text
接着,我们逐行解析以上的代码。在使用requests的get()函数获取网页HTML之前,我们首先要构造一个请求头。因为我们要爬取的很多网站都有反爬虫的措施,如果我们简单地给get()函数一个url链接,那么大概率会被网站识别这个请求来源于爬虫。因此我们需要提前伪造一个请求头,让网站以为我们的请求是来源于浏览器,这样就可以避免被网站判断为是爬虫请求。
举个例子,假设现在我们要爬取豆瓣主页的内容,代码如下
url = "https://www.douban.com/"
headers = {'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}
r = requests.get(url, headers=headers) # 构造请求头
print(r.status_code)
print(r.encoding)
r_n = requests.get(url, headers=None) # 没有构造请求头
print(r_n.status_code)
print(r_n.encoding)
运行以上代码后我们将会得到以下结果
200
utf-8
418
None
我们可以看出,未构造请求头不能正常爬取网页内容。
其次,我们关注text = r.content.decode('utf-8')。通常情况下,r.text返回文本字符串,r.content返回二进制内容。但是,我们在获得HTML内容时用的却是r.content而不是r.text,这是因为我们在使用BeautifulSoup解析页面内容时,如果我们将r.text传入,则会导致乱码,相反的如果我们将r.content先转码为utf-8然后传入BeautifulSoup则可以避免乱码(经验之谈)。因此无论我们需要文本内容还是二进制图片等内容,一般我们都使用r.content。
3.2 使用BeautifulSoup解析HTML页面
def get_soup(url):
"""
使用bs4解析HTML页面
"""
text = getHTMLText(url)
soup = BeautifulSoup(text, 'lxml')
print(soup.prettify()) # 格式化打印HTML界面
return soup
使用BeautifulSoup解析HTML页面后会返回soup对象,接下来我们就要通过使用soup对象对应的方法来从HTML页面中找到我们需要的内容。
3.3 获取信息
在得到soup对象之后,我们就要开始解析HTML页面以此获得我们需要的信息。这部分我将以获取豆瓣读书top50的图书链接为例来说明如何通过解析HTML来获取我们所需的信息。
首先,我们通过搜索得到豆瓣读书TOP50链接有两个,每个页面包含25本图书的信息,我们要通过解析这两个HTML页面来获取50本图书的链接。
urls = ["https://book.douban.com/top250?start=0",
"https://book.douban.com/top250?start=25"]
其次我们将每个链接对应的HTML页面通过BeautifulSoup进行解析。得到一个soup对象
soup = get_soup(url)
通过使用浏览器开发者工具,我们可以找到图书链接对应的tag位置。我们可以看到对于每一本书的链接,我们可以通过逐步深入tag来找到,如 tr->td->a[‘href’]。由此,通过使用soup.find_all(‘tr’, class_=‘item’)函数便可以获取该HTML页面中所有图书对应的tag范围,然后逐步深入tag直到获得图书链接。代码如下

def get_books_link():
# 得到豆瓣读书TOP50链接
urls = ["https://book.douban.com/top250?start=0",
"https://book.douban.com/top250?start=25"] # 可添加页面链接获得更多图书链接
book_links = []
for url in urls:
soup = get_soup(url)
children = soup.find_all('tr', class_='item')
for child in children:
book_links.append(child.td.a.attrs['href'])
return book_links
3.4 总结
以上就是使用requests库和BeautifulSoup库进行网络爬虫(HTML信息获取)的一般步骤。下面脚本完整实现了爬取豆瓣读书top50书籍信息的代码:
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
def getHTMLText( url ):
"""
爬取HTML网页通用框架
:param url: 链接
:return: text
"""
headers = {'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
}
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
text = r.content.decode('utf-8')
# text = r.text
return text
def get_soup(url):
"""
使用bs4解析HTML页面
"""
text = getHTMLText(url)
soup = BeautifulSoup(text, 'lxml')
# print(soup.prettify())
#print(soup.original_encoding)
return soup
def get_books_link():
# 得到豆瓣读书TOP50链接
urls = ["https://book.douban.com/top250?start=0",
"https://book.douban.com/top250?start=25"] # 可添加页面链接获得更多图书链接
book_links = []
for url in urls:
soup = get_soup(url)
children = soup.find_all('tr', class_='item')
for child in children:
book_links.append(child.td.a.attrs['href'])
return book_links
def get_book_name(soup):
"""
得到书名
"""
children = soup.find_all('span', property="v:itemreviewed")
for child in children:
book_name = child.string # just once
return book_name
def get_publication_status(soup):
"""
得到图书出版情况
"""
def pares(s):
# 使用正则表达式匹配没有标签的文本
c = re.compile(r'(.*?):(.*?)
')
return (c.findall(s))
children = soup.find_all('div', id='info')
for child in children:
info = pares(str(child))
info_dit = {}
for i in range(len(info)):
if info[i][0] == "出版社":
info_dit['出版社'] = info[i][1].strip()
elif info[i][0] == "出版年":
info_dit['出版年'] = info[i][1].strip()
elif info[i][0] == "定价":
info_dit["定价"] = info[i][1].strip()
publication_status = child.a.string.replace(' ', '').replace('\n', '')+ '/' + info_dit['出版社'] + '/' + \
info_dit["出版年"] + '/' + info_dit["定价"]
return publication_status
def get_score(soup):
"""
得到评分
"""
children = soup.find_all('div', id="interest_sectl")
for child in children:
score = child.strong.string.replace(' ', '').replace('\n', '')
return score
def get_votes(soup):
"""
得到评分人数
"""
children = soup.find_all('div', id="interest_sectl")
for child in children:
votes = child.find_all('span', property="v:votes")[0].string.replace(' ', '').replace('\n', '')
return votes
def get_star_rate(soup, star_num):
"""
得到星比例
"""
children = soup.find_all('div', id="interest_sectl")
for child in children:
chileren2 = child.find_all('span', class_="rating_per")
votes = []
for child2 in chileren2:
vote = child2.string.replace(' ', '').replace('\n', '')
votes.append(vote)
return votes[int(star_num-1)]
if __name__ == '__main__':
columns = ["名称", "出版情况", "评价分数", "评价人数", "5星占比",
"4星占比", "3星占比", "2星占比", "1星占比"]
book_info = pd.DataFrame(columns=columns)
book_links = get_books_link()
for link in book_links:
soup = get_soup(link)
data = []
data.append(get_book_name(soup))
data.append(get_publication_status(soup))
data.append(get_score(soup))
data.append(get_votes(soup))
for i in range(5):
data.append(get_star_rate(soup, i+1))
print(len(data))
book_info.loc[len(book_info)] = data
book_info.to_excel('./豆瓣读书Top50.xls',sheet_name='豆瓣读书Top50', index=False)
print(book_info)
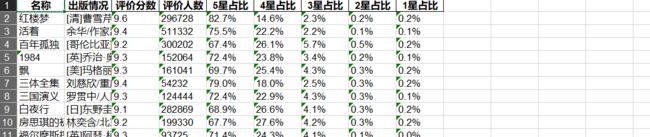
运行结果如下: