ssd(Single Shot MultiBox Detector)代码之(五) 训练自己的数据集
原始代码来源:https://github.com/amdegroot/ssd.pytorch
我修改后的代码:https://github.com/Andy-zhujunwen/ssd-use-your-own-dataset-
实验气球数据集:https://pan.baidu.com/s/13DxzPZD1MhL_1KrKq55rfw&shfl=sharepset
提取码:cas8
一,代码结构了解
我们要改代码首先要了解代码的结构:

要训练自己的数据集,我们先了解一下代码中一些代码文件/目录的作用:
1. data目录
(以跑VOC数据集为例)data目录顾名思义就是掌控代码的数据集的地方,下图中我们看到有VOCdevkit文件目录,这就是voc数据集的数据图片和label 存放的目录。其次还一些文件例如有coco.py,voc0712.py ,这些都是数据集的读取脚本代码,例如voc0712.py就是读取数据集目录VOCdevkit中的图片和label的脚本代码。因此,我们若要训练自己的代码的话:
1.要把自己数据集放到data目录中
2.要写一个读取你自己数据集图片和label的脚本文件

2. data/voc0712.py
因为我们讲解是以跑VOC数据集为例讲解的,所以这里举例就举 voc0712.py。若你跑的是coco数据集,则这里就应该是coco.py。
3. data/config.py
在目录 data下有个config.py文件(/data/config.py),里面记录着这份代码可以跑的数据集,及一些参数:
可以看到有VOC和COCO的字典,这份代码默认是可以跑VOC和COCO数据集的,若是我们需要跑自己的数据集,则需要在这里加上自己数据集的字典:(关于怎么改,后面会说)
# config.py
import os.path
# gets home dir cross platform
HOME = os.path.expanduser("/home/home_data/zjw/ssd.pytorch/")
# for making bounding boxes pretty
COLORS = ((255, 0, 0, 128), (0, 255, 0, 128), (0, 0, 255, 128),
(0, 255, 255, 128), (255, 0, 255, 128), (255, 255, 0, 128))
MEANS = (104, 117, 123)
# SSD300 CONFIGS
voc = {
'num_classes': 21,
'lr_steps': (80000, 100000, 120000),
'max_iter': 120000,
'feature_maps': [38, 19, 10, 5, 3, 1],
'min_dim': 300,
'steps': [8, 16, 32, 64, 100, 300], # 特征图相对于原图边长缩小的多少倍
'min_sizes': [30, 60, 111, 162, 213, 264],
'max_sizes': [60, 111, 162, 213, 264, 315], # 这个可能是500作为输入的
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'variance': [0.1, 0.2],
'clip': True,
'name': 'VOC',
}
coco = {
'num_classes': 201,
'lr_steps': (280000, 360000, 400000),
'max_iter': 400000,
'feature_maps': [38, 19, 10, 5, 3, 1],
'min_dim': 300,
'steps': [8, 16, 32, 64, 100, 300],
'min_sizes': [21, 45, 99, 153, 207, 261],
'max_sizes': [45, 99, 153, 207, 261, 315],
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'variance': [0.1, 0.2],
'clip': True,
'name': 'COCO',
}
二,实验数据集---气球数据集
实验气球数据集:https://pan.baidu.com/s/13DxzPZD1MhL_1KrKq55rfw&shfl=sharepset
提取码:cas8
这个数据集里面有几十张气球的图片:

我们为了最简单地达到我们训练自己数据集的目的,决定仿照coco.py或者voc0712.py来写我们的气球读取脚本balloon.py。我们以VOC为例,那既然要以voc0712.py的格式写balloon.py,那么我们的数据集结构也要按照VOC数据集的结构存放。
1.voc数据集
在voc数据集的目标检测数据中,一般以下图的形式存放数据:

Annotations:是存放图片的标注的,以xml文件的格式记录。

ImageSets:是以txt文件的形式记录训练集图片的名字和测试集图片的名字的。借此把数据分成训练集和数据集
ImageSets目录下我们只需要仿照Main目录就行了,因为其余与目标检测无关:

而Main目录记录的是数据集不同类别的图片的名字,且把他们分成训练集,测试集等:

JPEGImages:就是存放图片的目录

2.我们的气球数据集
我们把气球的图片用打标签软件(如labelimg)打好标签后,就要按照VOC的数据集的目录格式存放:

三,自己的数据集读取脚本文件balloon.py
之前已经说过,例如要读取VOC数据集,就要有VOC数据集的数据读取脚本文件(voc0712.py)。我们为了节省工作量,我们的气球数据集balloon的数据读取文件balloon.py也按照着voc0712.py的格式改就好了。其实大多数地方都不用改的。我们来看看voc0712.py:(一部分一部分看)

上图第一个红框表示的是数据集的类别数,例如voc就有20类,那我们气球数据集因为只有一个类别,所以就改成balloon就好了。而第二个红框则是表示数据集的存放路径。那么仿照voc0712.py的格式,balloon.py就是如下:
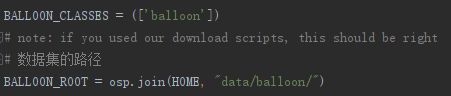
注意:当类别只有一个时,要加一个中括号。
接着就到VOCAnnotationTransform类,这个作用只是是读入Annotations里的标注并做一些处理。所以这个基本上不用改,就改个名字就行了,如果嫌麻烦的话,甚至都不用改。
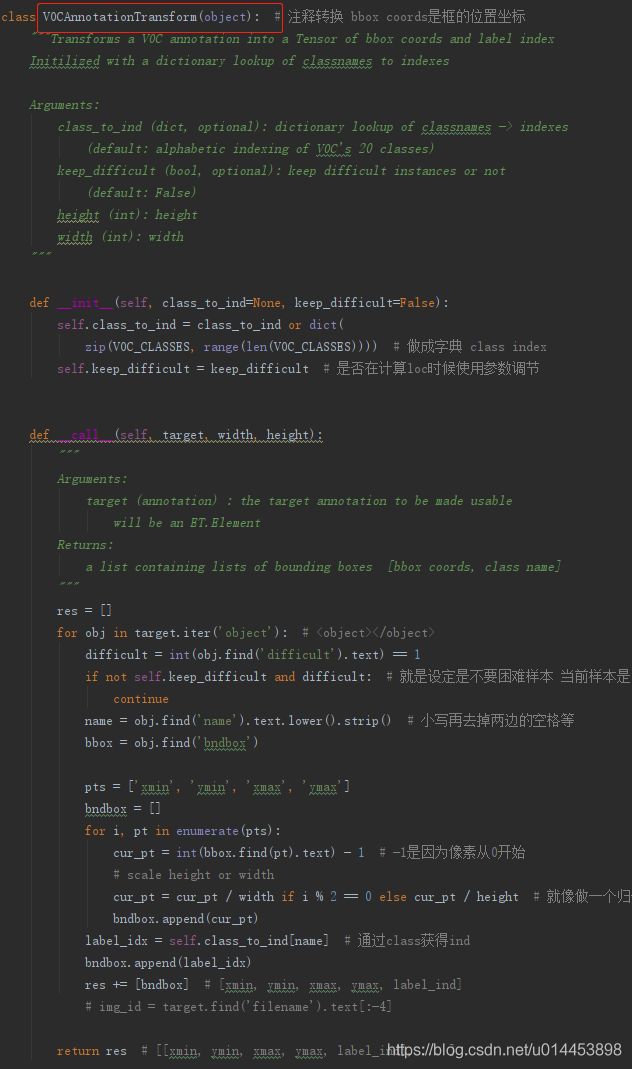
接着到VOCDetection类,这个类的作用是读取图片和图片的信息

红色框的地方都要改的,改的目的是为了读取balloon数据集的图片和图片信息。
改完之后:

到这里就得到一个与coco.py,voc0712.py平起平坐的balloon数据读取脚本balloon.py啦。把balloon.py放在 data目录下就完成这部分工作,还有不要忘记也把balloon数据集放到data目录下噢:

四,修改 /data下的config.py
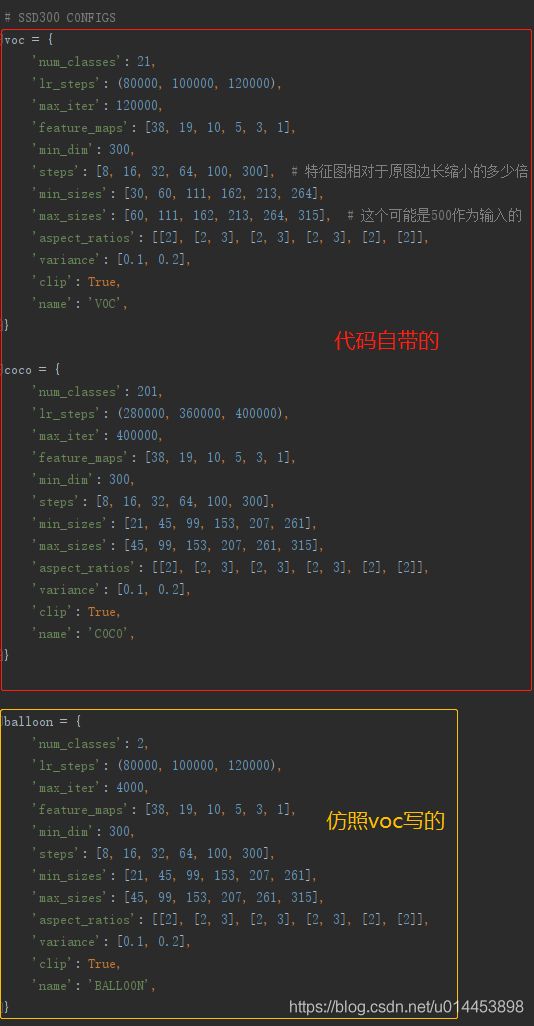
在config.py中已经有两个数据集(coco,voc)的配置字典存在,我们只要模仿着写就好了,当然我们还是以仿造VOC数据集为例,首先直接把voc的复制一遍,把num_classes改了就行,注意这里的num_classes是包含背景的,所以是你数据集的类别数加一。而max_iter则是你想训练的迭代次数,修改如下:
五,最后就差稍微改一下train.py训练脚本文件就可以训练啦
第一个地方:train.py就有一大堆参数设置的语句,里面只有voc和coco的,把balloon加上去即可

第二个地方:位于train()方法
把默认的voc改成balloon,VOCDetection改成BALLOONDetection(在balloon.py定义)

最后就可以开始训练了。
六,检测效果:
最后在demo目录下,有个p.py文件,用来检测的,在p.py里面设置好模型路径和需要输入的图片路径即可。
输入:

输出:
