泰坦尼克号获救问题分析和预测-Python项目实战记录
本文是作者(含笑半步癫)在学习Python网课时,将项目实战“泰坦尼克号获救问题分析”进行总结如下(含部分代码):
题目描述
数据来源:Kaggle数据集 → 共有1309名乘客数据,其中891是已知存活情况(train.csv),剩下418则是需要进行分析预测的(test.csv)
字段意义:
PassengerId: 乘客编号
Survived :存活情况(存活:1 ; 死亡:0)
Pclass : 客舱等级
Name : 乘客姓名
Sex : 性别
Age : 年龄
SibSp : 同乘的兄弟姐妹/配偶数
Parch : 同乘的父母/小孩数
Ticket : 船票编号
Fare : 船票价格
Cabin :客舱号
Embarked : 登船港口
目的:通过已知获救数据,预测乘客生存情况
研究问题1
1、整体来看,存活比例如何?
1.1 分析思路:查看数据集,Survived为存活情况(存活:1 ; 死亡:0)。通过seaborn绘制一个饼图,Survived=1的数据占比即为存活比例。
1.2 相关代码块:
# 读取数据(训练数据train.csv;预测数据test.csv)
os.chdir('D:\\学习\\数据分析\\网易课堂\\CLASSDATA_ch06数据分析项目实战\\练习09_泰坦尼克号获救问题\\')
train_data=pd.read_csv('train.csv')
test_data=pd.read_csv('test.csv')
# 清洗数据:缺失值处理(存活情况Survived字段)
train_data_survived=train_data[train_data['Survived'].notnull()]
# 用seaborn绘制饼图,分析已知存活数据中的存活比例
sns.set_style('ticks') # 十字叉
plt.axis('equal') #行宽相同
train_data_survived['Survived'].value_counts().plot.pie(autopct='%1.2f%%')
1.3 数据展现

1.4 分析总结
已知训练数据中,存活比例为38.38%
研究问题2
2、结合性别和年龄数据,分析幸存下来的人是哪些人?
2.1 分析思路:
(1)首先查看年龄数据分布情况;
(2) 然后分析男性和女性存活情况(比如猜测由于文化原因,可能女性存活率更高;
(3) 分析不同年龄段人的存活情况(比如猜测老人和小孩,可能存活率更高一些)
2.2 相关代码块
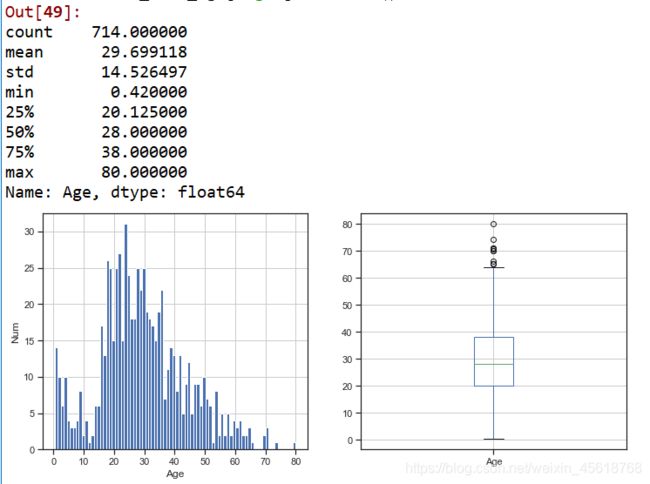
(1)首先查看年龄数据分布情况(根据可视化图表推荐,进行”分布“分析,选择直方图/箱型图进行展示;也可使用describe()函数查看数据统计分布情况:
sns.set()
sns.set_style('ticks')
# 缺失值处理:年龄Age字段
train_data_age=train_data[train_data['Age'].notnull()]
# 年龄数据的分布情况
plt.figure(figsize=(12,5))
plt.subplot(121)
train_data_age['Age'].hist(bins=80)
plt.xlabel('Age')
plt.ylabel('Num')
plt.subplot(122)
train_data_age.boxplot(column='Age',
showfliers=True) # 是否显示异常值
train_data_age['Age'].describe()
(2)分析男性和女性存活情况(把”性别“分类groupby计算出男女各自的的存活占比)
# 男性和女性存活情况
train_data[['Sex','Survived']].groupby('Sex').mean().plot.bar()
survive_sex=train_data.groupby(['Sex','Survived'])['Survived'].count()
print('女性存活率%.2f%%,男性存活率%.2f%%' %
(survive_sex.loc['female',1]/survive_sex.loc['female'].sum()*100,
survive_sex.loc['male',1]/survive_sex.loc['male'].sum()*100)
)
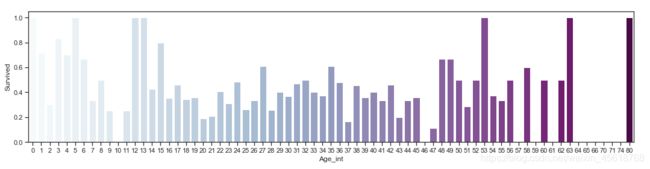
(3)分析不同年龄段人的存活情况
# 年龄与存活关系
fig,ax=plt.subplots(1,2,figsize=(18,8))
sns.violinplot('Pclass','Age',hue='Survived',data=train_data_age,split=True,ax=ax[0])
ax[0].set_title('Pclass and Age vs Survived')
sns.violinplot('Sex','Age',hue='Survived',data=train_data_age,split=True,ax=ax[1])
ax[1].set_title('Sex and Age vs Survived')
# 老人和小孩存活率
plt.figure(figsize=(18,4))
# 年龄都转换成整数
train_data_age['Age_int']=train_data_age['Age'].astype(np.int)
average_age=train_data_age[['Age_int','Survived']].groupby('Age_int',as_index=False).mean()
sns.barplot(x='Age_int',y='Survived',data=average_age,palette='BuPu')
plt.grid(linestyele='--',alpha=0.5)
2.3 数据展现
(1)查看年龄数据分布情况:
(2)分析男性和女性存活情况

(3)分析不同年龄段人的存活情况(考虑到船舱等级/性别与年龄会有相关性,也可能会影响年龄和存活情况的相关性)

2.4 分析总结
结论(1):
总体年龄分布:去掉缺失值后样本有714,平均年龄约为30岁,标准差14岁,最小年龄0.42,最大年龄80;主要分布在20-40岁,且均有较多低龄乘客。
结论(2):
女性存活率74.20%,男性存活率18.89%
结论(3):
按照不同船舱等级划分 -> 船舱等级越高,存活者年龄越大,船舱等级1存活年龄集中在20-40岁,船舱等级2/3中有较多低龄乘客存活。
按照性别划分 -> 男性女性存活者年龄主要分布在20-40岁,且均有较多低龄乘客,其中女性存活更多 。
灾难中,老人和小孩存活率较高。
研究问题3
3、结合 SibSp、Parch字段,研究亲人多少与存活的关系
要求:
(1)有无兄弟姐妹/父母子女和存活与否的关系
(2)亲戚多少与存活与否的关系
3.1 相关代码块
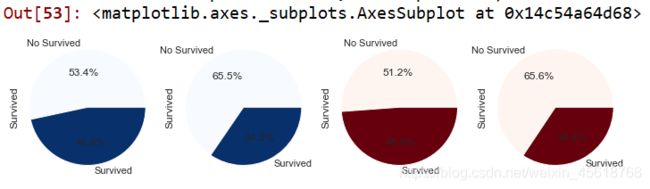
(1)有无兄弟姐妹/父母子女和存活与否的关系
# 筛选出有无兄弟姐妹
sibsp_df=train_data[train_data['SibSp']!=0] # 有兄弟姐妹
no_sibsp_df=train_data[train_data['SibSp']==0] # 没有兄弟姐妹
# 筛选出有无父母子女
parch_df=train_data[train_data['Parch']!=0] # 有父母子女子女
no_parch_df=train_data[train_data['Parch']==0] # 没有父母
plt.figure(figsize=(12,3))
plt.subplot(141)
plt.axis('equal')
sibsp_df['Survived'].value_counts().plot.pie(labels=['No Survived','Survived'],
autopct='%1.1f%%',colormap='Blues')
plt.subplot(142)
plt.axis('equal')
no_sibsp_df['Survived'].value_counts().plot.pie(labels=['No Survived','Survived'],
autopct='%1.1f%%',colormap='Blues')
plt.subplot(143)
plt.axis('equal')
parch_df['Survived'].value_counts().plot.pie(labels=['No Survived','Survived'],
autopct='%1.1f%%',colormap='Reds')
plt.subplot(144)
plt.axis('equal')
no_parch_df['Survived'].value_counts().plot.pie(labels=['No Survived','Survived'],
autopct='%1.1f%%',colormap='Reds')
(2) 亲戚多少与存活与否的关系
# 亲戚多少与是否存活有关吗?
fig,ax=plt.subplots(1,2,figsize=(15,4))
train_data[['Parch','Survived']].groupby('Parch').mean().plot.bar(ax=ax[0])
train_data[['SibSp','Survived']].groupby('SibSp').mean().plot.bar(ax=ax[1])
train_data['family_size']=train_data['Parch']+train_data['SibSp']+1
train_data[['family_size','Survived']].groupby('family_size').mean().plot.bar(figsize=(15,4))
3.3 数据展现
(1)有无兄弟姐妹/父母子女和存活与否的关系
(2) 亲戚多少与存活与否的关系
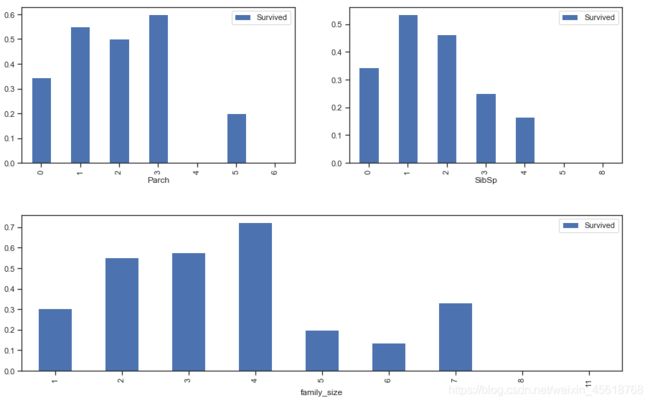
3.4 分析总结
结论(1):有兄弟姐妹、父母子女的乘客存活率更大
结论(2):若独自一人,那么其存活率比较低,但是如果亲友太多的话,存活率也会很低
研究问题4
4、结合票的费用情况,研究票价和存活与否的关系
4.2 相关代码块
fig,ax=plt.subplots(1,2,figsize=(15,4))
train_data['Fare'].hist(bins=70,ax=ax[0])
train_data.boxplot(column='Fare',by='Pclass',showfliers=False,ax=ax[1])
fare_not_survived=train_data['Fare'][train_data['Survived']==0]
fare_survived=train_data['Fare'][train_data['Survived']==1]
# 筛选数据
average_fare=pd.DataFrame([fare_not_survived.mean(),fare_survived.mean()])
std_fare=pd.DataFrame([fare_not_survived.std(),fare_survived.std()])
average_fare.plot(yerr=std_fare,kind='bar',figsize=(15,4),grid=True)
4.3 数据展现
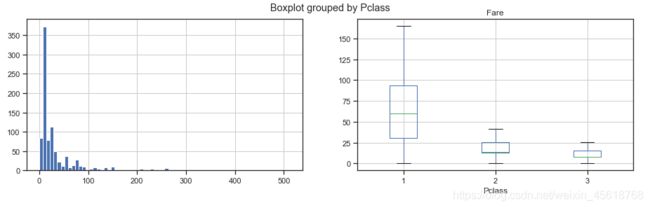
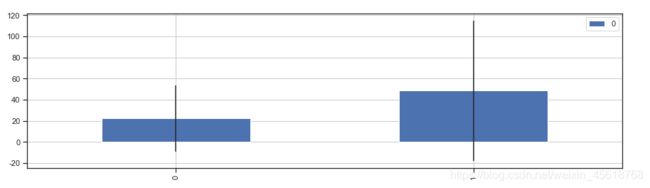
4.4 分析总结
结论:生还者的平均票价要大于未生还者的平均票价
研究问题5
5、利用KNN分类模型,对结果进行预测。
要求:
① 模型训练字段:‘Survived’,‘Pclass’,‘Sex’,‘Age’,‘Fare’,‘Family_Size’
② 模型预测test.csv样本数据的生还率
5.1 分析思路:
5.2 相关代码块
# 模型训练数据(过滤缺失数据)
# 性别改为数字表示(1代表男性,0代表女性)
knn_train=train_data[['Survived','Pclass','Sex','Age','Fare','family_size']].dropna()
knn_train['Sex'][knn_train['Sex']=='male']=1
knn_train['Sex'][knn_train['Sex']=='female']=0
# 测试数据(总家庭人数)
test_data['family_size']=test_data['Parch']+test_data['SibSp']+1
# 测试预测数据(过滤缺失数据,没有Survived字段)
# 性别改为数字表示(1代表男性,0代表女性)
knn_test=test_data[['Pclass','Sex','Age','Fare','family_size']].dropna()
knn_test['Sex'][knn_test['Sex']=='male']=1
knn_test['Sex'][knn_test['Sex']=='female']=0
通过已知训练数据的KNN模型,对test数据的生还情况进行预测
from sklearn import neighbors
# 导入knn分类模块
knn=neighbors.KNeighborsClassifier()
# 取得knn分类器
knn.fit(knn_train[['Pclass','Sex','Age','Fare','family_size']],knn_train['Survived'])
# 建立分类模型
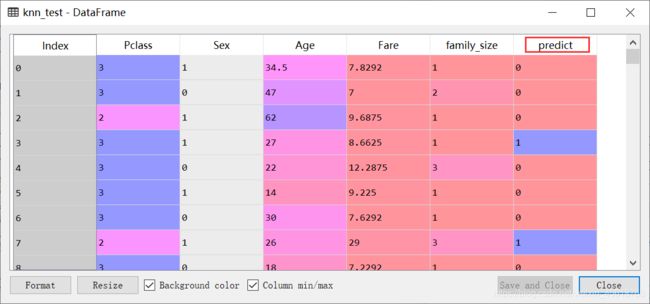
knn_test['predict']=knn.predict(knn_test)
# 预测结果
# 将原来的索引index作为新的一列
pre_survived=knn_test[knn_test['predict']==1].reset_index()
# 去掉原索引
del pre_survived['index']
5.3 数据展现