先看效果展示(仅作学习使用,非商业)
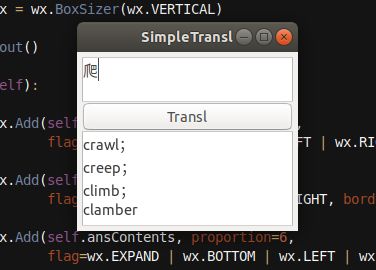
效果图是采用的 爱词霸 翻译,百度翻译 也实现了,只不过被注释了。
学计算机很多时候碰到生词,每次打开手机/浏览器翻译总觉得很麻烦,就想着自己写一个软件,自己去实现字典又太麻烦了,就想借着网上的翻译网站,做个爬虫。于是就学了下python,开始了爬虫之旅。
代码开始部分:
1 # -*- encoding: utf-8 -*- 2 3 import wx 4 import requests 5 import re 6 import bs4 7 import json 8 import time 9 from requests import Session 10 11 # 界面与逻辑分离
本着面向对象的编程思想,就把 界面实现,和 逻辑部分给分开了
定义了两个类,一个处理 爬虫请求(Handler),一个处理界面部分(Window)
接下来是 Handler 类:
1 class Handler(): 2 def __init__(self): 3 4 # self.armUrl = r'https://fanyi.baidu.com/transapi' 5 6 # 爱词霸 7 self.mainUrl = r'http://www.iciba.com/' 8 # 爱词霸 9 self.armUrl = "" 10 11 self.headers = { 12 'User-Agent': 13 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:61.0) Gecko/20100101 Firefox/61.0', 14 } 15 16 # self.data = { 17 # 'transtype': 'ente' 18 # } 19 20 self.session = Session() 21 22 # self.__initial() 23 # 24 # def __initial(self): 25 # 26 # r = requests.get(url = self.mainUrl, headers = self.headers) 27 # self.session.cookies = r.cookies 28 29 30 # def setData(self, dict): 31 # self.data.update(dict) 32 33 # 爱词霸 34 def mendUrl(self, query): 35 self.armUrl = self.mainUrl + query 36 37 38 39 def requestText(self): 40 r = self.session.get(url = self.armUrl) 41 42 soup = bs4.BeautifulSoup(r.content, 'lxml') 43 44 try: 45 p = soup.find_all('p')[0] 46 47 ans = "" 48 for span in p.find_all('span'): 49 ans += span.string + '\n' 50 51 return ans 52 53 except: 54 return "you fuck it up !!!" 55 56 57 @property 58 def text(self): 59 return self.requestText()
Window 类部分:
1 class Window(): 2 def __init__(self, handler): 3 self.win = wx.Frame(None, title = 'SimpleTransl', size = (200, 150)) 4 self.bkg = wx.Panel(self.win) 5 self.handler = handler 6 7 self.translBtn = wx.Button(self.bkg, label = 'Transl') 8 self.waitContents = wx.TextCtrl(self.bkg, style = wx.TE_MULTILINE) 9 self.ansContents = wx.TextCtrl(self.bkg, style = wx.TE_MULTILINE) 10 11 self.vbox = wx.BoxSizer(wx.VERTICAL) 12 13 self.layout() 14 15 def layout(self): 16 17 self.vbox.Add(self.waitContents, proportion=3, 18 flag=wx.EXPAND | wx.TOP | wx.LEFT | wx.RIGHT, border=5) 19 20 self.vbox.Add(self.translBtn, proportion=1, 21 flag=wx.EXPAND | wx.LEFT | wx.RIGHT, border=5) 22 23 self.vbox.Add(self.ansContents, proportion=6, 24 flag=wx.EXPAND | wx.BOTTOM | wx.LEFT | wx.RIGHT, border=5) 25 26 self.translBtn.Bind(wx.EVT_BUTTON, self.transl) 27 28 self.bkg.SetSizer(self.vbox) 29 30 31 def transl(self, event): 32 # f, t = self.checkLang() 33 # 34 # data = { 35 # 'from' : f, 36 # 'to' : t, 37 # 'query' : self.waitContents.GetValue() 38 # } 39 40 # self.handler.setData(dict = data) 41 42 # 爱词霸 43 self.handler.mendUrl(self.waitContents.GetValue()) 44 45 self.ansContents.SetValue(self.handler.text) 46 47 48 # def checkLang(self): 49 # 50 # txt = self.waitContents.GetValue() 51 # 52 # if not txt: 53 # return ('error', 'error') 54 # 55 # else: 56 # if 'a' <= txt[0] <= 'z' or 'A' <= txt[0] <= 'Z': 57 # return ('en', 'zh') 58 # 59 # else: 60 # return ('zh', 'en') 61 # 62 63 64 def show(self): 65 66 self.win.Show()
以上注释的部分是 百度翻译实现,取消注释,并且把 有 ‘爱词霸’ 标注部分注释就可以使用百度翻译实现了(但,requestsText 函数 提取信息要自己实现)
Window 类就是实现界面,定义了一个Button,两个 TextCrtl,并且给 翻译按钮绑定了一个事件,用于翻译。通过 构造函数,和 layout 函数 实现。
下面是 主函数:
1 if __name__ == '__main__': 2 3 app = wx.App() 4 5 handler = Handler() 6 7 window = Window(handler = handler) 8 9 window.show() 10 11 app.MainLoop()
PS.功能比较简单,后期可以拓展,比如 读音,界面美化等。。
这里用爱词霸展示是有原因的, 在百度翻译里,只能提取出一个非常简单的意思,没办法提供丰富的翻译(有那位小伙伴解决了这个问题,可以告诉我)
比如 :下面是 百度翻译 返回的信息

你可以获取 data 下的 { src :爬 }
但却获取不了 { word_means [... ] } 里面的更加详细、有用的信息。
解决了这个问题的小伙伴麻烦告知下(我再去补一下 web 的知识看看能不能解决)。