(Python)KMP算法匹配字符串
1 简介
全称Knuth-Morris-Pratt算法,在计算机科学中,Knuth-Morris-Pratt字符串查找算法(简称为KMP算法)可在一个主文本字符串内查找一个词的出现位置。此算法通过运用对这个词在不匹配时本身就包含足够的信息来确定下一个匹配将在哪里开始的发现,从而避免重新检查先前匹配的字符。
这个算法是由高德纳和沃恩·普拉特在1974年构思,同年詹姆斯·H·莫里斯也独立地设计出该算法,最终由三人于1977年联合发表。
2 部分匹配表的产生
首先,要了解两个概念:"前缀"和"后缀"。
"前缀":指除了最后一个字符以外,一个字符串的全部头部组合;
"后缀":指除了第一个字符以外,一个字符串的全部尾部组合。
"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以"ABCDABD"为例:
于是我们得到下面的表:
W[i] |
A | B | C | D | A | B | D |
|---|---|---|---|---|---|---|---|
T[i] |
0 | 0 | 0 | 0 | 0 | 1 | 2 |
3 查找算法实例
让我们用一个实例来演示这个算法。

首先,字符串"BBC ABCDAB ABCDABCDABDE"的第一个字符与搜索词"ABCDABD"的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。

因为B与A不匹配,搜索词再往后移。

就这样,直到字符串有一个字符,与搜索词的第一个字符相同为止。匹配到A之后继续进行后续匹配。

接着比较字符串和搜索词的下一个字符,还是相同。

直到字符串有一个字符,与搜索词对应的字符不相同为止。‘ ’ ‘D’
‘D’

如果直接后移一位继续比较确实可行,但这就是暴力匹配的步骤,就没意思了。这个时候第二步中计算的部分匹配表就可以拿过来用了。
| A | B | C | D | A | B | D |
| 0 | 0 | 0 | 0 | 0 | 1 | 2 |
当空格与D不匹配时,你其实知道前面六个字符是"ABCDAB"。KMP算法的想法是,设法利用这个已知信息,不要把"搜索位置"移回已经比较过的位置,继续把它向后移,这样就提高了效率。而这个时候向后移动的就不是一位了,而是 已经匹配的字符串"ABCDAB"长度6 - 表格中D对应的部分匹配值 2 = 4。所以这个时候向后移动四位。
移动位数 = 已匹配的字符数 - 对应的部分匹配值

因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2("AB"),对应的"部分匹配值"为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移2位。
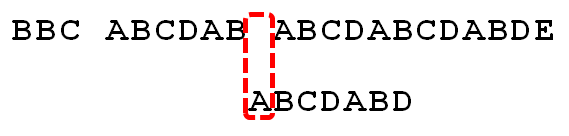
因为空格与A不匹配,继续后移一位。

逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位。

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动7位,这里就不再重复了。
得到在主串中的匹配结果为15 (从0开始数到那个完全匹配的开头的A)
4 代码实现
def strStr(haystack: str, needle: str) -> int:
def get_next(p):
""" 构造子串needle的匹配表, 以 "ABCDABD" 为例
i i i i i i i
ABCDABD ABCDABD ABCDABD ABCDABD ABCDABD ABCDABD ABCDABD
ABCDABD ABCDABD ABCDABD ABCDABD ABCDABD ABCDABD ABCDABD
j j j j j j j
"""
_next = [0] * (len(p) + 1) # A B C D A B D
_next[0] = -1 # [-1, 0, 0, 0, 0, 1, 2, 0]
i, j = 0, -1
while (i < len(p)):
if (j == -1 or p[i] == p[j]):
i += 1
j += 1
_next[i] = j
else:
j = _next[j]
return _next
def kmp(s, p, _next):
"""kmp O(m+n). s以 "BBC ABCDAB ABCDABCDABDE" 为例"""
i, j = 0, 0
while (i < len(s) and j < len(p)):
if (j == -1 or s[i] == p[j]):
i += 1
j += 1
else:
j = _next[j]
if j == len(p):
return i - j
else:
return -1
return kmp(haystack, needle, get_next(needle))
if __name__ == '__main__':
result = strStr(haystack="BBC ABCDAB ABCDABCDABDE", needle="ABCDABD")
print(result)
C:\ProgramData\Anaconda3\python.exe C:/Users/Ryan/Desktop/Python/kmp.py
15
参考:
http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
https://zh.wikipedia.org/wiki/%E5%85%8B%E5%8A%AA%E6%96%AF-%E8%8E%AB%E9%87%8C%E6%96%AF-%E6%99%AE%E6%8B%89%E7%89%B9%E7%AE%97%E6%B3%95
https://leetcode-cn.com/problems/implement-strstr/solution/kmp-suan-fa-xiang-jie-by-labuladong/
http://jakeboxer.com/blog/2009/12/13/the-knuth-morris-pratt-algorithm-in-my-own-words/
https://leetcode-cn.com/problems/implement-strstr/solution/shi-xian-strstr-by-leetcode/