漫画:什么是计数排序?




计数排序
计数排序(Counting Sort)是一种针对于特定范围之间的整数进行排序的算法。它通过统计给定数组中不同元素的数量(类似于哈希映射),然后对映射后的数组进行排序输出即可。


我们以数组 [1,4,1,2,5,2,4,1,8] 为例进行说明。

第一步:建立一个初始化为 0 ,长度为 9 (原始数组中的最大值 8 加 1) 的数组 count[] :
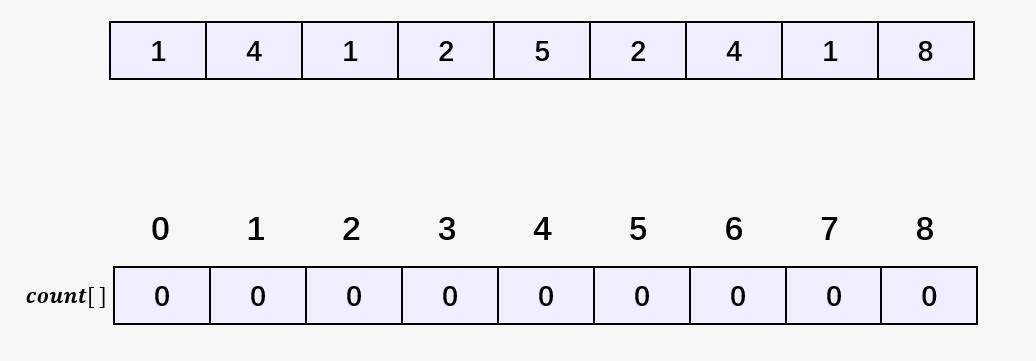
第二步:遍历数组 [1,4,1,2,5,2,4,1,8] ,访问第一个元素 1 ,然后将数组 count[] 中下标为 1 的元素加 1,表示当前 1 出现了一次,即 count[1] = 1 ;
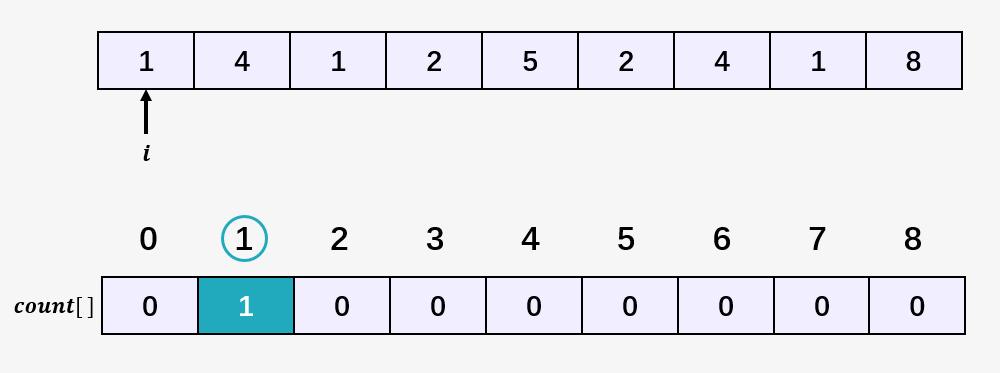
第三步:访问数组 [1,4,1,2,5,2,4,1,8] 的第二个元素 4 ,然后将数组 count[] 中下标为 4 的元素加 1 ,表示当前访问的元素 4 当前出现了 1 次,即 count[4] = 1 ;
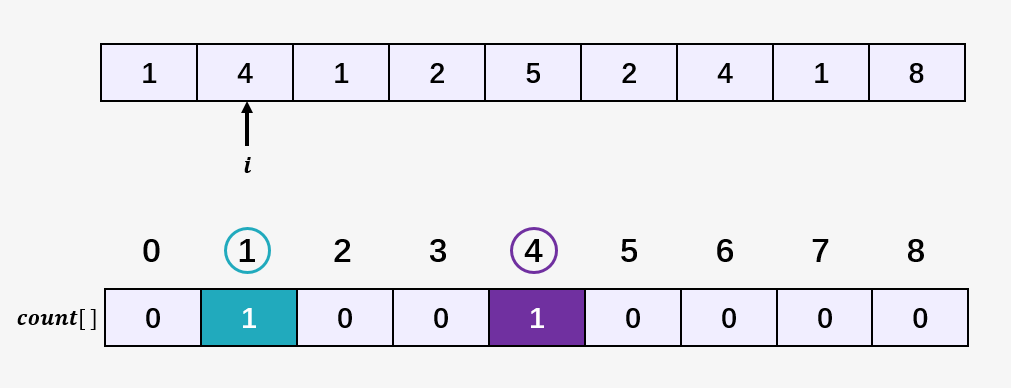
第四步:访问数组 [1,4,1,2,5,2,4,1,8] 的第三个元素 1 ,然后将数组 count[] 中下标为 1 的元素加 1,即 count[1] = 2 ,表示当前 1 出现了 2 次:

第五步:访问数组 [1,4,1,2,5,2,4,1,8] 的第四个元素 2 ,然后将数组 count[] 中下标为 2 的元素加 1,即 count[2] = 1 ,表示当前 2 出现了 1 次:

第六步:访问数组 [1,4,1,2,5,2,4,1,8] 的第五个元素 5 ,然后将数组 count[] 中下标为 5 的元素加 1,即 count[5] = 1 ,表示当前 5 出现了 1 次:

第七步:访问数组 [1,4,1,2,5,2,4,1,8] 的第六个元素 2 ,然后将数组 count[] 中下标为 2 的元素加 1,即 count[2] = 2 ,表示当前 2 出现了 2 次:
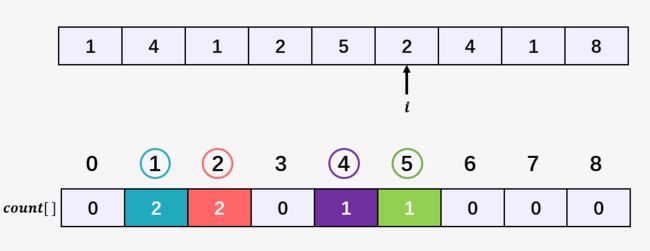
第八步:访问数组 [1,4,1,2,5,2,4,1,8] 的第七个元素 4 ,然后将数组 count[] 中下标为 4 的元素加 1,即 count[4] = 2 ,表示当前 4 出现了 2 次:
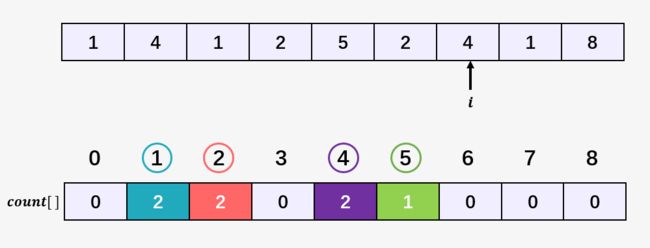
第九步:访问数组 [1,4,1,2,5,2,4,1,8] 的第八个元素 1 ,然后将数组 count[] 中下标为 1 的元素加 1,即 count[1] = 3 ,表示当前 1 出现了 3 次:

第十步:访问数组 [1,4,1,2,5,2,4,1,8] 的第九个元素 8 ,然后将数组 count[] 中下标为 8 的元素加 1,即 count[8] = 1 ,表示当前 8 出现了 1 次:
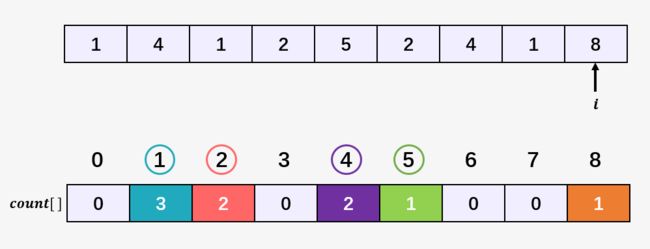
此时遍历数组 [1,4,1,2,5,2,4,1,8] 结束,我们得到了一个 count[] 数组,而只要得到了这个count[] 数组,我们的排序算法就相当于结束了,接下来的就只是输出了。
如果不考虑计数排序的稳定性,我们按照数组 count[] 中对应下标的出现次数直接输出即可:
for(int i = 0; i < count.length; i++){
if (count[i] != 0){
for(int j = 0; j < count[i]; j++){
System.out.print(i + " ");
}
}
}
为了保证计数排序的稳定性,我们又该如何做呢?
先不考虑这么复杂,但是从宏观的角度来看,我们的目的就是找到待排序数组中每一个元素在排序后数组当中的正确位置。
首先看一下 count[] 数组本身, 数组中的 0 对于我们的输出没有任何影响,所以我们可以考虑将其直接去掉:
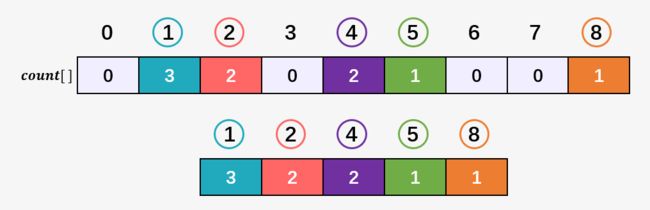
那么此时的我们就可根据去掉之后的数组得到排序后数组的一个轮廓图:
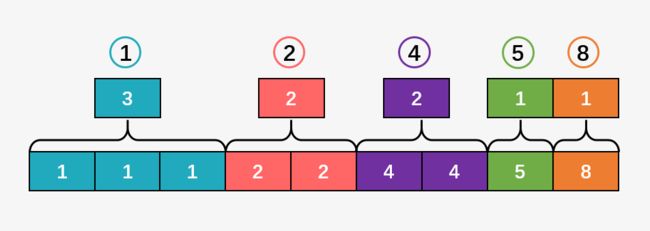
但是这样我们并不知道相同的数字在对应原始数组 arr[] 中的哪一个元素,就相当于直接输出,而没有考虑元素的相对顺序;但是对这个过程的理解有助于我们接下来理解稳定性的处理过程。
我们看到,数组 count[] 中的每一个值表示它所对应的下标在排序后数组的出现次数,那么我们遍历数组(下标从 1 开始),并对数组 count[] 中的每一个元素执行 count[i] = count[i] + count[i-1] 会得到什么呢?
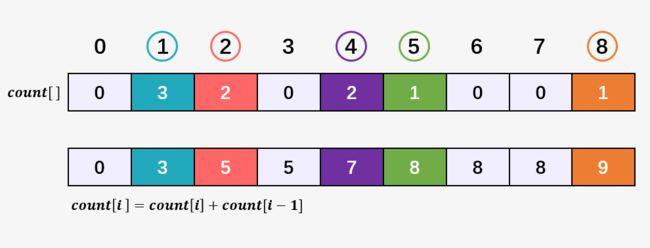
此时得到新的 count[] 将表示他们的位置信息,比如 3 表示它的下标 1 一定出现在前 3 的位置;而紧接其后 5 则表示下标 2 出现在第 4 和第 5 个位置;下标为 3 的 count[3] = 5 ,其与前面的 count[2] 值相同,两者之差也就表示其出现次数,0 次,所以不占位置;下标为 4 的位置值为 7 ,则表示下标 4 出现在第 6 和 7 的位置,依次类推,你也可以对新的 count[] 数组中的每一个元素做出解释。
但我们怎么可能停留在这里呢?
有了这个新的 count[] 数组,我们如何得到元素数组 arr[] 在排序后的输出数组 output[] 中的正确位置呢?
回答了这个问题,稳定的计数排序也就彻底理解了~~
第一步:从后向前遍历,具体为什么是从后向前,看完了你就会明白了!首先是 i = n-1 = 8 ,然后计算出 arr[i] = arr[8] = 8 在排序后数组的正确位置 count[arr[i]] - 1 = count[8] - 1 = 8 ,即排序后 arr[8] 的正确位置为 8 ,然后将 arr[8] 赋值给 output[8] = 8,但是 count[arr[8]] = count[8] 减 1 :
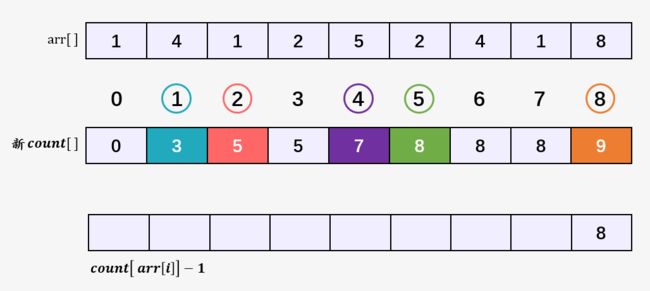
第二步:i = n - 2 = 7 ,然后计算 arr[7] = 1 在排序后数组的正确位置 count[arr[7]] - 1 = count[1] - 1 = 2 ,即最后一个 1 在排序后的正确位置下标为 2 ,然后将 count[arr[7]] 的值减 1 。这里为什么要减 1 ,因为我们已经找到了最后一个 1 的正确位置,目前就剩余两个 1 没有找到正确位置。

以此类推,就可以得到原数组 arr[] 中每一个元素在排序后的正确位置
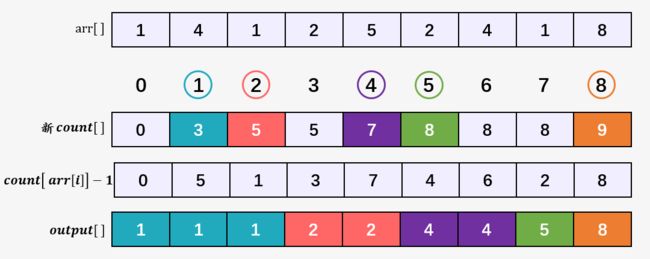
这就是稳定的计数排序,那我们再来回答一下为什么从后向前遍历新的 count[] 数组?
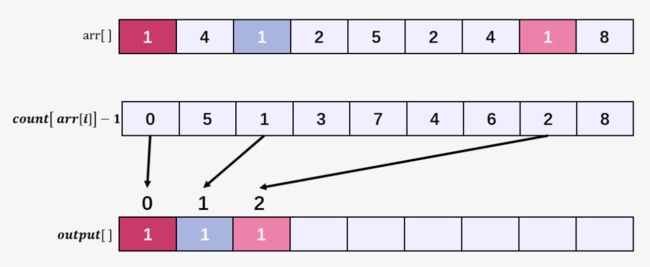
因为只有这样才能保证计数排序的稳定性!比如原始数组 arr[] 中 3 个 1 的在排序后的相对位置就没有发生变化,依旧保持:
实现代码
public class CountingSort {
public void countingSort(int arr[]) {
int n = arr.length;
int output[] = new int[n];
int count[] = new int[256];
for(int i = 0; i < 256; i++) {
count[i] = 0;
}
for(int i = 0; i < n; i++) {
++count[arr[i]];
}
for(int i = 1; i <= 255; i++) {
count[i] += count[i-1];
}
for(int i = n-1; i >= 0; i--) {
output[count[arr[i]] - 1] = arr[i];
--count[arr[i]];
}
for(int i = 0; i < n; i++) {
arr[i] = output[i];
}
}
public static void main(String args[]) {
CountingSort os = new CountingSort();
int arr[] = {1,4,1,2,5,2,4,1,8};
os.countingSort(arr);
for(int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + ",");
}
}
}
可是问题又来了,如果我们的数组变成了 arr[] = {-1,4,1,-2,5,-2,4,-1,8} ,上面介绍的计数排序的实现方式不就出现了问题吗?因为数组下标也没有负数的情况呀!


我们只需要找到数组 arr[] = {-1,4,1,-2,5,-2,4,-1,8} 中的最小值 min = -2 ,以及最大值 max = 8 ,然后开辟一个大小为 max - min + 1 的 count[] 数组,统计出数组当中每一个元素出现的次数即可,就像下面这样:
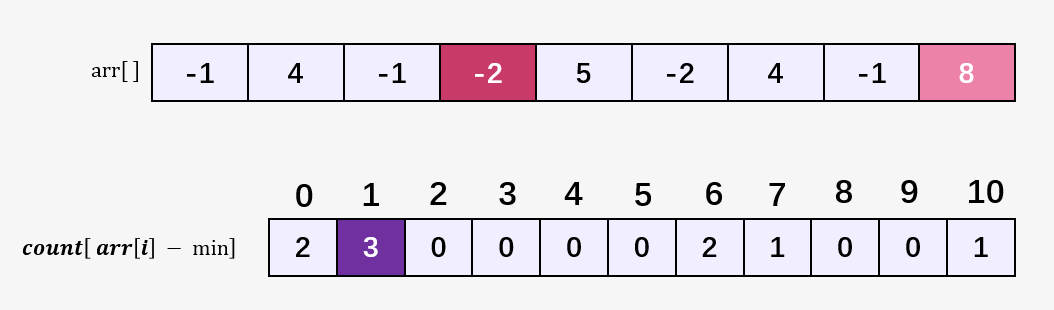
其中数组 arr[] 的最小值 min = -2 ,-2 被映射到了 count[] 数组下标为 0 的位置,原数组中包含 2 个 -2 ,所以 count[0] = 2 ;原数组 arr[] 当中有 3 个 -1 ,其中 -1 - (-2) = 1 ,也就说 -1 映射到了 count[] 数组下表为 1 的位置,所以 count[1] = 3 .
得到了 count[] 数组,之后的操作还不简单吗?记得自己调试一下奥!!!
改进的计数排序实现:
import java.util.*;
class CountingSort
{
static void countSort(int[] arr)
{
int max = Arrays.stream(arr).max().getAsInt();
int min = Arrays.stream(arr).min().getAsInt();
int range = max - min + 1;
int count[] = new int[range];
int output[] = new int[arr.length];
for (int i = 0; i < arr.length; i++)
{
count[arr[i] - min]++;
}
for (int i = 1; i < count.length; i++)
{
count[i] += count[i - 1];
}
for (int i = arr.length - 1; i >= 0; i--)
{
output[count[arr[i] - min] - 1] = arr[i];
count[arr[i] - min]--;
}
for (int i = 0; i < arr.length; i++)
{
arr[i] = output[i];
}
}
static void printArray(int[] arr)
{
for (int i = 0; i < arr.length; i++)
{
System.out.print(arr[i] + " ");
}
System.out.println("");
}
public static void main(String[] args)
{
int[] arr = {-1,4,1,-2,5,-2,4,-1,8};
countSort(arr);
printArray(arr);
}
}
复杂度分析
时间复杂度
在整个代码实现过程中,我们仅仅出现了一层的 for 循环,没有出现任何 for 循环的嵌套,所以计数排序的时间复杂度为 量级。
空间复杂度
由于计数排序过程中,我们使用到了一个 max - min + 1 大小的 count[] 数组,所以计数排序的空间复杂度为 量级。
优缺点分析
如果输入数据的范围
range = max - min + 1不明显大于要待排序数组的长度n = arr.length,则计数排序是相当高效的,比时间复杂度为 的快速和归并排序都优秀。计数排序不是基于比较的排序算法,时间复杂度为 ,空间复杂度与数据范围成正比。
计数排序通常用作另一个排序算法(例如基数排序)的子过程。
计数排序可以使用部分哈希(partial Hashing)在 的时间内统计数据的频率。
计数排序适用于负输入。
计数排序不适用于小数的情况。
最后再强烈推荐一下之前推荐 过的一个网站:https://visualgo.net/en/sorting?slide=1 !一定对你学习排序算法有帮助~~
推荐阅读:
图解「归并排序」算法(修订版)
漫画:什么是树状数组?
图解:什么是AVL树?
作者:景禹,一个追求极致的共享主义者,想带你一起拥有更美好的生活,化作你的一把伞。